 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAMOUS: High-Fidelity Monocular 3D Human Digitization Using View Synthesis
Oct 13, 2024The advancement in deep implicit modeling and articulated models has significantly enhanced the process of digitizing human figures in 3D from just a single image. While state-of-the-art methods have greatly improved geometric precision, the challenge of accurately inferring texture remains, particularly in obscured areas such as the back of a person in frontal-view images. This limitation in texture prediction largely stems from the scarcity of large-scale and diverse 3D datasets, whereas their 2D counterparts are abundant and easily accessible. To address this issue, our paper proposes leveraging extensive 2D fashion datasets to enhance both texture and shape prediction in 3D human digitization. We incorporate 2D priors from the fashion dataset to learn the occluded back view, refined with our proposed domain alignment strategy. We then fuse this information with the input image to obtain a fully textured mesh of the given person. Through extensive experimentation on standard 3D human benchmarks, we demonstrate the superior performance of our approach in terms of both texture and geometry. Code and dataset is available at https://github.com/humansensinglab/FAMOUS.
Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention
Dec 06, 2023Face inpainting is important in various applications, such as photo restoration, image editing, and virtual reality. Despite the significant advances in face generative models, ensuring that a person's unique facial identity is maintained during the inpainting process is still an elusive goal. Current state-of-the-art techniques, exemplified by MyStyle, necessitate resource-intensive fine-tuning and a substantial number of images for each new identity. Furthermore, existing methods often fall short in accommodating user-specified semantic attributes, such as beard or expression. To improve inpainting results, and reduce the computational complexity during inference, this paper proposes the use of Parallel Visual Attention (PVA) in conjunction with diffusion models. Specifically, we insert parallel attention matrices to each cross-attention module in the denoising network, which attends to features extracted from reference images by an identity encoder. We train the added attention modules and identity encoder on CelebAHQ-IDI, a dataset proposed for identity-preserving face inpainting. Experiments demonstrate that PVA attains unparalleled identity resemblance in both face inpainting and face inpainting with language guidance tasks, in comparison to various benchmarks, including MyStyle, Paint by Example, and Custom Diffusion. Our findings reveal that PVA ensures good identity preservation while offering effective language-controllability. Additionally, in contrast to Custom Diffusion, PVA requires just 40 fine-tuning steps for each new identity, which translates to a significant speed increase of over 20 times.
MMG-Ego4D: Multi-Modal Generalization in Egocentric Action Recognition
May 12, 2023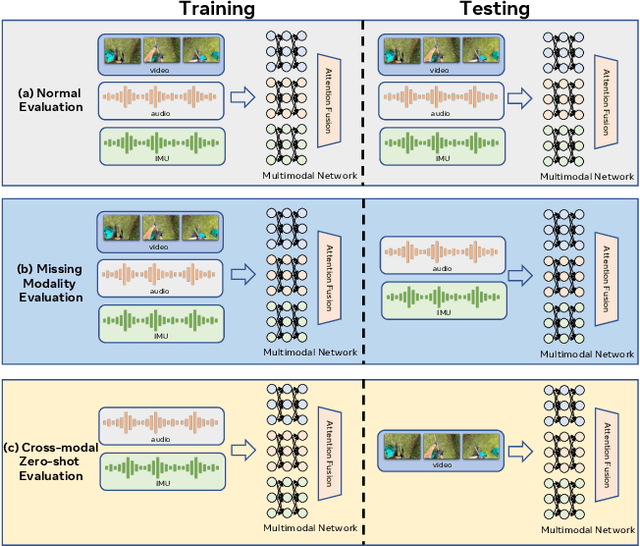

