 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVOS-DD: Multilingual Audio-Video Open-Set Deepfake Detection Benchmark
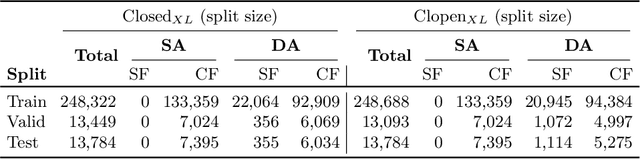
May 16, 2025We present the first large-scale open-set benchmark for multilingual audio-video deepfake detection. Our dataset comprises over 250 hours of real and fake videos across eight languages, with 60% of data being generated. For each language, the fake videos are generated with seven distinct deepfake generation models, selected based on the quality of the generated content. We organize the training, validation and test splits such that only a subset of the chosen generative models and languages are available during training, thus creating several challenging open-set evaluation setups. We perform experiments with various pre-trained and fine-tuned deepfake detectors proposed in recent literature. Our results show that state-of-the-art detectors are not currently able to maintain their performance levels when tested in our open-set scenarios. We publicly release our data and code at: https://huggingface.co/datasets/unibuc-cs/MAVOS-DD.
Deepfake Media Generation and Detection in the Generative AI Era: A Survey and Outlook
Nov 29, 2024



With the recent advancements in generative modeling, the realism of deepfake content has been increasing at a steady pace, even reaching the point where people often fail to detect manipulated media content online, thus being deceived into various kinds of scams. In this paper, we survey deepfake generation and detection techniques, including the most recent developments in the field, such as diffusion models and Neural Radiance Fields. Our literature review covers all deepfake media types, comprising image, video, audio and multimodal (audio-visual) content. We identify various kinds of deepfakes, according to the procedure used to alter or generate the fake content. We further construct a taxonomy of deepfake generation and detection methods, illustrating the important groups of methods and the domains where these methods are applied. Next, we gather datasets used for deepfake detection and provide