 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Cross-Modal Transformer for Audio-Textual Classification
Jan 15, 2024



Speech classification tasks often require powerful language understanding models to grasp useful features, which becomes problematic when limited training data is available. To attain superior classification performance, we propose to harness the inherent value of multimodal representations by transcribing speech using automatic speech recognition (ASR) models and translating the transcripts into different languages via pretrained translation models. We thus obtain an audio-textual (multimodal) representation for each data sample. Subsequently, we combine language-specific Bidirectional Encoder Representations from Transformers (BERT) with Wav2Vec2.0 audio features via a novel cascaded cross-modal transformer (CCMT). Our model is based on two cascaded transformer blocks. The first one combines text-specific features from distinct languages, while the second one combines acoustic features with multilingual features previously learned by the first transformer block. We employed our system in the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge. CCMT was declared the winning solution, obtaining an unweighted average recall (UAR) of 65.41% and 85.87% for complaint and request detection, respectively. Moreover, we applied our framework on the Speech Commands v2 and HarperValleyBank dialog data sets, surpassing previous studies reporting results on these benchmarks. Our code is freely available for download at: https://github.com/ristea/ccmt.
ICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023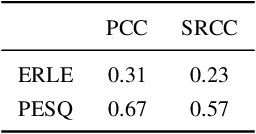
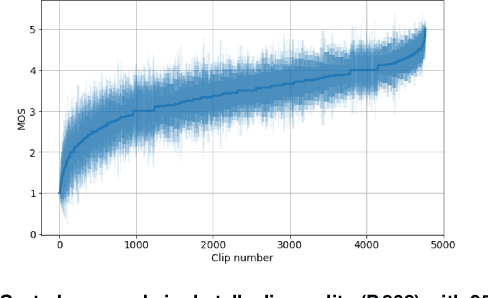

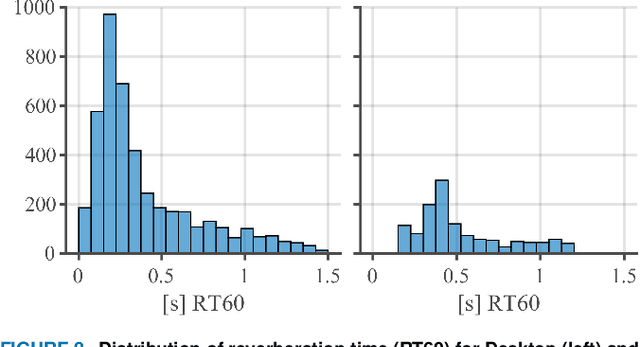
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
Multi-dimensional Speech Quality Assessment in Crowdsourcing
Sep 14, 2023Subjective speech quality assessment is the gold standard for evaluating speech enhancement processing and telecommunication systems. The commonly used standard ITU-T Rec. P.800 defines how to measure speech quality in lab environments, and ITU-T Rec.~P.808 extended it for crowdsourcing. ITU-T Rec. P.835 extends P.800 to measure the quality of speech in the presence of noise. ITU-T Rec. P.804 targets the conversation test and introduces perceptual speech quality dimensions which are measured during the listening phase of the conversation. The perceptual dimensions are noisiness, coloration, discontinuity, and loudness. We create a crowdsourcing implementation of a multi-dimensional subjective test following the scales from P.804 and extend it to include reverberation, the speech signal, and overall quality. We show the tool is both accurate and reproducible. The tool has been used in the ICASSP 2023 Speech Signal Improvement challenge and we show the utility of these speech quality dimensions in this challenge. The tool will be publicly available as open-source at https://github.com/microsoft/P.808.
RoDia: A New Dataset for Romanian Dialect Identification from Speech
Sep 12, 2023



