 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICME 2025 Grand Challenge on Video Super-Resolution for Video Conferencing
Jun 13, 2025Super-Resolution (SR) is a critical task in computer vision, focusing on reconstructing high-resolution (HR) images from low-resolution (LR) inputs. The field has seen significant progress through various challenges, particularly in single-image SR. Video Super-Resolution (VSR) extends this to the temporal domain, aiming to enhance video quality using methods like local, uni-, bi-directional propagation, or traditional upscaling followed by restoration. This challenge addresses VSR for conferencing, where LR videos are encoded with H.265 at fixed QPs. The goal is to upscale videos by a specific factor, providing HR outputs with enhanced perceptual quality under a low-delay scenario using causal models. The challenge included three tracks: general-purpose videos, talking head videos, and screen content videos, with separate datasets provided by the organizers for training, validation, and testing. We open-sourced a new screen content dataset for the SR task in this challenge. Submissions were evaluated through subjective tests using a crowdsourced implementation of the ITU-T Rec P.910.
A multidimensional measurement of photorealistic avatar quality of experience
Nov 13, 2024



Photorealistic avatars are human avatars that look, move, and talk like real people. The performance of photorealistic avatars has significantly improved recently based on objective metrics such as PSNR, SSIM, LPIPS, FID, and FVD. However, recent photorealistic avatar publications do not provide subjective tests of the avatars to measure human usability factors. We provide an open source test framework to subjectively measure photorealistic avatar performance in ten dimensions: realism, trust, comfortableness using, comfortableness interacting with, appropriateness for work, creepiness, formality, affinity, resemblance to the person, and emotion accuracy. We show that the correlation of nine of these subjective metrics with PSNR, SSIM, LPIPS, FID, and FVD is weak, and moderate for emotion accuracy. The crowdsourced subjective test framework is highly reproducible and accurate when compared to a panel of experts. We analyze a wide range of avatars from photorealistic to cartoon-like and show that some photorealistic avatars are approaching real video performance based on these dimensions. We also find that for avatars above a certain level of realism, eight of these measured dimensions are strongly correlated. In particular, for photorealistic avatars there is a linear relationship between avatar affinity and realism; in other words, there is no uncanny valley effect for photorealistic avatars in the telecommunication scenario. We provide several extensions of this test framework for future work and discuss design implications for telecommunication systems. The test framework is available at https://github.com/microsoft/P.910.
ICASSP 2024 Speech Signal Improvement Challenge
Jan 25, 2024
The ICASSP 2024 Speech Signal Improvement Grand Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. This marks our second challenge, building upon the success from the previous ICASSP 2023 Grand Challenge. We enhance the competition by introducing a dataset synthesizer, enabling all participating teams to start at a higher baseline, an objective metric for our extended P.804 tests, transcripts for the 2023 test set, and we add Word Accuracy (WAcc) as a metric. We evaluate a total of 13 systems in the real-time track and 11 systems in the non-real-time track using both subjective P.804 and objective Word Accuracy metrics.
VCD: A Video Conferencing Dataset for Video Compression
Sep 14, 2023



Commonly used datasets for evaluating video codecs are all very high quality and not representative of video typically used in video conferencing scenarios. We present the Video Conferencing Dataset (VCD) for evaluating video codecs for real-time communication, the first such dataset focused on video conferencing. VCD includes a wide variety of camera qualities and spatial and temporal information. It includes both desktop and mobile scenarios and two types of video background processing. We report the compression efficiency of H.264, H.265, H.266, and AV1 in low-delay settings on VCD and compare it with the non-video conferencing datasets UVC, MLC-JVC, and HEVC. The results show the source quality and the scenarios have a significant effect on the compression efficiency of all the codecs. VCD enables the evaluation and tuning of codecs for this important scenario. The VCD is publicly available as an open-source dataset at https://github.com/microsoft/VCD.
Multi-dimensional Speech Quality Assessment in Crowdsourcing
Sep 14, 2023Subjective speech quality assessment is the gold standard for evaluating speech enhancement processing and telecommunication systems. The commonly used standard ITU-T Rec. P.800 defines how to measure speech quality in lab environments, and ITU-T Rec.~P.808 extended it for crowdsourcing. ITU-T Rec. P.835 extends P.800 to measure the quality of speech in the presence of noise. ITU-T Rec. P.804 targets the conversation test and introduces perceptual speech quality dimensions which are measured during the listening phase of the conversation. The perceptual dimensions are noisiness, coloration, discontinuity, and loudness. We create a crowdsourcing implementation of a multi-dimensional subjective test following the scales from P.804 and extend it to include reverberation, the speech signal, and overall quality. We show the tool is both accurate and reproducible. The tool has been used in the ICASSP 2023 Speech Signal Improvement challenge and we show the utility of these speech quality dimensions in this challenge. The tool will be publicly available as open-source at https://github.com/microsoft/P.808.
