 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
May 22, 2026Large language model (LLM) agents accumulate rich episodic trajectories while solving real-world tasks, but it remains unclear whether such experience can be distilled into reusable procedural skills. We introduce SkillEvolBench, a diagnostic benchmark for evaluating this step from experience reuse to skill formation. It contains 180 tasks across six real-world agent environments, organized into role-conditioned task families with shared latent procedures. Agents learn from acquisition tasks, update an external skill library using compacted trajectories and verifier feedback, and then face frozen deployment tasks testing context shift, adversarial shortcuts, and composition. By comparing self-generated and curated-start skill evolution against no-skill and raw-trajectory controls, SkillEvolBench separates procedural abstraction from base capability, curated prior knowledge, and direct reuse of episodic traces. Across ten model configurations and three agent harnesses, we find that current agents often adapt locally but rarely form robust reusable skills. Skill-based conditions can improve acquisition or replay, and individual models sometimes gain on specific deployment axes, but these gains are unstable under frozen deployment. Raw-trajectory reuse frequently outperforms distilled skills, suggesting that current abstraction procedures discard contextual and procedural cues that remain useful for future tasks. Capacity and cost analyses further show that writing more skills or larger Tier-3 resource libraries is not sufficient: additional updates can improve coverage while introducing episode-specific drift and procedural clutter. These findings position SkillEvolBench as a testbed for measuring when one-off experience becomes durable procedural knowledge rather than task-local memory.
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
CroMo-Mixup: Augmenting Cross-Model Representations for Continual Self-Supervised Learning
Jul 16, 2024



Continual self-supervised learning (CSSL) learns a series of tasks sequentially on the unlabeled data. Two main challenges of continual learning are catastrophic forgetting and task confusion. While CSSL problem has been studied to address the catastrophic forgetting challenge, little work has been done to address the task confusion aspect. In this work, we show through extensive experiments that self-supervised learning (SSL) can make CSSL more susceptible to the task confusion problem, particularly in less diverse settings of class incremental learning because different classes belonging to different tasks are not trained concurrently. Motivated by this challenge, we present a novel cross-model feature Mixup (CroMo-Mixup) framework that addresses this issue through two key components: 1) Cross-Task data Mixup, which mixes samples across tasks to enhance negative sample diversity; and 2) Cross-Model feature Mixup, which learns similarities between embeddings obtained from current and old models of the mixed sample and the original images, facilitating cross-task class contrast learning and old knowledge retrieval. We evaluate the effectiveness of CroMo-Mixup to improve both Task-ID prediction and average linear accuracy across all tasks on three datasets, CIFAR10, CIFAR100, and tinyImageNet under different class-incremental learning settings. We validate the compatibility of CroMo-Mixup on four state-of-the-art SSL objectives. Code is available at \url{https://github.com/ErumMushtaq/CroMo-Mixup}.
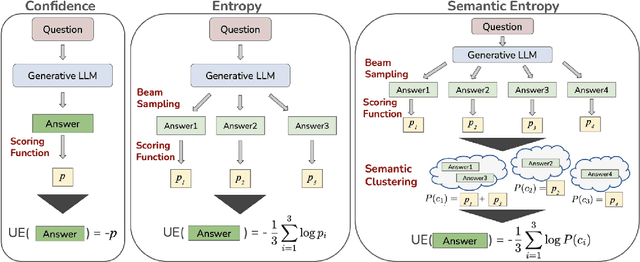
Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs
Jun 17, 2024In this work, we introduce the Learnable Response Scoring Function (LARS) for Uncertainty Estimation (UE) in generative Large Language Models (LLMs). Current scoring functions for probability-based UE, such as length-normalized scoring and semantic contribution-based weighting, are designed to solve specific aspects of the problem but exhibit limitations, including the inability to handle biased probabilities and under-performance in low-resource languages like Turkish. To address these issues, we propose LARS, a scoring function that leverages supervised data to capture complex dependencies between tokens and probabilities, thereby producing more reliable and calibrated response scores in computing the uncertainty of generations. Our extensive experiments across multiple datasets show that LARS substantially outperforms existing scoring functions considering various probability-based UE methods.
