 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICME 2025 Grand Challenge on Video Super-Resolution for Video Conferencing
Jun 13, 2025Super-Resolution (SR) is a critical task in computer vision, focusing on reconstructing high-resolution (HR) images from low-resolution (LR) inputs. The field has seen significant progress through various challenges, particularly in single-image SR. Video Super-Resolution (VSR) extends this to the temporal domain, aiming to enhance video quality using methods like local, uni-, bi-directional propagation, or traditional upscaling followed by restoration. This challenge addresses VSR for conferencing, where LR videos are encoded with H.265 at fixed QPs. The goal is to upscale videos by a specific factor, providing HR outputs with enhanced perceptual quality under a low-delay scenario using causal models. The challenge included three tracks: general-purpose videos, talking head videos, and screen content videos, with separate datasets provided by the organizers for training, validation, and testing. We open-sourced a new screen content dataset for the SR task in this challenge. Submissions were evaluated through subjective tests using a crowdsourced implementation of the ITU-T Rec P.910.
A multidimensional measurement of photorealistic avatar quality of experience
Nov 13, 2024



Photorealistic avatars are human avatars that look, move, and talk like real people. The performance of photorealistic avatars has significantly improved recently based on objective metrics such as PSNR, SSIM, LPIPS, FID, and FVD. However, recent photorealistic avatar publications do not provide subjective tests of the avatars to measure human usability factors. We provide an open source test framework to subjectively measure photorealistic avatar performance in ten dimensions: realism, trust, comfortableness using, comfortableness interacting with, appropriateness for work, creepiness, formality, affinity, resemblance to the person, and emotion accuracy. We show that the correlation of nine of these subjective metrics with PSNR, SSIM, LPIPS, FID, and FVD is weak, and moderate for emotion accuracy. The crowdsourced subjective test framework is highly reproducible and accurate when compared to a panel of experts. We analyze a wide range of avatars from photorealistic to cartoon-like and show that some photorealistic avatars are approaching real video performance based on these dimensions. We also find that for avatars above a certain level of realism, eight of these measured dimensions are strongly correlated. In particular, for photorealistic avatars there is a linear relationship between avatar affinity and realism; in other words, there is no uncanny valley effect for photorealistic avatars in the telecommunication scenario. We provide several extensions of this test framework for future work and discuss design implications for telecommunication systems. The test framework is available at https://github.com/microsoft/P.910.
Topic-Conversation Relevance (TCR) Dataset and Benchmarks
Nov 04, 2024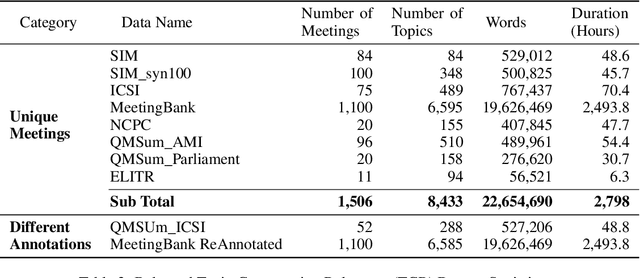