Full Reference Video Quality Assessment for Machine Learning-Based Video Codecs
Sep 02, 2023



Machine learning-based video codecs have made significant progress in the past few years. A critical area in the development of ML-based video codecs is an accurate evaluation metric that does not require an expensive and slow subjective test. We show that existing evaluation metrics that were designed and trained on DSP-based video codecs are not highly correlated to subjective opinion when used with ML video codecs due to the video artifacts being quite different between ML and video codecs. We provide a new dataset of ML video codec videos that have been accurately labeled for quality. We also propose a new full reference video quality assessment (FRVQA) model that achieves a Pearson Correlation Coefficient (PCC) of 0.99 and a Spearman's Rank Correlation Coefficient (SRCC) of 0.99 at the model level. We make the dataset and FRVQA model open source to help accelerate research in ML video codecs, and so that others can further improve the FRVQA model.
ICASSP 2023 Speech Signal Improvement Challenge
Apr 02, 2023The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background and overall quality is impressive, but the improvement in the speech signal is statistically zero. To improve the speech signal the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.80's listening phase . The results show significant improvement was made across all measured dimensions of speech quality.
LSTM-based Video Quality Prediction Accounting for Temporal Distortions in Videoconferencing Calls
Mar 22, 2023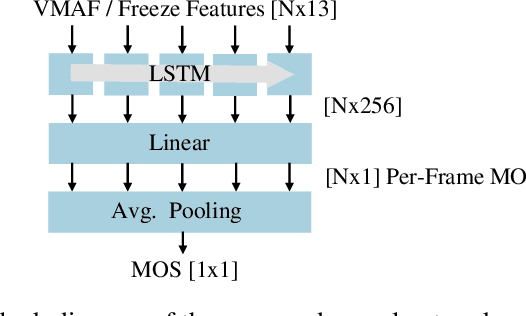
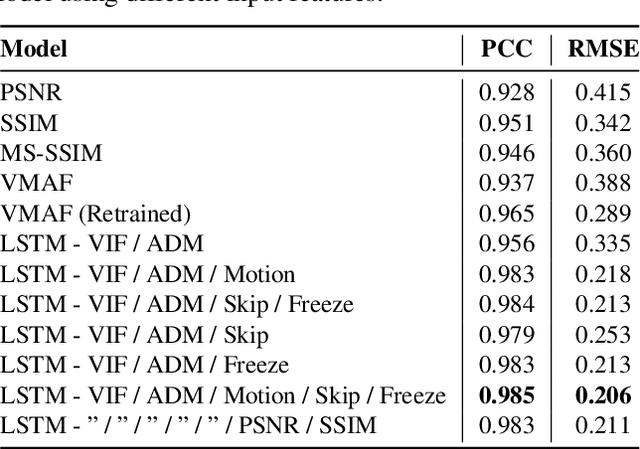
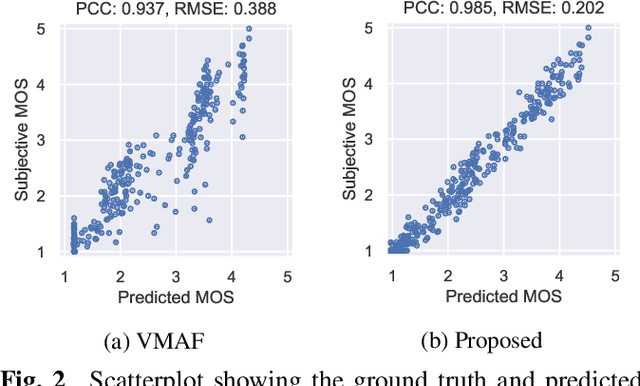
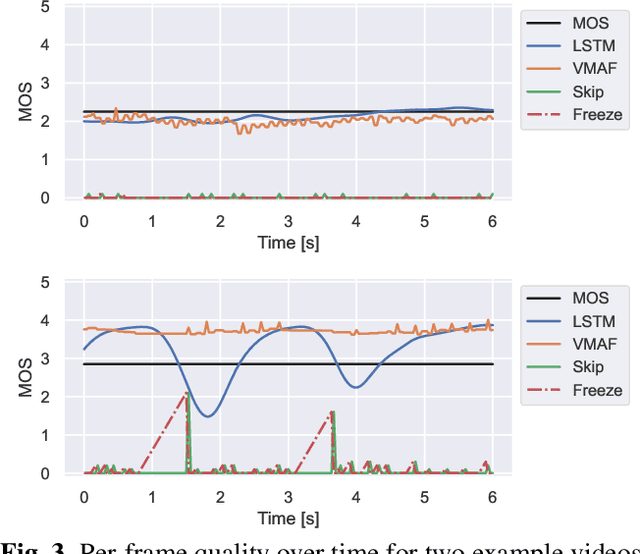
Current state-of-the-art video quality models, such as VMAF, give excellent prediction results by comparing the degraded video with its reference video. However, they do not consider temporal distortions (e.g., frame freezes or skips) that occur during videoconferencing calls. In this paper, we present a data-driven approach for modeling such distortions automatically by training an LSTM with subjective quality ratings labeled via crowdsourcing. The videos were collected from live videoconferencing calls in 83 different network conditions. We applied QR codes as markers on the source videos to create aligned references and compute temporal features based on the alignment vectors. Using these features together with VMAF core features, our proposed model achieves a PCC of 0.99 on the validation set. Furthermore, our model outputs per-frame quality that gives detailed insight into the cause of video quality impairments. The VCM model and dataset are open-sourced at https://github.com/microsoft/Video_Call_MOS.
