 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAMOUS: High-Fidelity Monocular 3D Human Digitization Using View Synthesis
Oct 13, 2024The advancement in deep implicit modeling and articulated models has significantly enhanced the process of digitizing human figures in 3D from just a single image. While state-of-the-art methods have greatly improved geometric precision, the challenge of accurately inferring texture remains, particularly in obscured areas such as the back of a person in frontal-view images. This limitation in texture prediction largely stems from the scarcity of large-scale and diverse 3D datasets, whereas their 2D counterparts are abundant and easily accessible. To address this issue, our paper proposes leveraging extensive 2D fashion datasets to enhance both texture and shape prediction in 3D human digitization. We incorporate 2D priors from the fashion dataset to learn the occluded back view, refined with our proposed domain alignment strategy. We then fuse this information with the input image to obtain a fully textured mesh of the given person. Through extensive experimentation on standard 3D human benchmarks, we demonstrate the superior performance of our approach in terms of both texture and geometry. Code and dataset is available at https://github.com/humansensinglab/FAMOUS.
GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

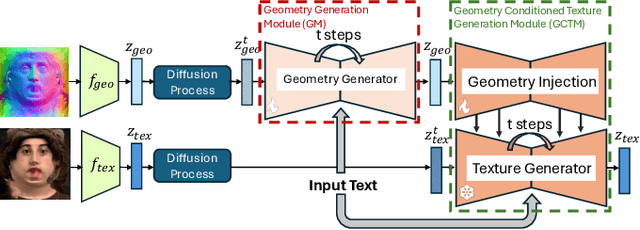
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention
Dec 06, 2023Face inpainting is important in various applications, such as photo restoration, image editing, and virtual reality. Despite the significant advances in face generative models, ensuring that a person's unique facial identity is maintained during the inpainting process is still an elusive goal. Current state-of-the-art techniques, exemplified by MyStyle, necessitate resource-intensive fine-tuning and a substantial number of images for each new identity. Furthermore, existing methods often fall short in accommodating user-specified semantic attributes, such as beard or expression. To improve inpainting results, and reduce the computational complexity during inference, this paper proposes the use of Parallel Visual Attention (PVA) in conjunction with diffusion models. Specifically, we insert parallel attention matrices to each cross-attention module in the denoising network, which attends to features extracted from reference images by an identity encoder. We train the added attention modules and identity encoder on CelebAHQ-IDI, a dataset proposed for identity-preserving face inpainting. Experiments demonstrate that PVA attains unparalleled identity resemblance in both face inpainting and face inpainting with language guidance tasks, in comparison to various benchmarks, including MyStyle, Paint by Example, and Custom Diffusion. Our findings reveal that PVA ensures good identity preservation while offering effective language-controllability. Additionally, in contrast to Custom Diffusion, PVA requires just 40 fine-tuning steps for each new identity, which translates to a significant speed increase of over 20 times.
SSDNeRF: Semantic Soft Decomposition of Neural Radiance Fields
Dec 07, 2022



Neural Radiance Fields (NeRFs) encode the radiance in a scene parameterized by the scene's plenoptic function. This is achieved by using an MLP together with a mapping to a higher-dimensional space, and has been proven to capture scenes with a great level of detail. Naturally, the same parameterization can be used to encode additional properties of the scene, beyond just its radiance. A particularly interesting property in this regard is the semantic decomposition of the scene. We introduce a novel technique for semantic soft decomposition of neural radiance fields (named SSDNeRF) which jointly encodes semantic signals in combination with radiance signals of a scene. Our approach provides a soft decomposition of the scene into semantic parts, enabling us to correctly encode multiple semantic classes blending along the same direction -- an impossible feat for existing methods. Not only does this lead to a detailed, 3D semantic representation of the scene, but we also show that the regularizing effects of the MLP used for encoding help to improve the semantic representation. We show state-of-the-art segmentation and reconstruction results on a dataset of common objects and demonstrate how the proposed approach can be applied for high quality temporally consistent video editing and re-compositing on a dataset of casually captured selfie videos.