updated rankings of the best performing deepfake detectors on the most popular datasets. In addition, we develop a novel multimodal benchmark to evaluate deepfake detectors on out-of-distribution content. The results indicate that state-of-the-art detectors fail to generalize to deepfake content generated by unseen deepfake generators. Finally, we propose future directions to obtain robust and powerful deepfake detectors. Our project page and new benchmark are available at https://github.com/CroitoruAlin/biodeep.
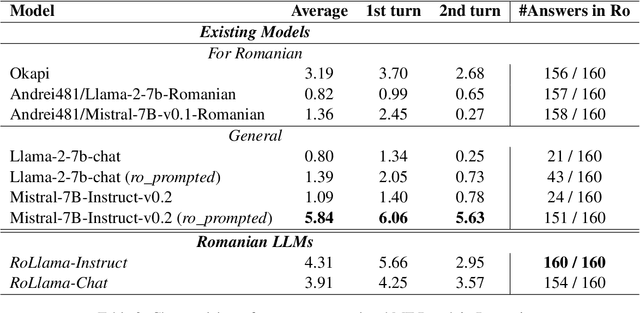
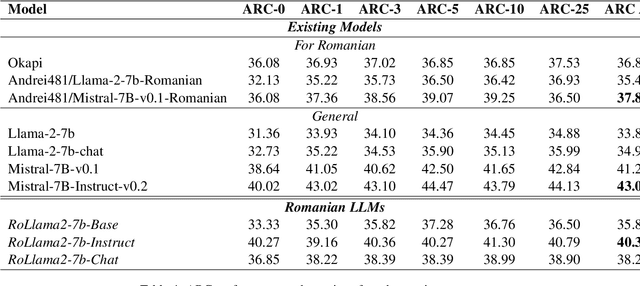
"Vorbeşti Româneşte?" A Recipe to Train Powerful Romanian LLMs with English Instructions
Jun 26, 2024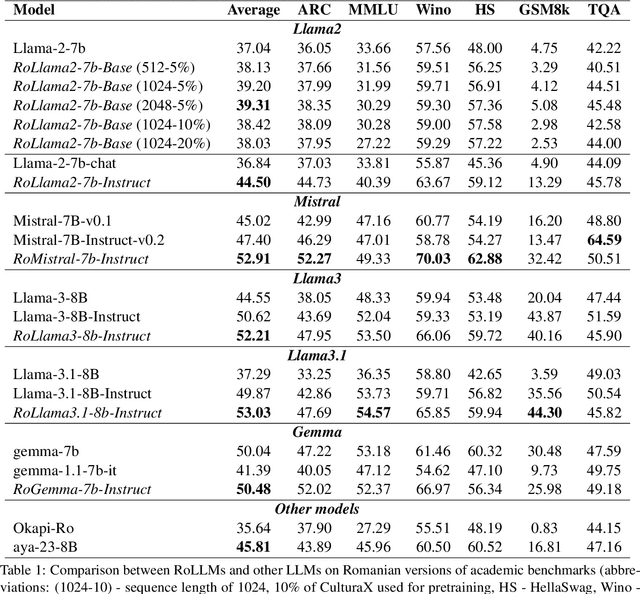
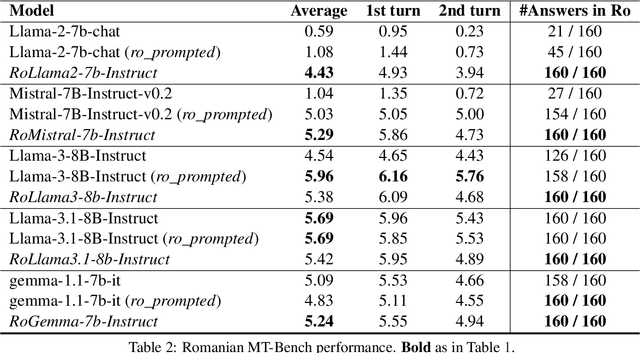
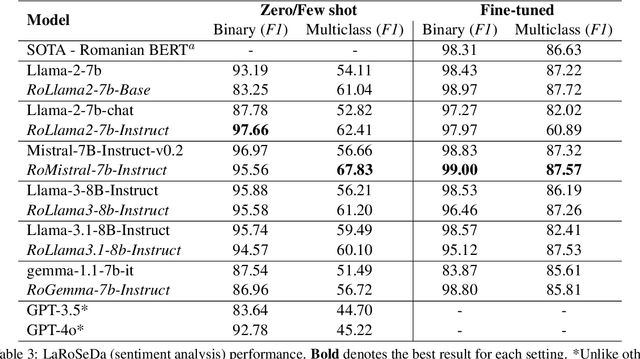
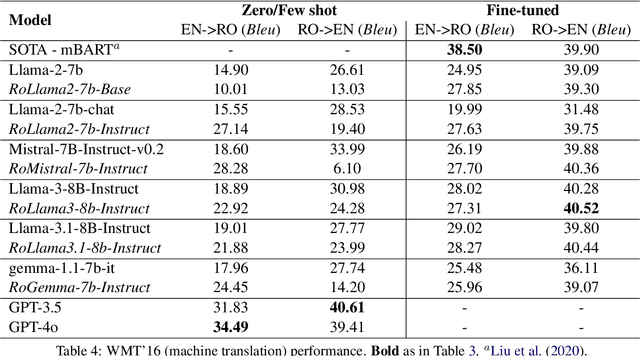
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English; hence, their performance in English greatly exceeds other languages. To our knowledge, we are the first to collect and translate a large collection of texts, instructions, and benchmarks and train, evaluate, and release open-source LLMs tailored for Romanian. We evaluate our methods on four different categories, including academic benchmarks, MT-Bench (manually translated), and a professionally built historical, cultural, and social benchmark adapted to Romanian. We argue for the usefulness and high performance of RoLLMs by obtaining state-of-the-art results across the board. We publicly release all resources (i.e., data, training and evaluation code, models) to support and encourage research on Romanian LLMs while concurrently creating a generalizable recipe, adequate for other low or less-resourced languages.
OpenLLM-Ro -- Technical Report on Open-source Romanian LLMs
May 17, 2024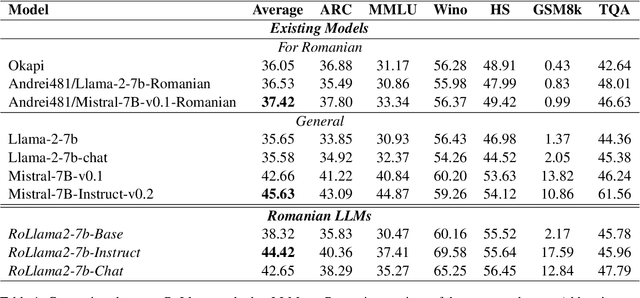

In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English. Hence, their performance in English greatly exceeds their performance in other languages. This document presents our approach to training and evaluating the first foundational and chat LLM specialized for Romanian.
Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
Jun 21, 2023



We propose an efficient abnormal event detection model based on a lightweight masked auto-encoder (AE) applied at the video frame level. The novelty of the proposed model is threefold. First, we introduce an approach to weight tokens based on motion gradients, thus avoiding learning to reconstruct the static background scene. Second, we integrate a teacher decoder and a student decoder into our architecture, leveraging the discrepancy between the outputs given by the two decoders to improve anomaly detection. Third, we generate synthetic abnormal events to augment the training videos, and task the masked AE model to jointly reconstruct the original frames (without anomalies) and the corresponding pixel-level anomaly maps. Our design leads to an efficient and effective model, as demonstrated by the extensive experiments carried out on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. The empirical results show that our model achieves an excellent trade-off between speed and accuracy, obtaining competitive AUC scores, while processing 1670 FPS. Hence, our model is between 8 and 70 times faster than competing methods. We also conduct an ablation study to justify our design.
VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web
Jul 07, 2022
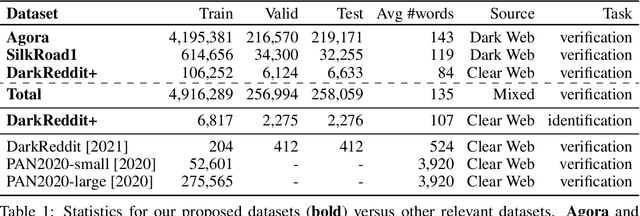
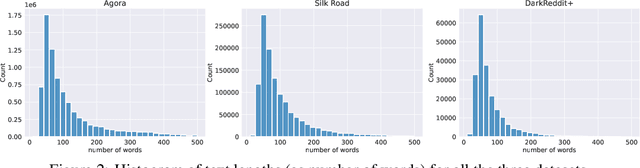
The DarkWeb represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark
Self-paced learning to improve text row detection in historical documents with missing labels
Feb 02, 2022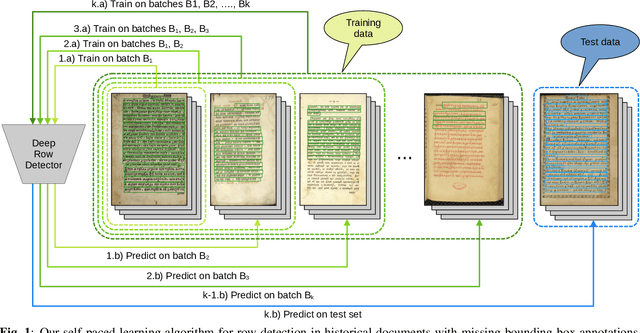
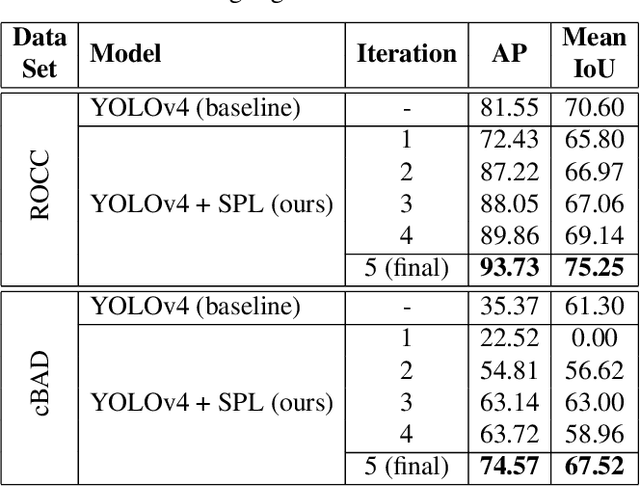

An important preliminary step of optical character recognition systems is the detection of text rows. To address this task in the context of historical data with missing labels, we propose a self-paced learning algorithm capable of improving the row detection performance. We conjecture that pages with more ground-truth bounding boxes are less likely to have missing annotations. Based on this hypothesis, we sort the training examples in descending order with respect to the number of ground-truth bounding boxes, and organize them into k batches. Using our self-paced learning method, we train a row detector over k iterations, progressively adding batches with less ground-truth annotations. At each iteration, we combine the ground-truth bounding boxes with pseudo-bounding boxes (bounding boxes predicted by the model itself) using non-maximum suppression, and we include the resulting annotations at the next training iteration. We demonstrate that our self-paced learning strategy brings significant performance gains on two data sets of historical documents, improving the average precision of YOLOv4 with more than 12% on one data set and 39% on the other.