Dialect identification is a critical task in speech processing and language technology, enhancing various applications such as speech recognition, speaker verification, and many others. While most research studies have been dedicated to dialect identification in widely spoken languages, limited attention has been given to dialect identification in low-resource languages, such as Romanian. To address this research gap, we introduce RoDia, the first dataset for Romanian dialect identification from speech. The RoDia dataset includes a varied compilation of speech samples from five distinct regions of Romania, covering both urban and rural environments, totaling 2 hours of manually annotated speech data. Along with our dataset, we introduce a set of competitive models to be used as baselines for future research. The top scoring model achieves a macro F1 score of 59.83% and a micro F1 score of 62.08%, indicating that the task is challenging. We thus believe that RoDia is a valuable resource that will stimulate research aiming to address the challenges of Romanian dialect identification. We publicly release our dataset and code at https://github.com/codrut2/RoDia.
CL-MAE: Curriculum-Learned Masked Autoencoders
Aug 31, 2023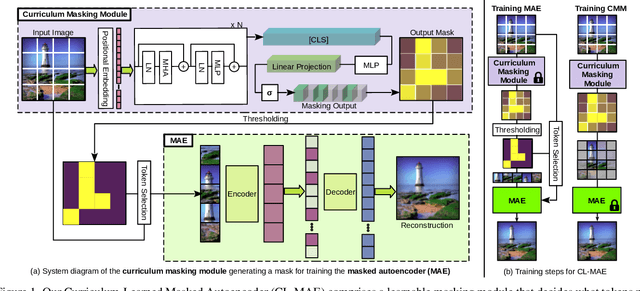
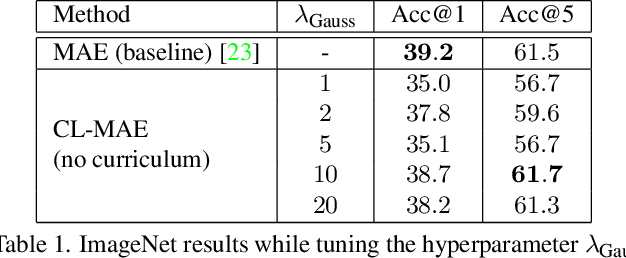
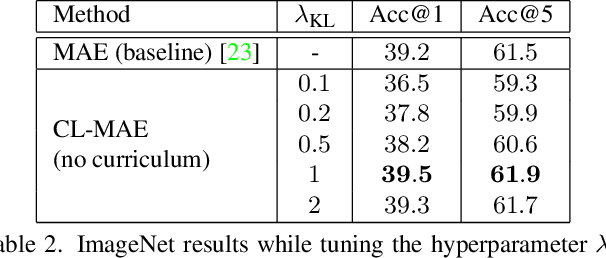

Masked image modeling has been demonstrated as a powerful pretext task for generating robust representations that can be effectively generalized across multiple downstream tasks. Typically, this approach involves randomly masking patches (tokens) in input images, with the masking strategy remaining unchanged during training. In this paper, we propose a curriculum learning approach that updates the masking strategy to continually increase the complexity of the self-supervised reconstruction task. We conjecture that, by gradually increasing the task complexity, the model can learn more sophisticated and transferable representations. To facilitate this, we introduce a novel learnable masking module that possesses the capability to generate masks of different complexities, and integrate the proposed module into masked autoencoders (MAE). Our module is jointly trained with the MAE, while adjusting its behavior during training, transitioning from a partner to the MAE (optimizing the same reconstruction loss) to an adversary (optimizing the opposite loss), while passing through a neutral state. The transition between these behaviors is smooth, being regulated by a factor that is multiplied with the reconstruction loss of the masking module. The resulting training procedure generates an easy-to-hard curriculum. We train our Curriculum-Learned Masked Autoencoder (CL-MAE) on ImageNet and show that it exhibits superior representation learning capabilities compared to MAE. The empirical results on five downstream tasks confirm our conjecture, demonstrating that curriculum learning can be successfully used to self-supervise masked autoencoders.
Cascaded Cross-Modal Transformer for Request and Complaint Detection
Jul 27, 2023



We propose a novel cascaded cross-modal transformer (CCMT) that combines speech and text transcripts to detect customer requests and complaints in phone conversations. Our approach leverages a multimodal paradigm by transcribing the speech using automatic speech recognition (ASR) models and translating the transcripts into different languages. Subsequently, we combine language-specific BERT-based models with Wav2Vec2.0 audio features in a novel cascaded cross-attention transformer model. We apply our system to the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge, reaching unweighted average recalls (UAR) of 65.41% and 85.87% for the complaint and request classes, respectively.
Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
Jun 21, 2023