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
A Transfer Learning Based Model for Text Readability Assessment in German
Jul 13, 2022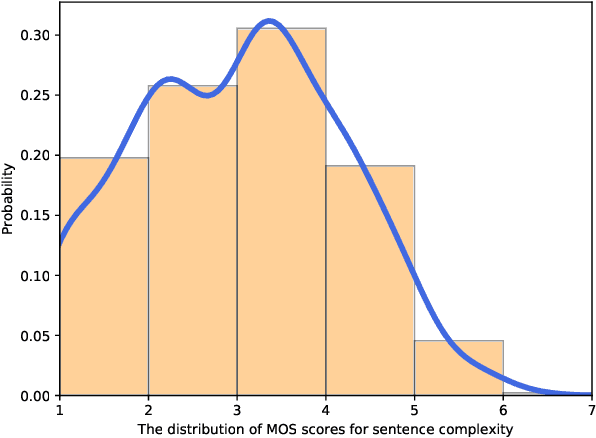
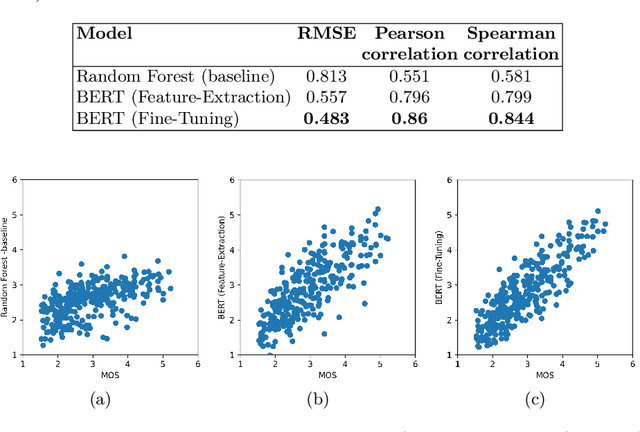
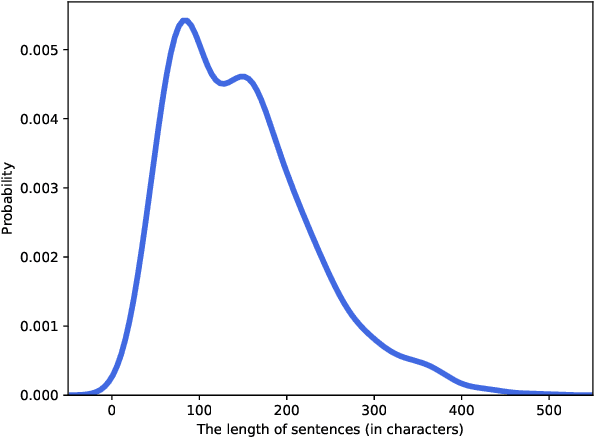
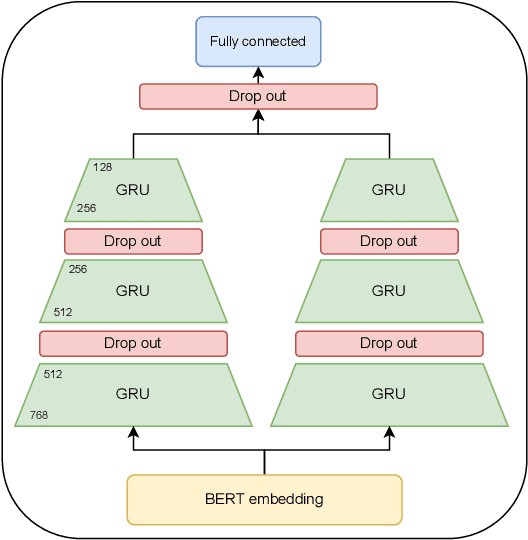
Text readability assessment has a wide range of applications for different target people, from language learners to people with disabilities. The fast pace of textual content production on the web makes it impossible to measure text complexity without the benefit of machine learning and natural language processing techniques. Although various research addressed the readability assessment of English text in recent years, there is still room for improvement of the models for other languages. In this paper, we proposed a new model for text complexity assessment for German text based on transfer learning. Our results show that the model outperforms more classical solutions based on linguistic features extraction from input text. The best model is based on the BERT pre-trained language model achieved the Root Mean Square Error (RMSE) of 0.483.