 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Text Classification Under Class Distribution Shift
Paper and Code
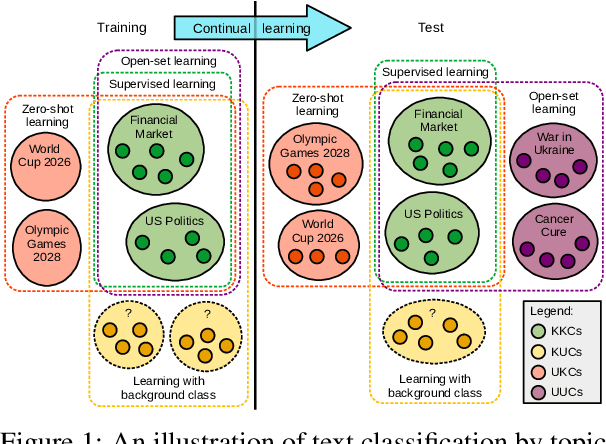

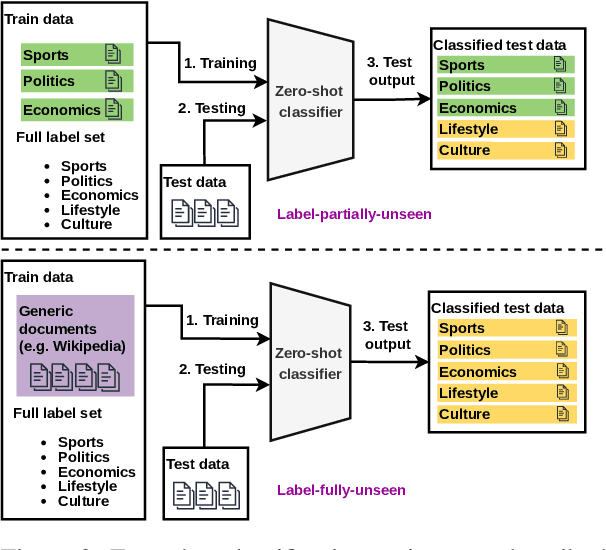
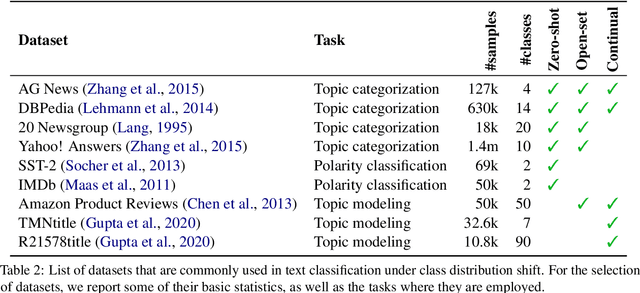
The basic underlying assumption of machine learning (ML) models is that the training and test data are sampled from the same distribution. However, in daily practice, this assumption is often broken, i.e.~the distribution of the test data changes over time, which hinders the application of conventional ML models. One domain where the distribution shift naturally occurs is text classification, since people always find new topics to discuss. To this end, we survey research articles studying open-set text classification and related tasks. We divide the methods in this area based on the constraints that define the kind of distribution shift and the corresponding problem formulation, i.e.~learning with the Universum, zero-shot learning, and open-set learning. We next discuss the predominant mitigation approaches for each problem setup. Finally, we identify several future work directions, aiming to push the boundaries beyond the state of the art. Interestingly, we find that continual learning can solve many of the issues caused by the shifting class distribution. We maintain a list of relevant papers at https://github.com/Eduard6421/Open-Set-Survey.