We propose an efficient abnormal event detection model based on a lightweight masked auto-encoder (AE) applied at the video frame level. The novelty of the proposed model is threefold. First, we introduce an approach to weight tokens based on motion gradients, thus avoiding learning to reconstruct the static background scene. Second, we integrate a teacher decoder and a student decoder into our architecture, leveraging the discrepancy between the outputs given by the two decoders to improve anomaly detection. Third, we generate synthetic abnormal events to augment the training videos, and task the masked AE model to jointly reconstruct the original frames (without anomalies) and the corresponding pixel-level anomaly maps. Our design leads to an efficient and effective model, as demonstrated by the extensive experiments carried out on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. The empirical results show that our model achieves an excellent trade-off between speed and accuracy, obtaining competitive AUC scores, while processing 1670 FPS. Hence, our model is between 8 and 70 times faster than competing methods. We also conduct an ablation study to justify our design.
Sea Ice Segmentation From SAR Data by Convolutional Transformer Networks
Jun 13, 2023


Sea ice is a crucial component of the Earth's climate system and is highly sensitive to changes in temperature and atmospheric conditions. Accurate and timely measurement of sea ice parameters is important for understanding and predicting the impacts of climate change. Nevertheless, the amount of satellite data acquired over ice areas is huge, making the subjective measurements ineffective. Therefore, automated algorithms must be used in order to fully exploit the continuous data feeds coming from satellites. In this paper, we present a novel approach for sea ice segmentation based on SAR satellite imagery using hybrid convolutional transformer (ConvTr) networks. We show that our approach outperforms classical convolutional networks, while being considerably more efficient than pure transformer models. ConvTr obtained a mean intersection over union (mIoU) of 63.68% on the AI4Arctic data set, assuming an inference time of 120ms for a 400 x 400 squared km product.
DeepVQE: Real Time Deep Voice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation
Jun 05, 2023


