 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSLIM:Align with diverse preferences in prompts through reward classification
May 24, 2025

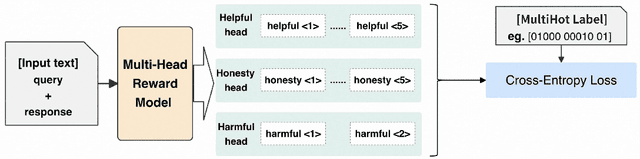
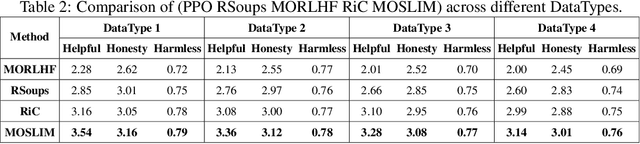
The multi-objective alignment of Large Language Models (LLMs) is essential for ensuring foundational models conform to diverse human preferences. Current research in this field typically involves either multiple policies or multiple reward models customized for various preferences, or the need to train a preference-specific supervised fine-tuning (SFT) model. In this work, we introduce a novel multi-objective alignment method, MOSLIM, which utilizes a single reward model and policy model to address diverse objectives. MOSLIM provides a flexible way to control these objectives through prompting and does not require preference training during SFT phase, allowing thousands of off-the-shelf models to be directly utilized within this training framework. MOSLIM leverages a multi-head reward model that classifies question-answer pairs instead of scoring them and then optimize policy model with a scalar reward derived from a mapping function that converts classification results from reward model into reward scores. We demonstrate the efficacy of our proposed method across several multi-objective benchmarks and conduct ablation studies on various reward model sizes and policy optimization methods. The MOSLIM method outperforms current multi-objective approaches in most results while requiring significantly fewer GPU computing resources compared with existing policy optimization methods.
GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

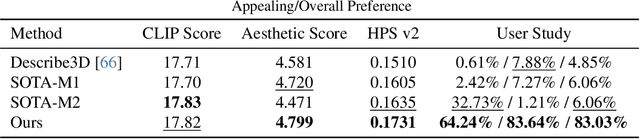
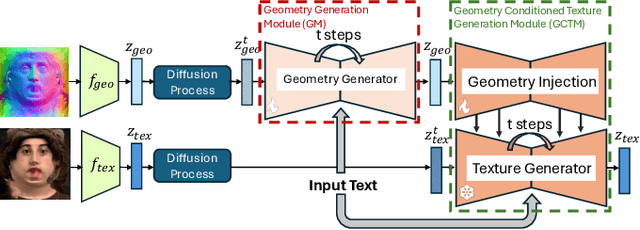
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Bridging the Gap: Studio-like Avatar Creation from a Monocular Phone Capture
Jul 28, 2024Creating photorealistic avatars for individuals traditionally involves extensive capture sessions with complex and expensive studio devices like the LightStage system. While recent strides in neural representations have enabled the generation of photorealistic and animatable 3D avatars from quick phone scans, they have the capture-time lighting baked-in, lack facial details and have missing regions in areas such as the back of the ears. Thus, they lag in quality compared to studio-captured avatars. In this paper, we propose a method that bridges this gap by generating studio-like illuminated texture maps from short, monocular phone captures. We do this by parameterizing the phone texture maps using the $W^+$ space of a StyleGAN2, enabling near-perfect reconstruction. Then, we finetune a StyleGAN2 by sampling in the $W^+$ parameterized space using a very small set of studio-captured textures as an adversarial training signal. To further enhance the realism and accuracy of facial details, we super-resolve the output of the StyleGAN2 using carefully designed diffusion model that is guided by image gradients of the phone-captured texture map. Once trained, our method excels at producing studio-like facial texture maps from casual monocular smartphone videos. Demonstrating its capabilities, we showcase the generation of photorealistic, uniformly lit, complete avatars from monocular phone captures. \href{http://shahrukhathar.github.io/2024/07/22/Bridging.html}{The project page can be found here.}