Can Synthetic Audio From Generative Foundation Models Assist Audio Recognition and Speech Modeling?
Jun 13, 2024


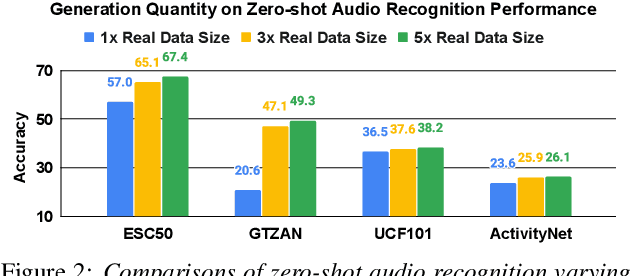
Recent advances in foundation models have enabled audio-generative models that produce high-fidelity sounds associated with music, events, and human actions. Despite the success achieved in modern audio-generative models, the conventional approach to assessing the quality of the audio generation relies heavily on distance metrics like Frechet Audio Distance. In contrast, we aim to evaluate the quality of audio generation by examining the effectiveness of using them as training data. Specifically, we conduct studies to explore the use of synthetic audio for audio recognition. Moreover, we investigate whether synthetic audio can serve as a resource for data augmentation in speech-related modeling. Our comprehensive experiments demonstrate the potential of using synthetic audio for audio recognition and speech-related modeling. Our code is available at https://github.com/usc-sail/SynthAudio.
MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs
Feb 20, 2024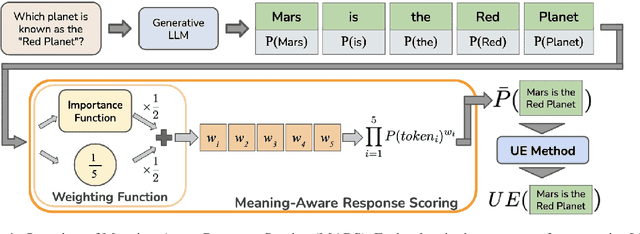
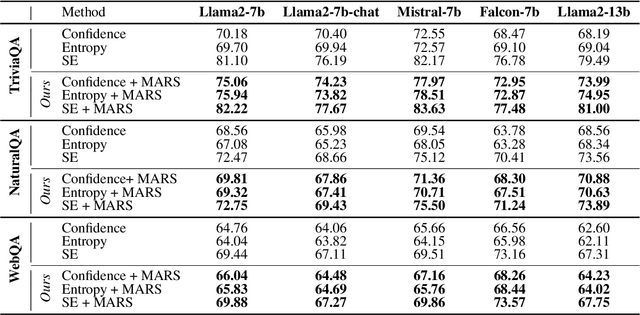
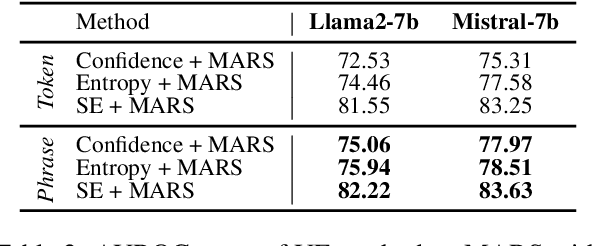
Generative Large Language Models (LLMs) are widely utilized for their excellence in various tasks. However, their tendency to produce inaccurate or misleading outputs poses a potential risk, particularly in high-stakes environments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estimation (UE) in generative LLMs is an evolving domain, where SOTA probability-based methods commonly employ length-normalized scoring. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that considers the semantic contribution of each token in the generated sequence in the context of the question. We demonstrate that integrating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset. Code can be found https://github.com/Ybakman/LLM_Uncertainity.