Acoustic echo cancellation (AEC), noise suppression (NS) and dereverberation (DR) are an integral part of modern full-duplex communication systems. As the demand for teleconferencing systems increases, addressing these tasks is required for an effective and efficient online meeting experience. Most prior research proposes solutions for these tasks separately, combining them with digital signal processing (DSP) based components, resulting in complex pipelines that are often impractical to deploy in real-world applications. This paper proposes a real-time cross-attention deep model, named DeepVQE, based on residual convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to simultaneously address AEC, NS, and DR. We conduct several ablation studies to analyze the contributions of different components of our model to the overall performance. DeepVQE achieves state-of-the-art performance on non-personalized tracks from the ICASSP 2023 Acoustic Echo Cancellation Challenge and ICASSP 2023 Deep Noise Suppression Challenge test sets, showing that a single model can handle multiple tasks with excellent performance. Moreover, the model runs in real-time and has been successfully tested for the Microsoft Teams platform.
Lightning Fast Video Anomaly Detection via Adversarial Knowledge Distillation
Nov 28, 2022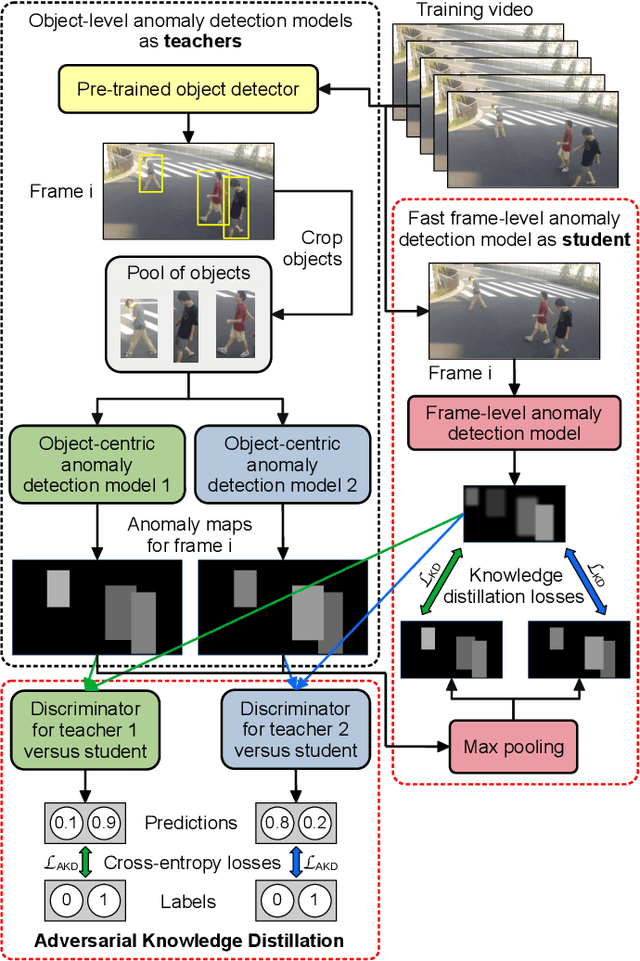
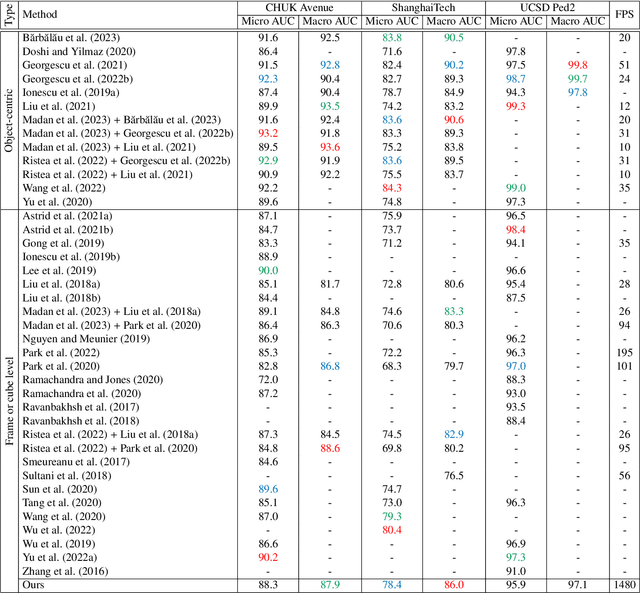
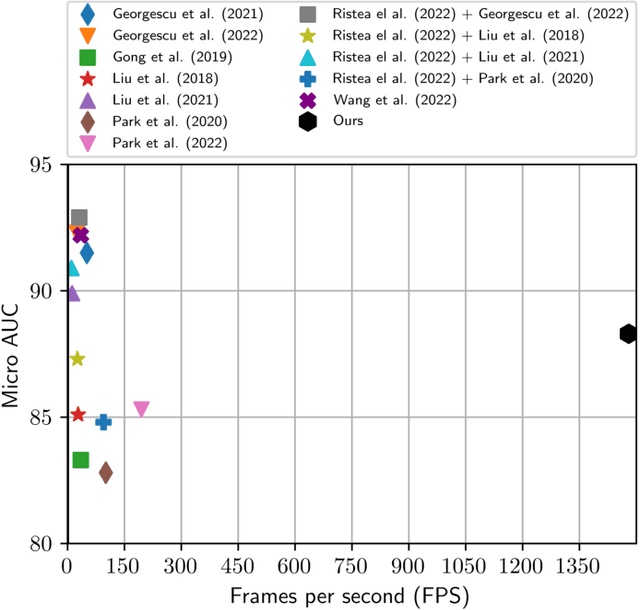
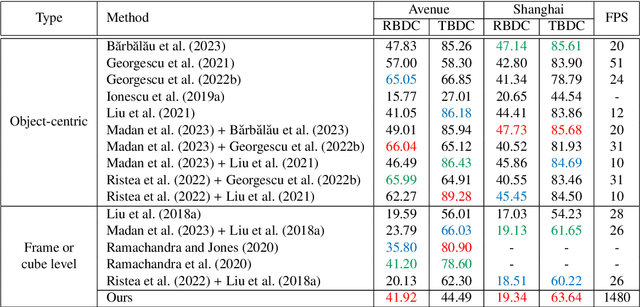
We propose a very fast frame-level model for anomaly detection in video, which learns to detect anomalies by distilling knowledge from multiple highly accurate object-level teacher models. To improve the fidelity of our student, we distill the low-resolution anomaly maps of the teachers by jointly applying standard and adversarial distillation, introducing an adversarial discriminator for each teacher to distinguish between target and generated anomaly maps. We conduct experiments on three benchmarks (Avenue, ShanghaiTech, UCSD Ped2), showing that our method is over 7 times faster than the fastest competing method, and between 28 and 62 times faster than object-centric models, while obtaining comparable results to recent methods. Our evaluation also indicates that our model achieves the best trade-off between speed and accuracy, due to its previously unheard-of speed of 1480 FPS. In addition, we carry out a comprehensive ablation study to justify our architectural design choices.