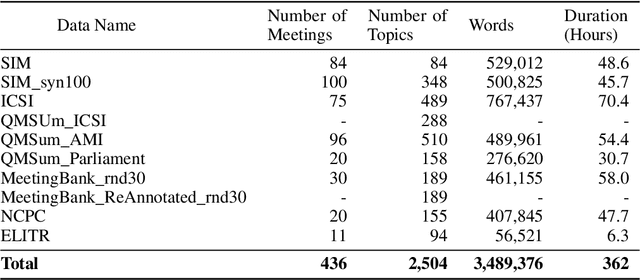
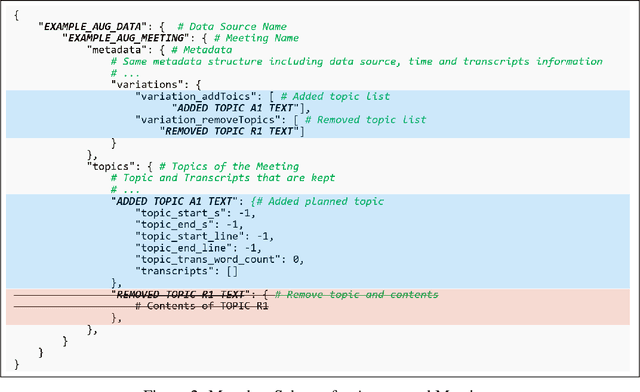
Workplace meetings are vital to organizational collaboration, yet a large percentage of meetings are rated as ineffective. To help improve meeting effectiveness by understanding if the conversation is on topic, we create a comprehensive Topic-Conversation Relevance (TCR) dataset that covers a variety of domains and meeting styles. The TCR dataset includes 1,500 unique meetings, 22 million words in transcripts, and over 15,000 meeting topics, sourced from both newly collected Speech Interruption Meeting (SIM) data and existing public datasets. Along with the text data, we also open source scripts to generate synthetic meetings or create augmented meetings from the TCR dataset to enhance data diversity. For each data source, benchmarks are created using GPT-4 to evaluate the model accuracy in understanding transcription-topic relevance.
The ICASSP 2024 Audio Deep Packet Loss Concealment Challenge
Feb 26, 2024
Audio packet loss concealment is the hiding of gaps in VoIP audio streams caused by network packet loss. With the ICASSP 2024 Audio Deep Packet Loss Concealment Grand Challenge, we build on the success of the previous Audio PLC Challenge held at INTERSPEECH 2022. We evaluate models on an overall harder dataset, and use the new ITU-T P.804 evaluation procedure to more closely evaluate the performance of systems specifically on the PLC task. We evaluate a total of 9 systems, 8 of which satisfy the strict real-time performance requirements of the challenge, using both P.804 and Word Accuracy evaluations.
ICASSP 2024 Speech Signal Improvement Challenge
Jan 25, 2024
The ICASSP 2024 Speech Signal Improvement Grand Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. This marks our second challenge, building upon the success from the previous ICASSP 2023 Grand Challenge. We enhance the competition by introducing a dataset synthesizer, enabling all participating teams to start at a higher baseline, an objective metric for our extended P.804 tests, transcripts for the 2023 test set, and we add Word Accuracy (WAcc) as a metric. We evaluate a total of 13 systems in the real-time track and 11 systems in the non-real-time track using both subjective P.804 and objective Word Accuracy metrics.
Real-time Bandwidth Estimation from Offline Expert Demonstrations
Sep 23, 2023



In this work, we tackle the problem of bandwidth estimation (BWE) for real-time communication systems; however, in contrast to previous works, we leverage the vast efforts of prior heuristic-based BWE methods and synergize these approaches with deep learning-based techniques. Our work addresses challenges in generalizing to unseen network dynamics and extracting rich representations from prior experience, two key challenges in integrating data-driven bandwidth estimators into real-time systems. To that end, we propose Merlin, the first purely offline, data-driven solution to BWE that harnesses prior heuristic-based methods to extract an expert BWE policy. Through a series of experiments, we demonstrate that Merlin surpasses state-of-the-art heuristic-based and deep learning-based bandwidth estimators in terms of objective quality of experience metrics while generalizing beyond the offline world to in-the-wild network deployments where Merlin achieves a 42.85% and 12.8% reduction in packet loss and delay, respectively, when compared against WebRTC in inter-continental videoconferencing calls. We hope that Merlin's offline-oriented design fosters new strategies for real-time network control.
ICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023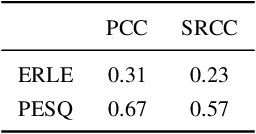
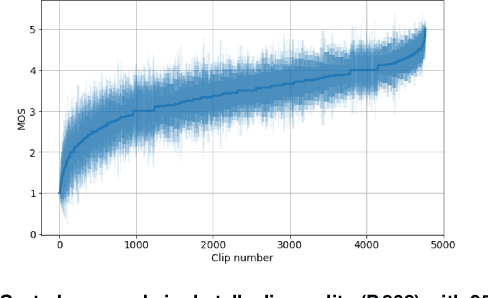