Transferring BERT-like Transformers' Knowledge for Authorship Verification
Dec 09, 2021


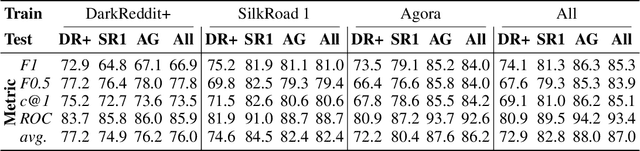
The task of identifying the author of a text spans several decades and was tackled using linguistics, statistics, and, more recently, machine learning. Inspired by the impressive performance gains across a broad range of natural language processing tasks and by the recent availability of the PAN large-scale authorship dataset, we first study the effectiveness of several BERT-like transformers for the task of authorship verification. Such models prove to achieve very high scores consistently. Next, we empirically show that they focus on topical clues rather than on author writing style characteristics, taking advantage of existing biases in the dataset. To address this problem, we provide new splits for PAN-2020, where training and test data are sampled from disjoint topics or authors. Finally, we introduce DarkReddit, a dataset with a different input data distribution. We further use it to analyze the domain generalization performance of models in a low-data regime and how performance varies when using the proposed PAN-2020 splits for fine-tuning. We show that those splits can enhance the models' capability to transfer knowledge over a new, significantly different dataset.
A realistic approach to generate masked faces applied on two novel masked face recognition data sets
Sep 03, 2021
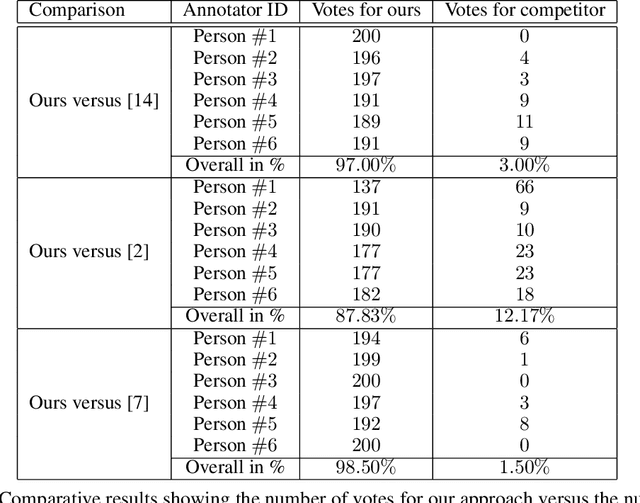

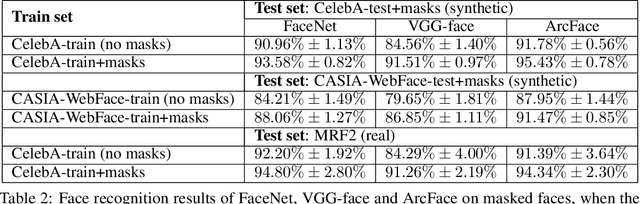
The COVID-19 pandemic raises the problem of adapting face recognition systems to the new reality, where people may wear surgical masks to cover their noses and mouths. Traditional data sets (e.g., CelebA, CASIA-WebFace) used for training these systems were released before the pandemic, so they now seem unsuited due to the lack of examples of people wearing masks. We propose a method for enhancing data sets containing faces without masks by creating synthetic masks and overlaying them on faces in the original images. Our method relies on Spark AR Studio, a developer program made by Facebook that is used to create Instagram face filters. In our approach, we use 9 masks of different colors, shapes and fabrics. We employ our method to generate a number of 445,446 (90%) samples of masks for the CASIA-WebFace data set and 196,254 (96.8%) masks for the CelebA data set, releasing the mask images at https://github.com/securifai/masked_faces. We show that our method produces significantly more realistic training examples of masks overlaid on faces by asking volunteers to qualitatively compare it to other methods or data sets designed for the same task. We also demonstrate the usefulness of our method by evaluating state-of-the-art face recognition systems (FaceNet, VGG-face, ArcFace) trained on the enhanced data sets and showing that they outperform equivalent systems trained on the original data sets (containing faces without masks), when the test benchmark contains masked faces.