Multiresolution Deep Implicit Functions for 3D Shape Representation
Sep 16, 2021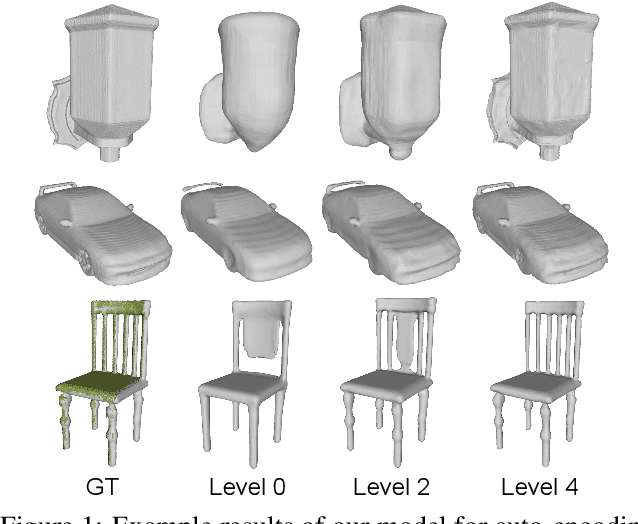
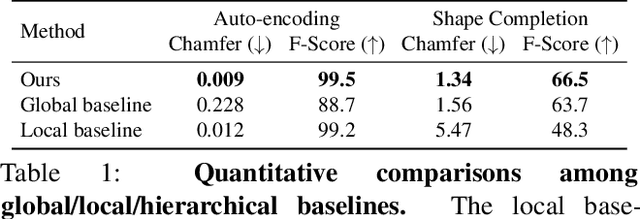
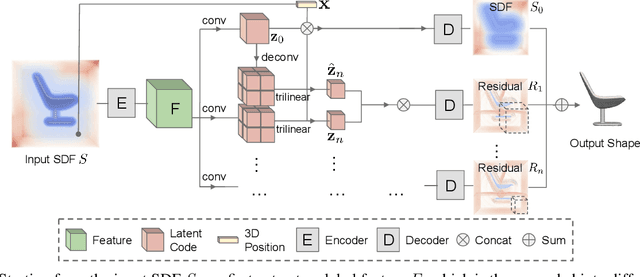
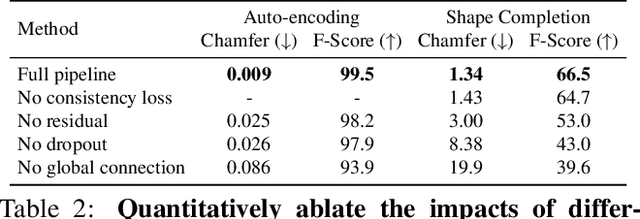
We introduce Multiresolution Deep Implicit Functions (MDIF), a hierarchical representation that can recover fine geometry detail, while being able to perform global operations such as shape completion. Our model represents a complex 3D shape with a hierarchy of latent grids, which can be decoded into different levels of detail and also achieve better accuracy. For shape completion, we propose latent grid dropout to simulate partial data in the latent space and therefore defer the completing functionality to the decoder side. This along with our multires design significantly improves the shape completion quality under decoder-only latent optimization. To the best of our knowledge, MDIF is the first deep implicit function model that can at the same time (1) represent different levels of detail and allow progressive decoding; (2) support both encoder-decoder inference and decoder-only latent optimization, and fulfill multiple applications; (3) perform detailed decoder-only shape completion. Experiments demonstrate its superior performance against prior art in various 3D reconstruction tasks.
Deep Implicit Volume Compression
May 18, 2020

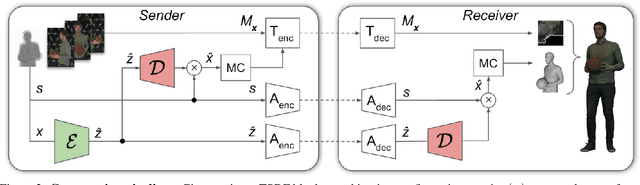
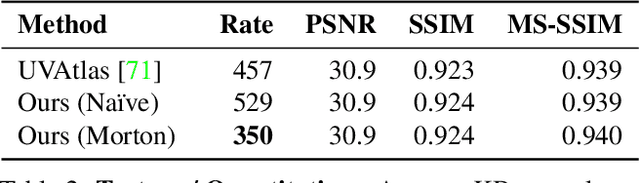
We describe a novel approach for compressing truncated signed distance fields (TSDF) stored in 3D voxel grids, and their corresponding textures. To compress the TSDF, our method relies on a block-based neural network architecture trained end-to-end, achieving state-of-the-art rate-distortion trade-off. To prevent topological errors, we losslessly compress the signs of the TSDF, which also upper bounds the reconstruction error by the voxel size. To compress the corresponding texture, we designed a fast block-based UV parameterization, generating coherent texture maps that can be effectively compressed using existing video compression algorithms. We demonstrate the performance of our algorithms on two 4D performance capture datasets, reducing bitrate by 66% for the same distortion, or alternatively reducing the distortion by 50% for the same bitrate, compared to the state-of-the-art.