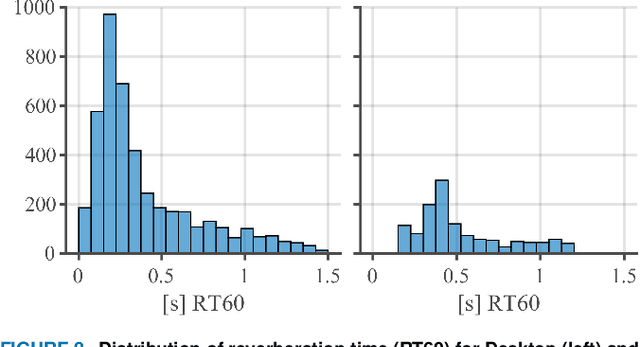
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
A Real-Time Active Speaker Detection System Integrating an Audio-Visual Signal with a Spatial Querying Mechanism
Sep 15, 2023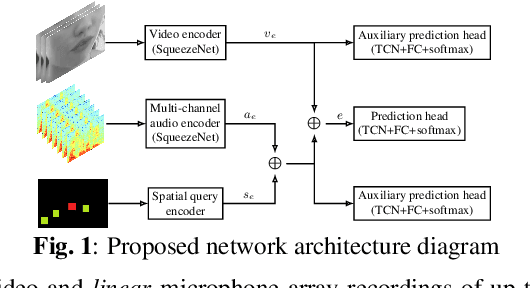


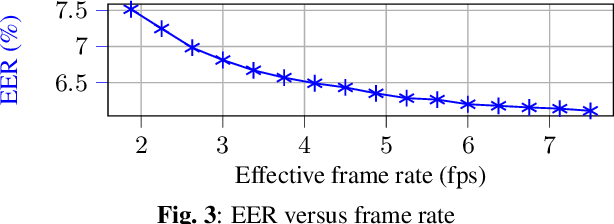
We introduce a distinctive real-time, causal, neural network-based active speaker detection system optimized for low-power edge computing. This system drives a virtual cinematography module and is deployed on a commercial device. The system uses data originating from a microphone array and a 360-degree camera. Our network requires only 127 MFLOPs per participant, for a meeting with 14 participants. Unlike previous work, we examine the error rate of our network when the computational budget is exhausted, and find that it exhibits graceful degradation, allowing the system to operate reasonably well even in this case. Departing from conventional DOA estimation approaches, our network learns to query the available acoustic data, considering the detected head locations. We train and evaluate our algorithm on a realistic meetings dataset featuring up to 14 participants in the same meeting, overlapped speech, and other challenging scenarios.
Multi-dimensional Speech Quality Assessment in Crowdsourcing
Sep 14, 2023Subjective speech quality assessment is the gold standard for evaluating speech enhancement processing and telecommunication systems. The commonly used standard ITU-T Rec. P.800 defines how to measure speech quality in lab environments, and ITU-T Rec.~P.808 extended it for crowdsourcing. ITU-T Rec. P.835 extends P.800 to measure the quality of speech in the presence of noise. ITU-T Rec. P.804 targets the conversation test and introduces perceptual speech quality dimensions which are measured during the listening phase of the conversation. The perceptual dimensions are noisiness, coloration, discontinuity, and loudness. We create a crowdsourcing implementation of a multi-dimensional subjective test following the scales from P.804 and extend it to include reverberation, the speech signal, and overall quality. We show the tool is both accurate and reproducible. The tool has been used in the ICASSP 2023 Speech Signal Improvement challenge and we show the utility of these speech quality dimensions in this challenge. The tool will be publicly available as open-source at https://github.com/microsoft/P.808.
VCD: A Video Conferencing Dataset for Video Compression
Sep 14, 2023



Commonly used datasets for evaluating video codecs are all very high quality and not representative of video typically used in video conferencing scenarios. We present the Video Conferencing Dataset (VCD) for evaluating video codecs for real-time communication, the first such dataset focused on video conferencing. VCD includes a wide variety of camera qualities and spatial and temporal information. It includes both desktop and mobile scenarios and two types of video background processing. We report the compression efficiency of H.264, H.265, H.266, and AV1 in low-delay settings on VCD and compare it with the non-video conferencing datasets UVC, MLC-JVC, and HEVC. The results show the source quality and the scenarios have a significant effect on the compression efficiency of all the codecs. VCD enables the evaluation and tuning of codecs for this important scenario. The VCD is publicly available as an open-source dataset at https://github.com/microsoft/VCD.