 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transfer Learning Based Model for Text Readability Assessment in German
Jul 13, 2022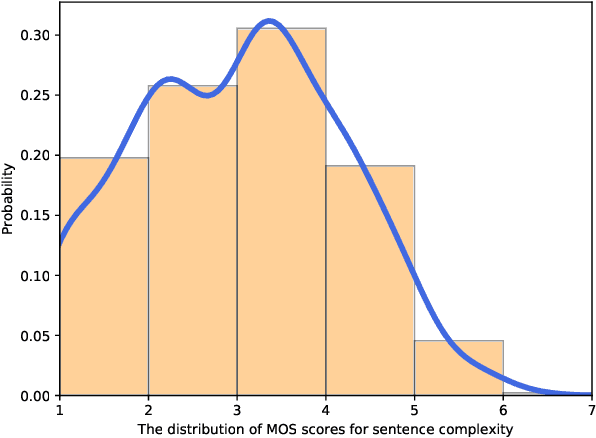
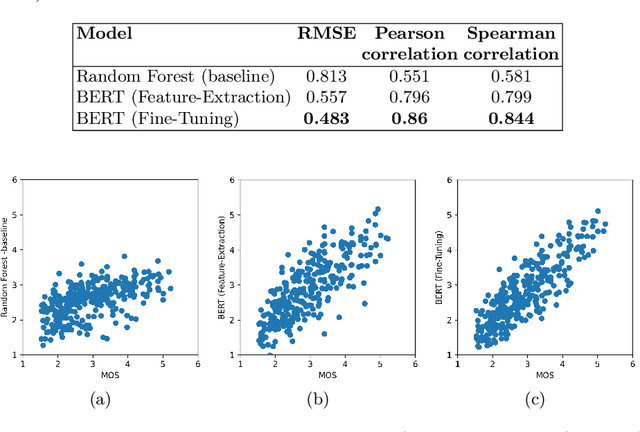
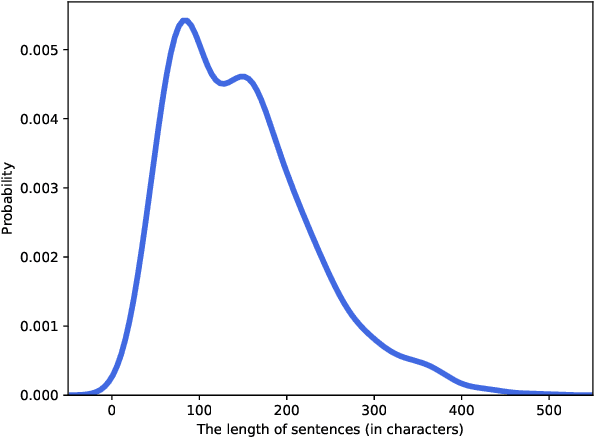
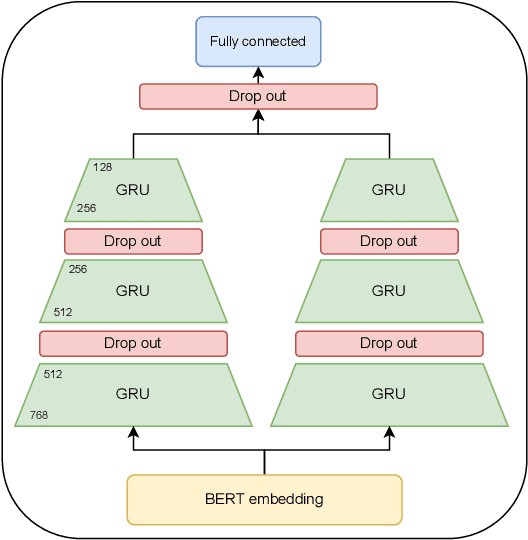
Text readability assessment has a wide range of applications for different target people, from language learners to people with disabilities. The fast pace of textual content production on the web makes it impossible to measure text complexity without the benefit of machine learning and natural language processing techniques. Although various research addressed the readability assessment of English text in recent years, there is still room for improvement of the models for other languages. In this paper, we proposed a new model for text complexity assessment for German text based on transfer learning. Our results show that the model outperforms more classical solutions based on linguistic features extraction from input text. The best model is based on the BERT pre-trained language model achieved the Root Mean Square Error (RMSE) of 0.483.