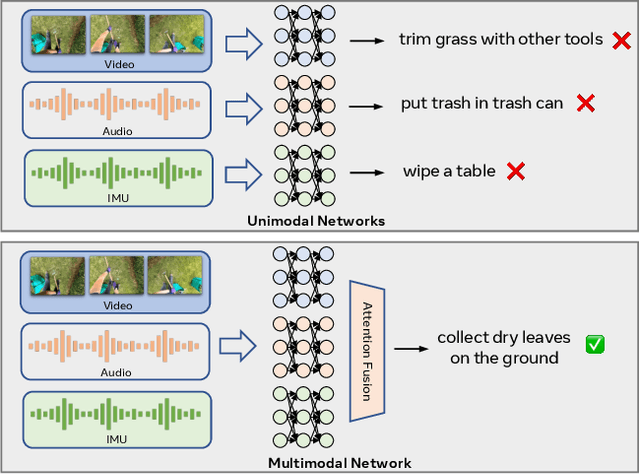
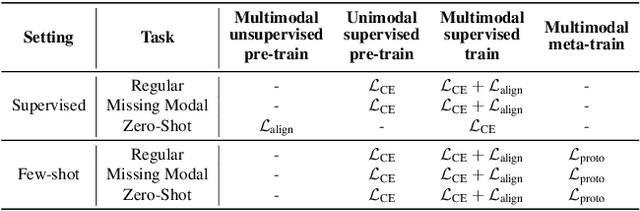
In this paper, we study a novel problem in egocentric action recognition, which we term as "Multimodal Generalization" (MMG). MMG aims to study how systems can generalize when data from certain modalities is limited or even completely missing. We thoroughly investigate MMG in the context of standard supervised action recognition and the more challenging few-shot setting for learning new action categories. MMG consists of two novel scenarios, designed to support security, and efficiency considerations in real-world applications: (1) missing modality generalization where some modalities that were present during the train time are missing during the inference time, and (2) cross-modal zero-shot generalization, where the modalities present during the inference time and the training time are disjoint. To enable this investigation, we construct a new dataset MMG-Ego4D containing data points with video, audio, and inertial motion sensor (IMU) modalities. Our dataset is derived from Ego4D dataset, but processed and thoroughly re-annotated by human experts to facilitate research in the MMG problem. We evaluate a diverse array of models on MMG-Ego4D and propose new methods with improved generalization ability. In particular, we introduce a new fusion module with modality dropout training, contrastive-based alignment training, and a novel cross-modal prototypical loss for better few-shot performance. We hope this study will serve as a benchmark and guide future research in multimodal generalization problems. The benchmark and code will be available at https://github.com/facebookresearch/MMG_Ego4D.
SSDNeRF: Semantic Soft Decomposition of Neural Radiance Fields
Dec 07, 2022



Neural Radiance Fields (NeRFs) encode the radiance in a scene parameterized by the scene's plenoptic function. This is achieved by using an MLP together with a mapping to a higher-dimensional space, and has been proven to capture scenes with a great level of detail. Naturally, the same parameterization can be used to encode additional properties of the scene, beyond just its radiance. A particularly interesting property in this regard is the semantic decomposition of the scene. We introduce a novel technique for semantic soft decomposition of neural radiance fields (named SSDNeRF) which jointly encodes semantic signals in combination with radiance signals of a scene. Our approach provides a soft decomposition of the scene into semantic parts, enabling us to correctly encode multiple semantic classes blending along the same direction -- an impossible feat for existing methods. Not only does this lead to a detailed, 3D semantic representation of the scene, but we also show that the regularizing effects of the MLP used for encoding help to improve the semantic representation. We show state-of-the-art segmentation and reconstruction results on a dataset of common objects and demonstrate how the proposed approach can be applied for high quality temporally consistent video editing and re-compositing on a dataset of casually captured selfie videos.
