 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM-based Video Quality Prediction Accounting for Temporal Distortions in Videoconferencing Calls
Paper and Code
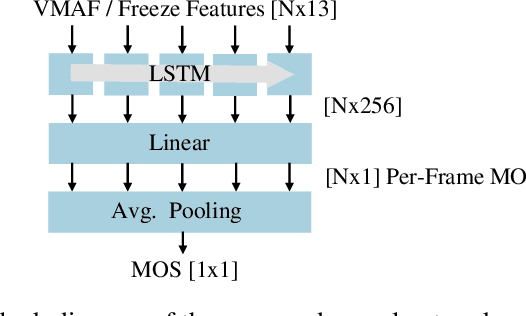
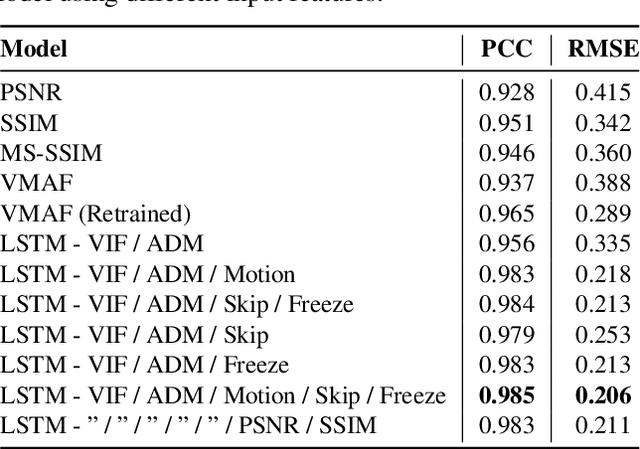
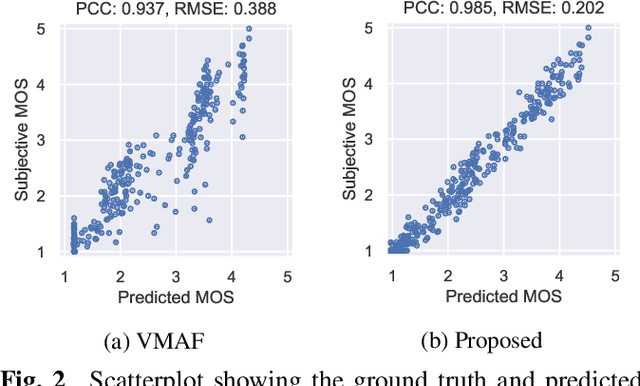
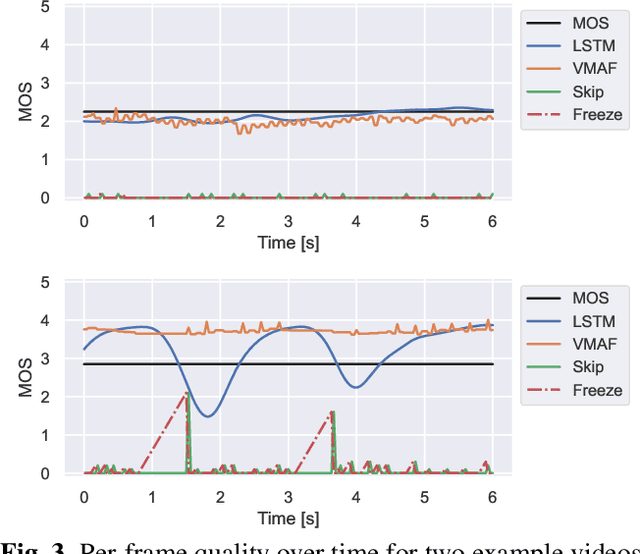
Current state-of-the-art video quality models, such as VMAF, give excellent prediction results by comparing the degraded video with its reference video. However, they do not consider temporal distortions (e.g., frame freezes or skips) that occur during videoconferencing calls. In this paper, we present a data-driven approach for modeling such distortions automatically by training an LSTM with subjective quality ratings labeled via crowdsourcing. The videos were collected from live videoconferencing calls in 83 different network conditions. We applied QR codes as markers on the source videos to create aligned references and compute temporal features based on the alignment vectors. Using these features together with VMAF core features, our proposed model achieves a PCC of 0.99 on the validation set. Furthermore, our model outputs per-frame quality that gives detailed insight into the cause of video quality impairments. The VCM model and dataset are open-sourced at https://github.com/microsoft/Video_Call_MOS.