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020
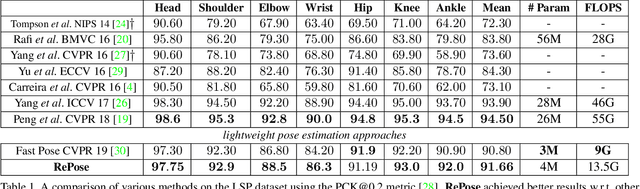
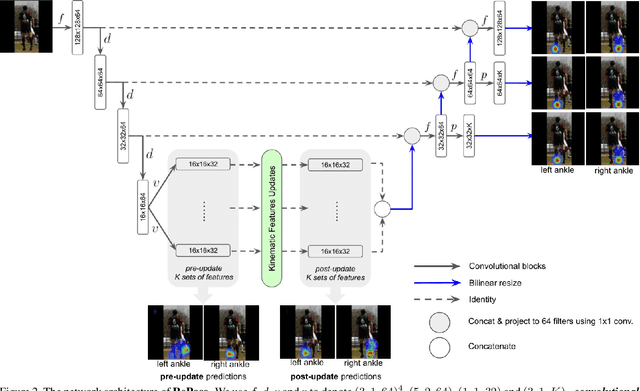
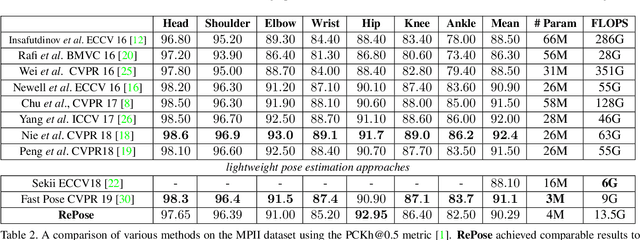
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
Jun 25, 2019
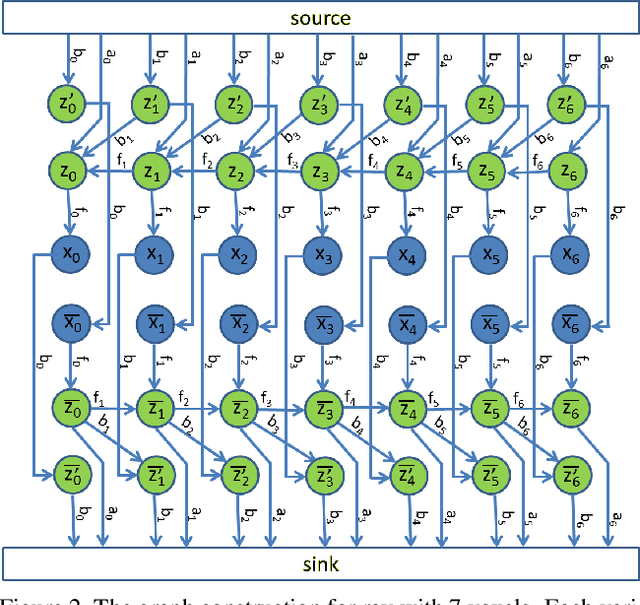

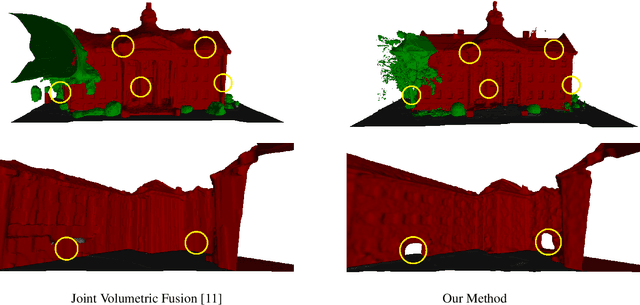
Dense semantic 3D reconstruction is typically formulated as a discrete or continuous problem over label assignments in a voxel grid, combining semantic and depth likelihoods in a Markov Random Field framework. The depth and semantic information is incorporated as a unary potential, smoothed by a pairwise regularizer. However, modelling likelihoods as a unary potential does not model the problem correctly leading to various undesirable visibility artifacts. We propose to formulate an optimization problem that directly optimizes the reprojection error of the 3D model with respect to the image estimates, which corresponds to the optimization over rays, where the cost function depends on the semantic class and depth of the first occupied voxel along the ray. The 2-label formulation is made feasible by transforming it into a graph-representable form under QPBO relaxation, solvable using graph cut. The multi-label problem is solved by applying alpha-expansion using the same relaxation in each expansion move. Our method was indeed shown to be feasible in practice, running comparably fast to the competing methods, while not suffering from ray potential approximation artifacts.