Local or Global: Selective Knowledge Assimilation for Federated Learning with Limited Labels
Jul 17, 2023
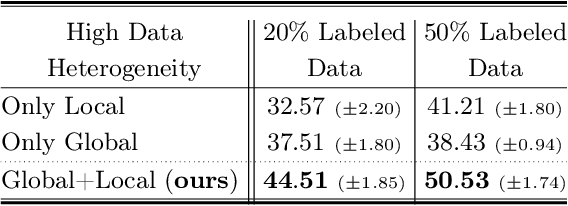


Many existing FL methods assume clients with fully-labeled data, while in realistic settings, clients have limited labels due to the expensive and laborious process of labeling. Limited labeled local data of the clients often leads to their local model having poor generalization abilities to their larger unlabeled local data, such as having class-distribution mismatch with the unlabeled data. As a result, clients may instead look to benefit from the global model trained across clients to leverage their unlabeled data, but this also becomes difficult due to data heterogeneity across clients. In our work, we propose FedLabel where clients selectively choose the local or global model to pseudo-label their unlabeled data depending on which is more of an expert of the data. We further utilize both the local and global models' knowledge via global-local consistency regularization which minimizes the divergence between the two models' outputs when they have identical pseudo-labels for the unlabeled data. Unlike other semi-supervised FL baselines, our method does not require additional experts other than the local or global model, nor require additional parameters to be communicated. We also do not assume any server-labeled data or fully labeled clients. For both cross-device and cross-silo settings, we show that FedLabel outperforms other semi-supervised FL baselines by $8$-$24\%$, and even outperforms standard fully supervised FL baselines ($100\%$ labeled data) with only $5$-$20\%$ of labeled data.
Fed-ZERO: Efficient Zero-shot Personalization with Federated Mixture of Experts
Jun 14, 2023



One of the goals in Federated Learning (FL) is to create personalized models that can adapt to the context of each participating client, while utilizing knowledge from a shared global model. Yet, often, personalization requires a fine-tuning step using clients' labeled data in order to achieve good performance. This may not be feasible in scenarios where incoming clients are fresh and/or have privacy concerns. It, then, remains open how one can achieve zero-shot personalization in these scenarios. We propose a novel solution by using a Mixture-of-Experts (MoE) framework within a FL setup. Our method leverages the diversity of the clients to train specialized experts on different subsets of classes, and a gating function to route the input to the most relevant expert(s). Our gating function harnesses the knowledge of a pretrained model common expert to enhance its routing decisions on-the-fly. As a highlight, our approach can improve accuracy up to 18\% in state of the art FL settings, while maintaining competitive zero-shot performance. In practice, our method can handle non-homogeneous data distributions, scale more efficiently, and improve the state-of-the-art performance on common FL benchmarks.
Counterfactual Augmentation for Multimodal Learning Under Presentation Bias
May 23, 2023In real-world machine learning systems, labels are often derived from user behaviors that the system wishes to encourage. Over time, new models must be trained as new training examples and features become available. However, feedback loops between users and models can bias future user behavior, inducing a presentation bias in the labels that compromises the ability to train new models. In this paper, we propose counterfactual augmentation, a novel causal method for correcting presentation bias using generated counterfactual labels. Our empirical evaluations demonstrate that counterfactual augmentation yields better downstream performance compared to both uncorrected models and existing bias-correction methods. Model analyses further indicate that the generated counterfactuals align closely with true counterfactuals in an oracle setting.
Federated Multilingual Models for Medical Transcript Analysis
Nov 04, 2022Federated Learning (FL) is a novel machine learning approach that allows the model trainer to access more data samples, by training the model across multiple decentralized data sources, while data access constraints are in place. Such trained models can achieve significantly higher performance beyond what can be done when trained on a single data source. As part of FL's promises, none of the training data is ever transmitted to any central location, ensuring that sensitive data remains local and private. These characteristics make FL perfectly suited for large-scale applications in healthcare, where a variety of compliance constraints restrict how data may be handled, processed, and stored. Despite the apparent benefits of federated learning, the heterogeneity in the local data distributions pose significant challenges, and such challenges are even more pronounced in the case of multilingual data providers. In this paper we present a federated learning system for training a large-scale multi-lingual model suitable for fine-tuning on downstream tasks such as medical entity tagging. Our work represents one of the first such production-scale systems, capable of training across multiple highly heterogeneous data providers, and achieving levels of accuracy that could not be otherwise achieved by using central training with public data. Finally, we show that the global model performance can be further improved by a training step performed locally.