 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-Time Active Speaker Detection System Integrating an Audio-Visual Signal with a Spatial Querying Mechanism
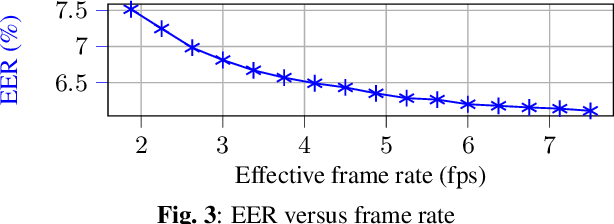
Sep 15, 2023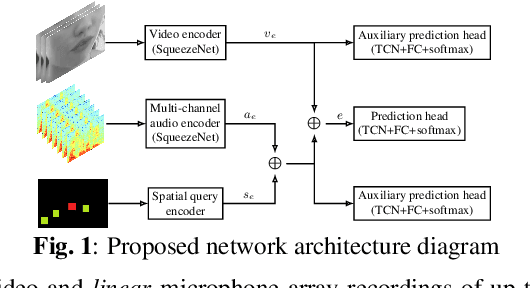


We introduce a distinctive real-time, causal, neural network-based active speaker detection system optimized for low-power edge computing. This system drives a virtual cinematography module and is deployed on a commercial device. The system uses data originating from a microphone array and a 360-degree camera. Our network requires only 127 MFLOPs per participant, for a meeting with 14 participants. Unlike previous work, we examine the error rate of our network when the computational budget is exhausted, and find that it exhibits graceful degradation, allowing the system to operate reasonably well even in this case. Departing from conventional DOA estimation approaches, our network learns to query the available acoustic data, considering the detected head locations. We train and evaluate our algorithm on a realistic meetings dataset featuring up to 14 participants in the same meeting, overlapped speech, and other challenging scenarios.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019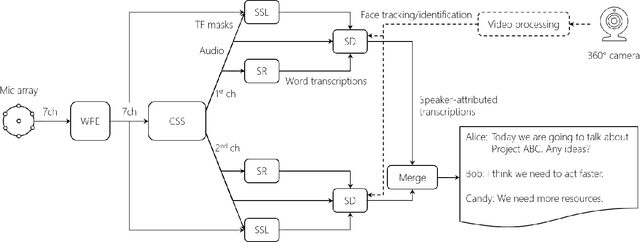

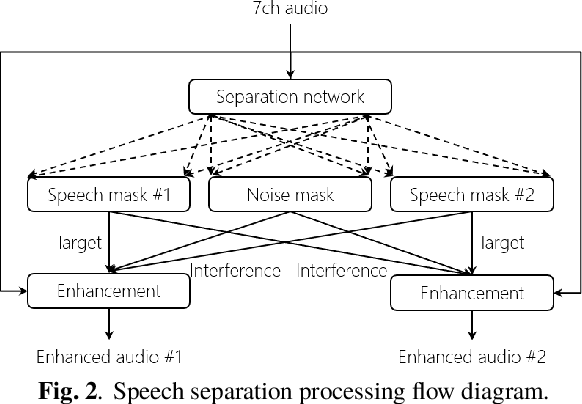
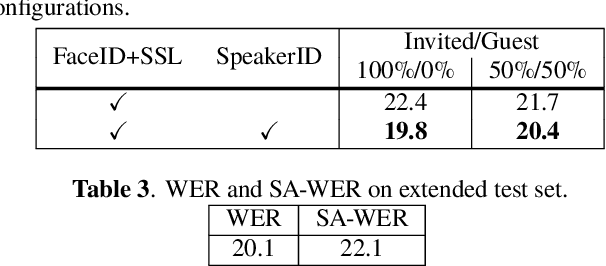
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
SRA: Fast Removal of General Multipath for ToF Sensors
Mar 24, 2014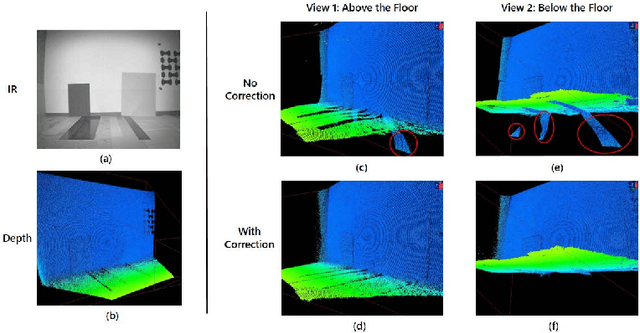
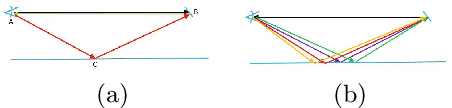

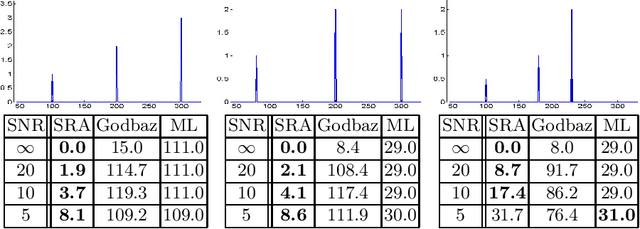
A major issue with Time of Flight sensors is the presence of multipath interference. We present Sparse Reflections Analysis (SRA), an algorithm for removing this interference which has two main advantages. First, it allows for very general forms of multipath, including interference with three or more paths, diffuse multipath resulting from Lambertian surfaces, and combinations thereof. SRA removes this general multipath with robust techniques based on $L_1$ optimization. Second, due to a novel dimension reduction, we are able to produce a very fast version of SRA, which is able to run at frame rate. Experimental results on both synthetic data with ground truth, as well as real images of challenging scenes, validate the approach.