EvoBA: An Evolution Strategy as a Strong Baseline forBlack-Box Adversarial Attacks
Jul 12, 2021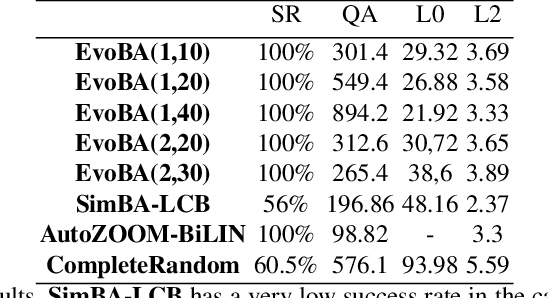
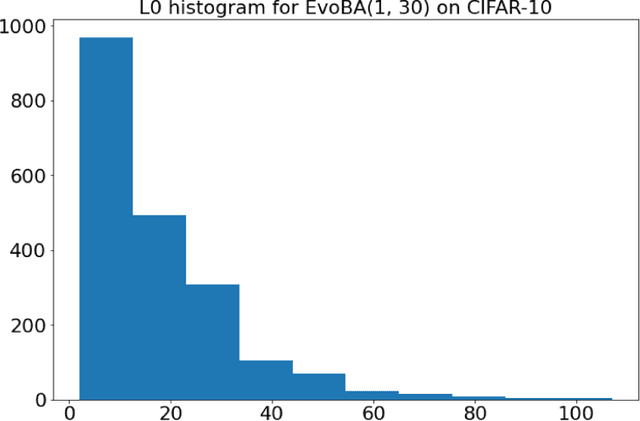
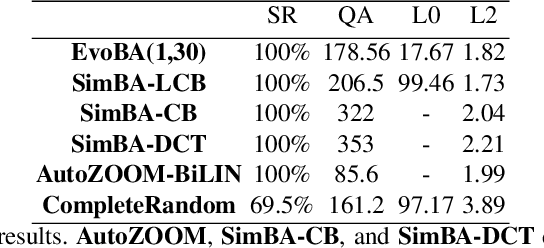
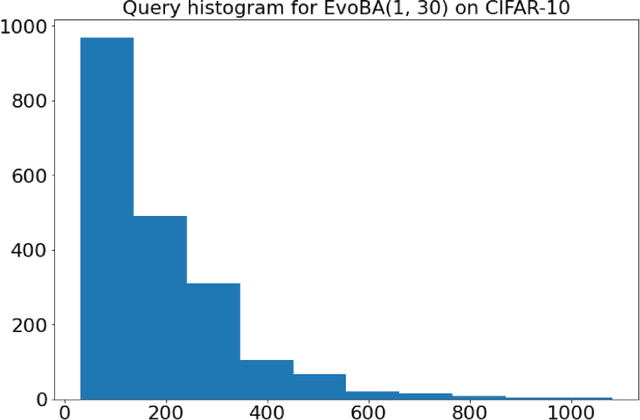
Recent work has shown how easily white-box adversarial attacks can be applied to state-of-the-art image classifiers. However, real-life scenarios resemble more the black-box adversarial conditions, lacking transparency and usually imposing natural, hard constraints on the query budget. We propose $\textbf{EvoBA}$, a black-box adversarial attack based on a surprisingly simple evolutionary search strategy. $\textbf{EvoBA}$ is query-efficient, minimizes $L_0$ adversarial perturbations, and does not require any form of training. $\textbf{EvoBA}$ shows efficiency and efficacy through results that are in line with much more complex state-of-the-art black-box attacks such as $\textbf{AutoZOOM}$. It is more query-efficient than $\textbf{SimBA}$, a simple and powerful baseline black-box attack, and has a similar level of complexity. Therefore, we propose it both as a new strong baseline for black-box adversarial attacks and as a fast and general tool for gaining empirical insight into how robust image classifiers are with respect to $L_0$ adversarial perturbations. There exist fast and reliable $L_2$ black-box attacks, such as $\textbf{SimBA}$, and $L_{\infty}$ black-box attacks, such as $\textbf{DeepSearch}$. We propose $\textbf{EvoBA}$ as a query-efficient $L_0$ black-box adversarial attack which, together with the aforementioned methods, can serve as a generic tool to assess the empirical robustness of image classifiers. The main advantages of such methods are that they run fast, are query-efficient, and can easily be integrated in image classifiers development pipelines. While our attack minimises the $L_0$ adversarial perturbation, we also report $L_2$, and notice that we compare favorably to the state-of-the-art $L_2$ black-box attack, $\textbf{AutoZOOM}$, and of the $L_2$ strong baseline, $\textbf{SimBA}$.