 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025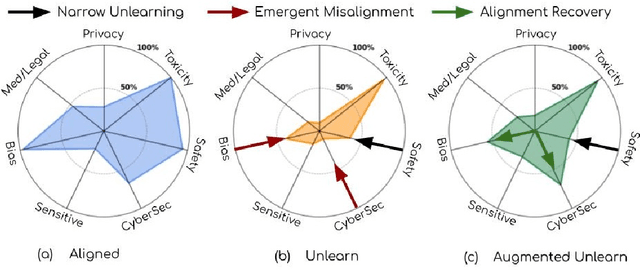
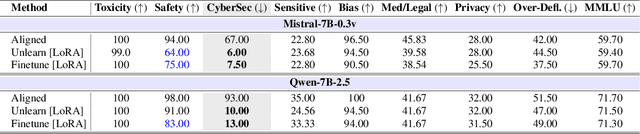
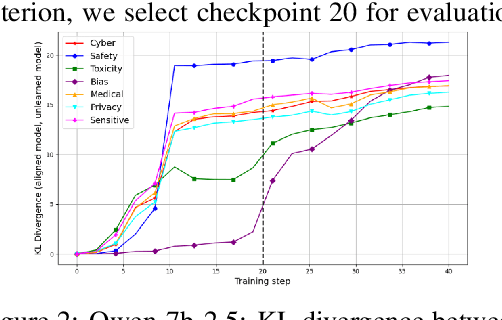
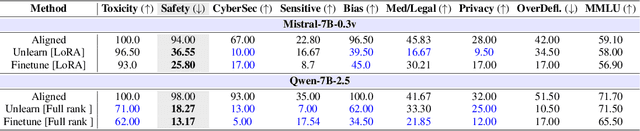
Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
CroMo-Mixup: Augmenting Cross-Model Representations for Continual Self-Supervised Learning
Jul 16, 2024



Continual self-supervised learning (CSSL) learns a series of tasks sequentially on the unlabeled data. Two main challenges of continual learning are catastrophic forgetting and task confusion. While CSSL problem has been studied to address the catastrophic forgetting challenge, little work has been done to address the task confusion aspect. In this work, we show through extensive experiments that self-supervised learning (SSL) can make CSSL more susceptible to the task confusion problem, particularly in less diverse settings of class incremental learning because different classes belonging to different tasks are not trained concurrently. Motivated by this challenge, we present a novel cross-model feature Mixup (CroMo-Mixup) framework that addresses this issue through two key components: 1) Cross-Task data Mixup, which mixes samples across tasks to enhance negative sample diversity; and 2) Cross-Model feature Mixup, which learns similarities between embeddings obtained from current and old models of the mixed sample and the original images, facilitating cross-task class contrast learning and old knowledge retrieval. We evaluate the effectiveness of CroMo-Mixup to improve both Task-ID prediction and average linear accuracy across all tasks on three datasets, CIFAR10, CIFAR100, and tinyImageNet under different class-incremental learning settings. We validate the compatibility of CroMo-Mixup on four state-of-the-art SSL objectives. Code is available at \url{https://github.com/ErumMushtaq/CroMo-Mixup}.
Federated Alternate Training (FAT): Leveraging Unannotated Data Silos in Federated Segmentation for Medical Imaging
Apr 18, 2023Federated Learning (FL) aims to train a machine learning (ML) model in a distributed fashion to strengthen data privacy with limited data migration costs. It is a distributed learning framework naturally suitable for privacy-sensitive medical imaging datasets. However, most current FL-based medical imaging works assume silos have ground truth labels for training. In practice, label acquisition in the medical field is challenging as it often requires extensive labor and time costs. To address this challenge and leverage the unannotated data silos to improve modeling, we propose an alternate training-based framework, Federated Alternate Training (FAT), that alters training between annotated data silos and unannotated data silos. Annotated data silos exploit annotations to learn a reasonable global segmentation model. Meanwhile, unannotated data silos use the global segmentation model as a target model to generate pseudo labels for self-supervised learning. We evaluate the performance of the proposed framework on two naturally partitioned Federated datasets, KiTS19 and FeTS2021, and show its promising performance.
FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022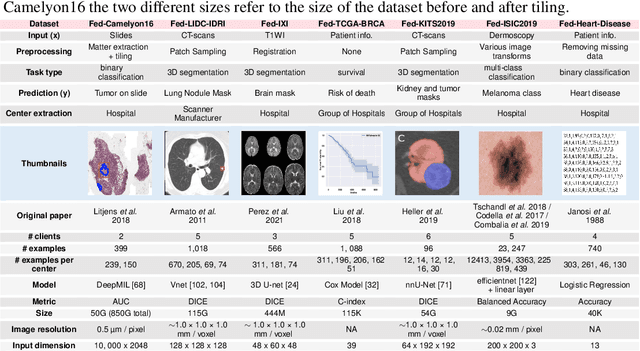
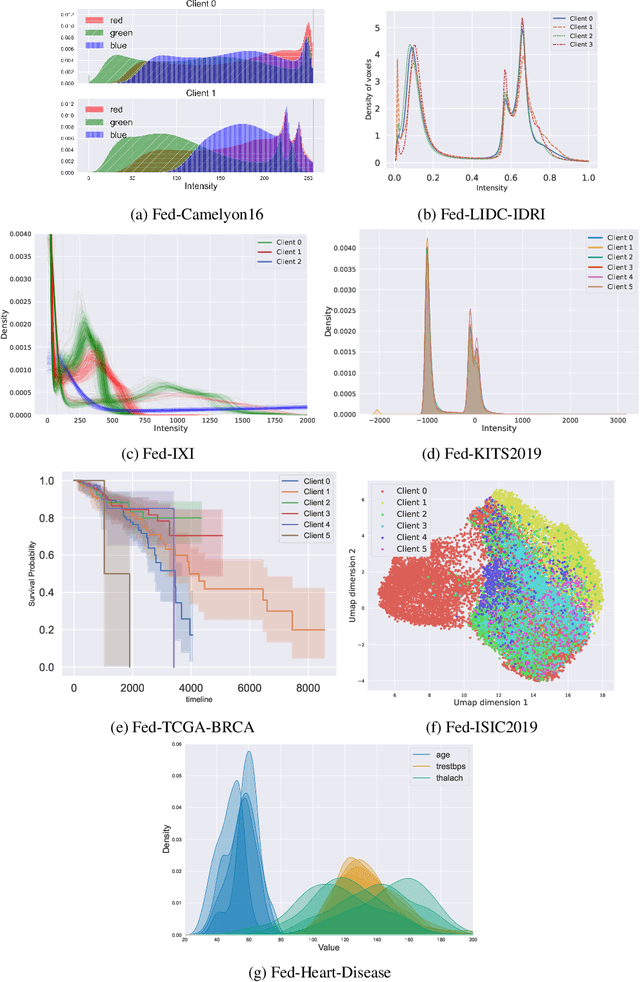
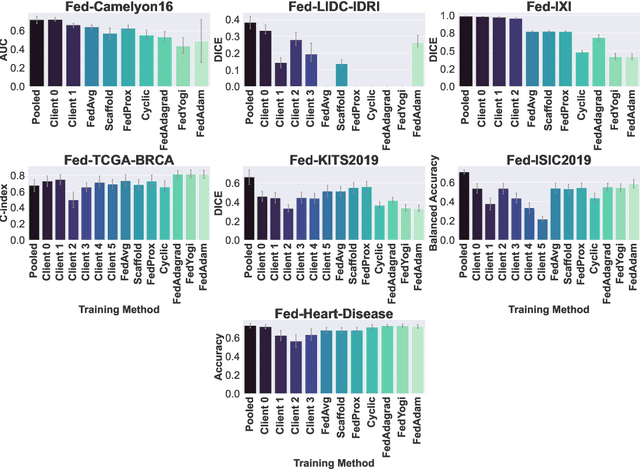

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
SPIDER: Searching Personalized Neural Architecture for Federated Learning
Dec 27, 2021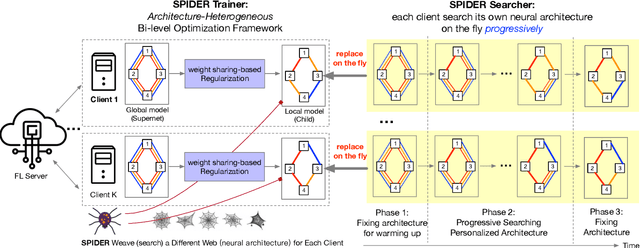
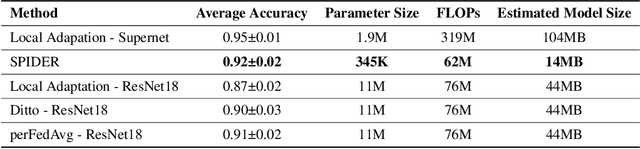

Federated learning (FL) is an efficient learning framework that assists distributed machine learning when data cannot be shared with a centralized server due to privacy and regulatory restrictions. Recent advancements in FL use predefined architecture-based learning for all the clients. However, given that clients' data are invisible to the server and data distributions are non-identical across clients, a predefined architecture discovered in a centralized setting may not be an optimal solution for all the clients in FL. Motivated by this challenge, in this work, we introduce SPIDER, an algorithmic framework that aims to Search Personalized neural architecture for federated learning. SPIDER is designed based on two unique features: (1) alternately optimizing one architecture-homogeneous global model (Supernet) in a generic FL manner and one architecture-heterogeneous local model that is connected to the global model by weight sharing-based regularization (2) achieving architecture-heterogeneous local model by a novel neural architecture search (NAS) method that can select optimal subnet progressively using operation-level perturbation on the accuracy value as the criterion. Experimental results demonstrate that SPIDER outperforms other state-of-the-art personalization methods, and the searched personalized architectures are more inference efficient.
SSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision
Oct 06, 2021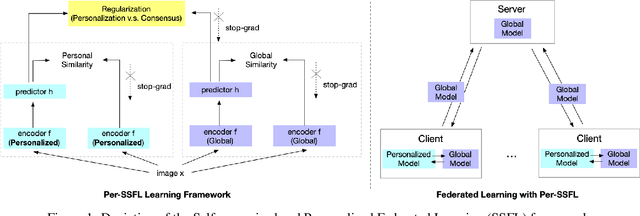

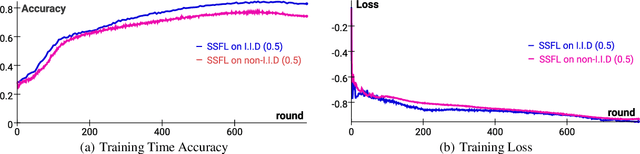
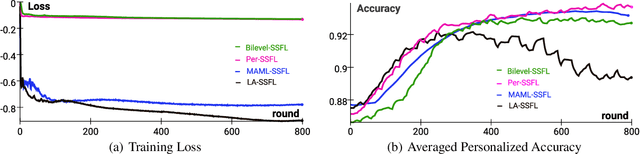
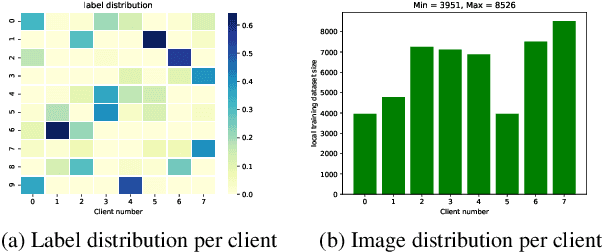
Federated Learning (FL) is transforming the ML training ecosystem from a centralized over-the-cloud setting to distributed training over edge devices in order to strengthen data privacy. An essential but rarely studied challenge in FL is label deficiency at the edge. This problem is even more pronounced in FL compared to centralized training due to the fact that FL users are often reluctant to label their private data. Furthermore, due to the heterogeneous nature of the data at edge devices, it is crucial to develop personalized models. In this paper we propose self-supervised federated learning (SSFL), a unified self-supervised and personalized federated learning framework, and a series of algorithms under this framework which work towards addressing these challenges. First, under the SSFL framework, we demonstrate that the standard FedAvg algorithm is compatible with recent breakthroughs in centralized self-supervised learning such as SimSiam networks. Moreover, to deal with data heterogeneity at the edge devices in this framework, we have innovated a series of algorithms that broaden existing supervised personalization algorithms into the setting of self-supervised learning. We further propose a novel personalized federated self-supervised learning algorithm, Per-SSFL, which balances personalization and consensus by carefully regulating the distance between the local and global representations of data. To provide a comprehensive comparative analysis of all proposed algorithms, we also develop a distributed training system and related evaluation protocol for SSFL. Our findings show that the gap of evaluation accuracy between supervised learning and unsupervised learning in FL is both small and reasonable. The performance comparison indicates the representation regularization-based personalization method is able to outperform other variants.