Towards Applicable Reinforcement Learning: Improving the Generalization and Sample Efficiency with Policy Ensemble
May 19, 2022
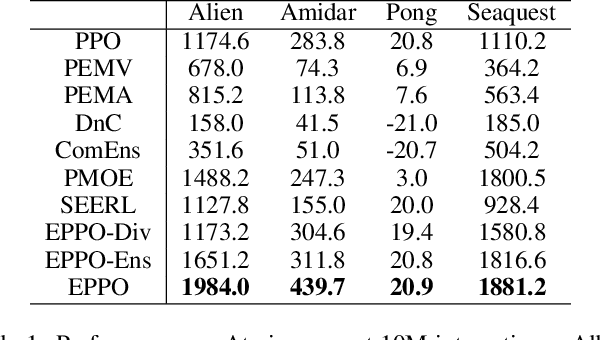
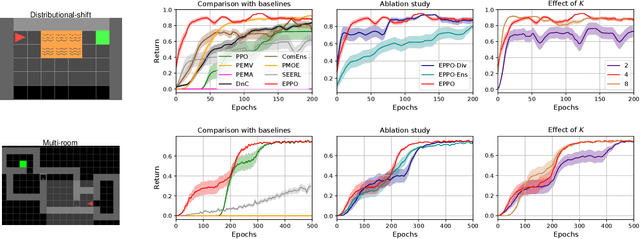
It is challenging for reinforcement learning (RL) algorithms to succeed in real-world applications like financial trading and logistic system due to the noisy observation and environment shifting between training and evaluation. Thus, it requires both high sample efficiency and generalization for resolving real-world tasks. However, directly applying typical RL algorithms can lead to poor performance in such scenarios. Considering the great performance of ensemble methods on both accuracy and generalization in supervised learning (SL), we design a robust and applicable method named Ensemble Proximal Policy Optimization (EPPO), which learns ensemble policies in an end-to-end manner. Notably, EPPO combines each policy and the policy ensemble organically and optimizes both simultaneously. In addition, EPPO adopts a diversity enhancement regularization over the policy space which helps to generalize to unseen states and promotes exploration. We theoretically prove EPPO increases exploration efficacy, and through comprehensive experimental evaluations on various tasks, we demonstrate that EPPO achieves higher efficiency and is robust for real-world applications compared with vanilla policy optimization algorithms and other ensemble methods. Code and supplemental materials are available at https://seqml.github.io/eppo.
Curriculum Offline Imitation Learning
Nov 03, 2021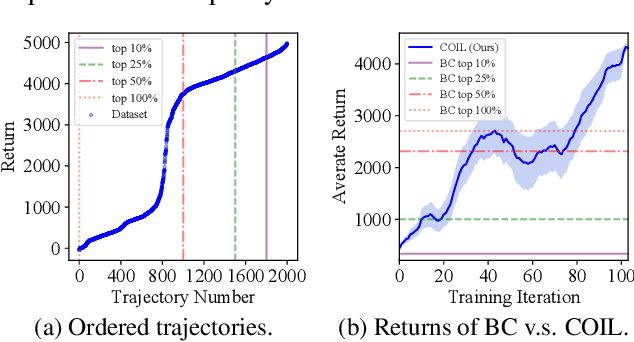
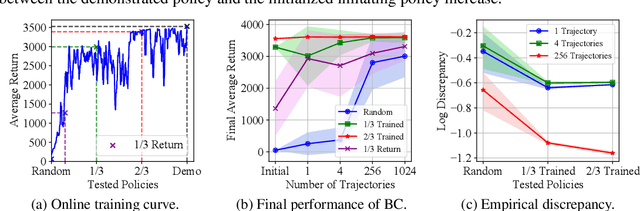
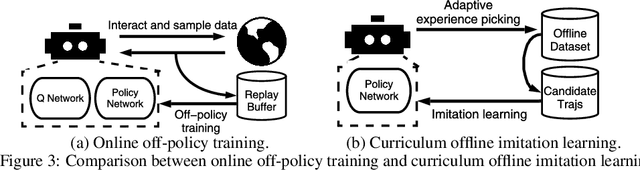

Offline reinforcement learning (RL) tasks require the agent to learn from a pre-collected dataset with no further interactions with the environment. Despite the potential to surpass the behavioral policies, RL-based methods are generally impractical due to the training instability and bootstrapping the extrapolation errors, which always require careful hyperparameter tuning via online evaluation. In contrast, offline imitation learning (IL) has no such issues since it learns the policy directly without estimating the value function by bootstrapping. However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies. In this paper, we aim to take advantage of IL but mitigate such a drawback. Observing that behavior cloning is able to imitate neighboring policies with less data, we propose \textit{Curriculum Offline Imitation Learning (COIL)}, which utilizes an experience picking strategy for imitating from adaptive neighboring policies with a higher return, and improves the current policy along curriculum stages. On continuous control benchmarks, we compare COIL against both imitation-based and RL-based methods, showing that it not only avoids just learning a mediocre behavior on mixed datasets but is also even competitive with state-of-the-art offline RL methods.
SSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision
Oct 06, 2021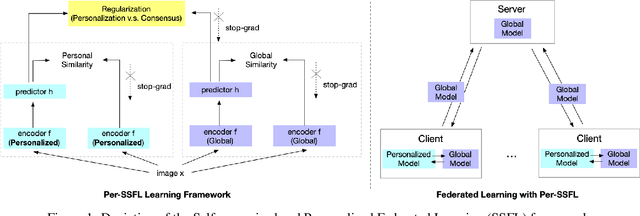

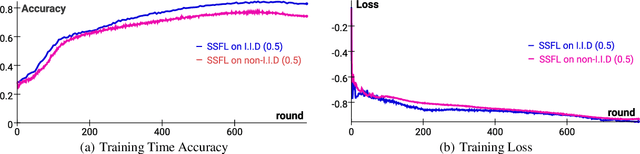
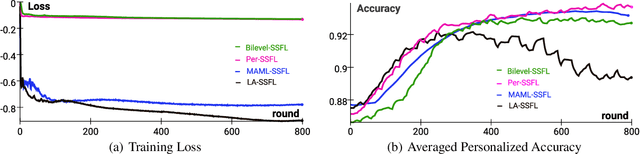
Federated Learning (FL) is transforming the ML training ecosystem from a centralized over-the-cloud setting to distributed training over edge devices in order to strengthen data privacy. An essential but rarely studied challenge in FL is label deficiency at the edge. This problem is even more pronounced in FL compared to centralized training due to the fact that FL users are often reluctant to label their private data. Furthermore, due to the heterogeneous nature of the data at edge devices, it is crucial to develop personalized models. In this paper we propose self-supervised federated learning (SSFL), a unified self-supervised and personalized federated learning framework, and a series of algorithms under this framework which work towards addressing these challenges. First, under the SSFL framework, we demonstrate that the standard FedAvg algorithm is compatible with recent breakthroughs in centralized self-supervised learning such as SimSiam networks. Moreover, to deal with data heterogeneity at the edge devices in this framework, we have innovated a series of algorithms that broaden existing supervised personalization algorithms into the setting of self-supervised learning. We further propose a novel personalized federated self-supervised learning algorithm, Per-SSFL, which balances personalization and consensus by carefully regulating the distance between the local and global representations of data. To provide a comprehensive comparative analysis of all proposed algorithms, we also develop a distributed training system and related evaluation protocol for SSFL. Our findings show that the gap of evaluation accuracy between supervised learning and unsupervised learning in FL is both small and reasonable. The performance comparison indicates the representation regularization-based personalization method is able to outperform other variants.
SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
Mar 30, 2021
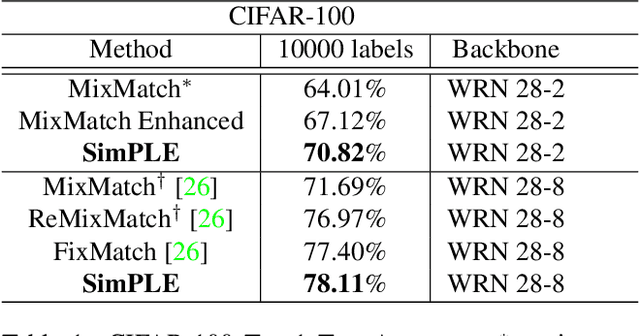
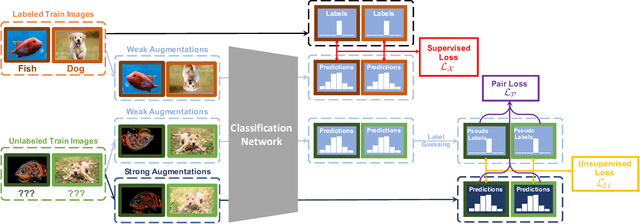
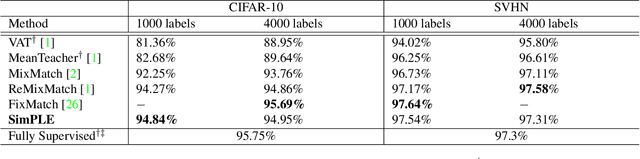
A common classification task situation is where one has a large amount of data available for training, but only a small portion is annotated with class labels. The goal of semi-supervised training, in this context, is to improve classification accuracy by leverage information not only from labeled data but also from a large amount of unlabeled data. Recent works have developed significant improvements by exploring the consistency constrain between differently augmented labeled and unlabeled data. Following this path, we propose a novel unsupervised objective that focuses on the less studied relationship between the high confidence unlabeled data that are similar to each other. The new proposed Pair Loss minimizes the statistical distance between high confidence pseudo labels with similarity above a certain threshold. Combining the Pair Loss with the techniques developed by the MixMatch family, our proposed SimPLE algorithm shows significant performance gains over previous algorithms on CIFAR-100 and Mini-ImageNet, and is on par with the state-of-the-art methods on CIFAR-10 and SVHN. Furthermore, SimPLE also outperforms the state-of-the-art methods in the transfer learning setting, where models are initialized by the weights pre-trained on ImageNet or DomainNet-Real. The code is available at github.com/zijian-hu/SimPLE.