Learning Independent Object Motion from Unlabelled Stereoscopic Videos
Jan 08, 2019

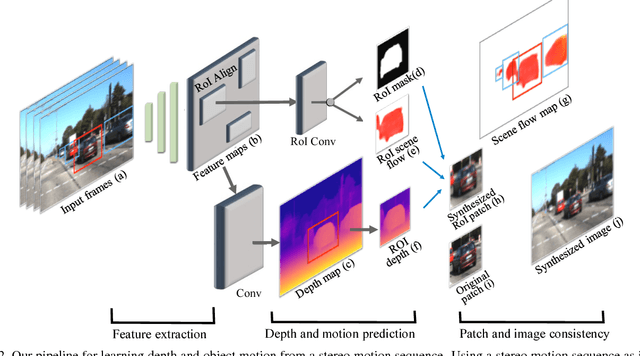

We present a system for learning motion of independently moving objects from stereo videos. The only human annotation used in our system are 2D object bounding boxes which introduce the notion of objects to our system. Unlike prior learning based work which has focused on predicting dense pixel-wise optical flow field and/or a depth map for each image, we propose to predict object instance specific 3D scene flow maps and instance masks from which we are able to derive the motion direction and speed for each object instance. Our network takes the 3D geometry of the problem into account which allows it to correlate the input images. We present experiments evaluating the accuracy of our 3D flow vectors, as well as depth maps and projected 2D optical flow where our jointly learned system outperforms earlier approaches trained for each task independently.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
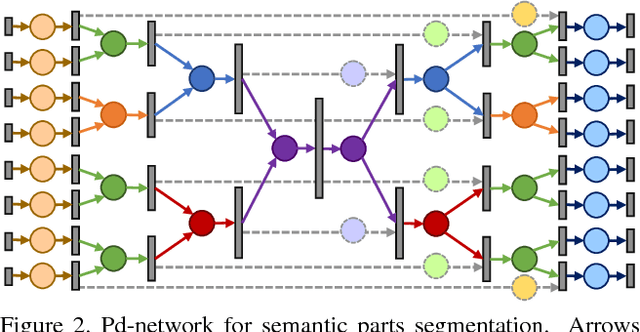
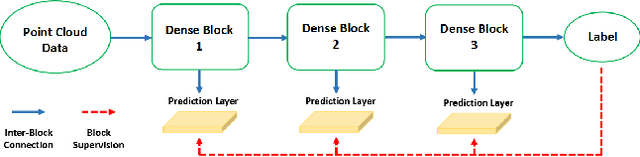
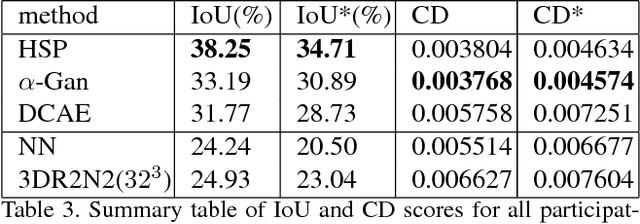
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.