To Follow or not to Follow: Selective Imitation Learning from Observations
Dec 16, 2019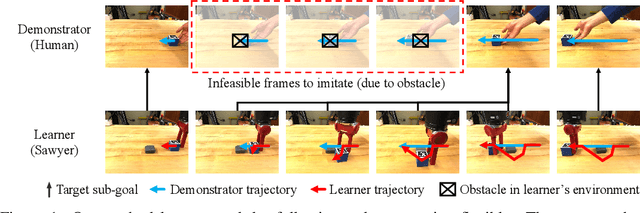

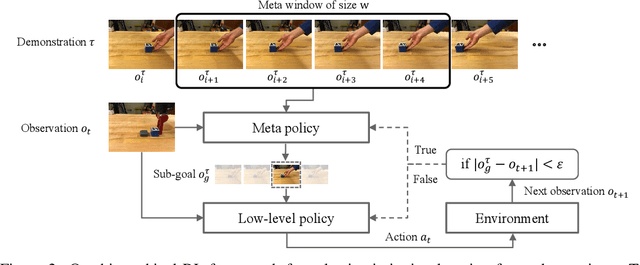
Learning from demonstrations is a useful way to transfer a skill from one agent to another. While most imitation learning methods aim to mimic an expert skill by following the demonstration step-by-step, imitating every step in the demonstration often becomes infeasible when the learner and its environment are different from the demonstration. In this paper, we propose a method that can imitate a demonstration composed solely of observations, which may not be reproducible with the current agent. Our method, dubbed selective imitation learning from observations (SILO), selects reachable states in the demonstration and learns how to reach the selected states. Our experiments on both simulated and real robot environments show that our method reliably performs a new task by following a demonstration. Videos and code are available at https://clvrai.com/silo .
IKEA Furniture Assembly Environment for Long-Horizon Complex Manipulation Tasks
Nov 17, 2019
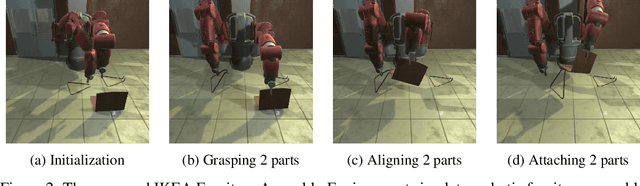

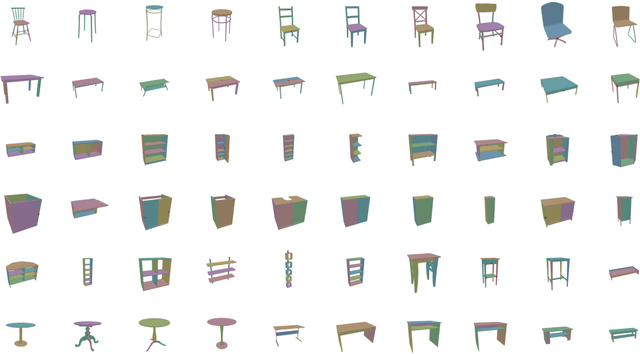
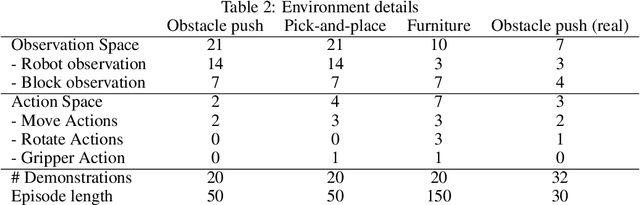
The IKEA Furniture Assembly Environment is one of the first benchmarks for testing and accelerating the automation of complex manipulation tasks. The environment is designed to advance reinforcement learning from simple toy tasks to complex tasks requiring both long-term planning and sophisticated low-level control. Our environment supports over 80 different furniture models, Sawyer and Baxter robot simulation, and domain randomization. The IKEA Furniture Assembly Environment is a testbed for methods aiming to solve complex manipulation tasks. The environment is publicly available at https://clvrai.com/furniture
Deep Landscape Forecasting for Real-time Bidding Advertising
May 12, 2019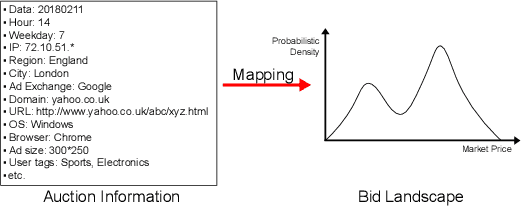
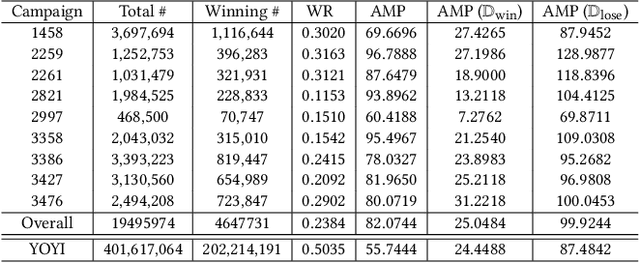
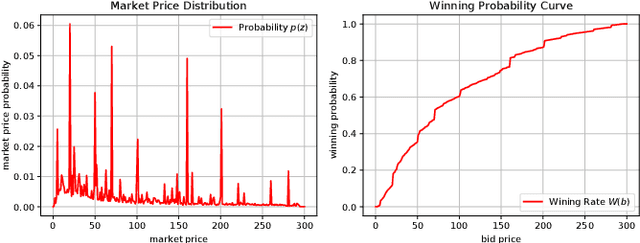
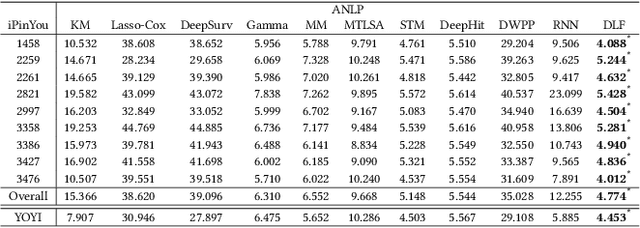
The emergence of real-time auction in online advertising has drawn huge attention of modeling the market competition, i.e., bid landscape forecasting. The problem is formulated as to forecast the probability distribution of market price for each ad auction. With the consideration of the censorship issue which is caused by the second-price auction mechanism, many researchers have devoted their efforts on bid landscape forecasting by incorporating survival analysis from medical research field. However, most existing solutions mainly focus on either counting-based statistics of the segmented sample clusters, or learning a parameterized model based on some heuristic assumptions of distribution forms. Moreover, they neither consider the sequential patterns of the feature over the price space. In order to capture more sophisticated yet flexible patterns at fine-grained level of the data, we propose a Deep Landscape Forecasting (DLF) model which combines deep learning for probability distribution forecasting and survival analysis for censorship handling. Specifically, we utilize a recurrent neural network to flexibly model the conditional winning probability w.r.t. each bid price. Then we conduct the bid landscape forecasting through probability chain rule with strict mathematical derivations. And, in an end-to-end manner, we optimize the model by minimizing two negative likelihood losses with comprehensive motivations. Without any specific assumption for the distribution form of bid landscape, our model shows great advantages over previous works on fitting various sophisticated market price distributions. In the experiments over two large-scale real-world datasets, our model significantly outperforms the state-of-the-art solutions under various metrics.