A Deep Perceptual Measure for Lens and Camera Calibration
Aug 25, 2022


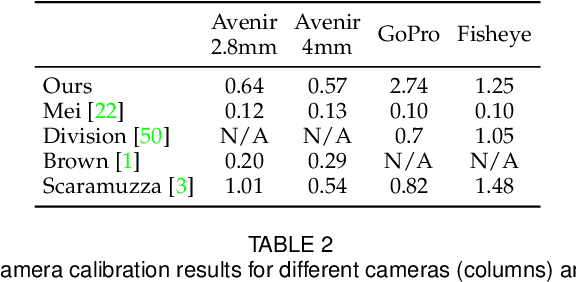
Image editing and compositing have become ubiquitous in entertainment, from digital art to AR and VR experiences. To produce beautiful composites, the camera needs to be geometrically calibrated, which can be tedious and requires a physical calibration target. In place of the traditional multi-images calibration process, we propose to infer the camera calibration parameters such as pitch, roll, field of view, and lens distortion directly from a single image using a deep convolutional neural network. We train this network using automatically generated samples from a large-scale panorama dataset, yielding competitive accuracy in terms of standard l2 error. However, we argue that minimizing such standard error metrics might not be optimal for many applications. In this work, we investigate human sensitivity to inaccuracies in geometric camera calibration. To this end, we conduct a large-scale human perception study where we ask participants to judge the realism of 3D objects composited with correct and biased camera calibration parameters. Based on this study, we develop a new perceptual measure for camera calibration and demonstrate that our deep calibration network outperforms previous single-image based calibration methods both on standard metrics as well as on this novel perceptual measure. Finally, we demonstrate the use of our calibration network for several applications, including virtual object insertion, image retrieval, and compositing. A demonstration of our approach is available at https://lvsn.github.io/deepcalib .
Sampling Based Scene-Space Video Processing
Feb 05, 2021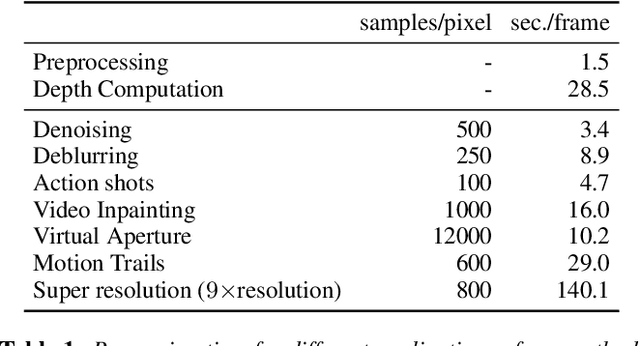

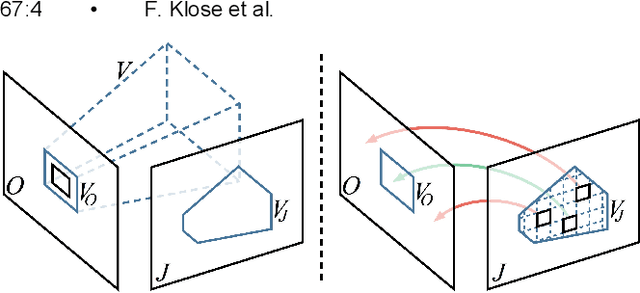
Many compelling video processing effects can be achieved if per-pixel depth information and 3D camera calibrations are known. However, the success of such methods is highly dependent on the accuracy of this "scene-space" information. We present a novel, sampling-based framework for processing video that enables high-quality scene-space video effects in the presence of inevitable errors in depth and camera pose estimation. Instead of trying to improve the explicit 3D scene representation, the key idea of our method is to exploit the high redundancy of approximate scene information that arises due to most scene points being visible multiple times across many frames of video. Based on this observation, we propose a novel pixel gathering and filtering approach. The gathering step is general and collects pixel samples in scene-space, while the filtering step is application-specific and computes a desired output video from the gathered sample sets. Our approach is easily parallelizable and has been implemented on GPU, allowing us to take full advantage of large volumes of video data and facilitating practical runtimes on HD video using a standard desktop computer. Our generic scene-space formulation is able to comprehensively describe a multitude of video processing applications such as denoising, deblurring, super resolution, object removal, computational shutter functions, and other scene-space camera effects. We present results for various casually captured, hand-held, moving, compressed, monocular videos depicting challenging scenes recorded in uncontrolled environments.
ResNet or DenseNet? Introducing Dense Shortcuts to ResNet
Oct 23, 2020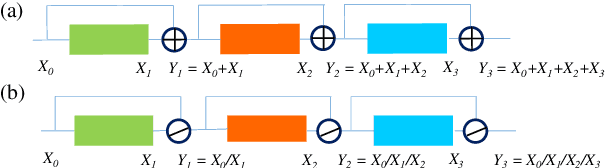

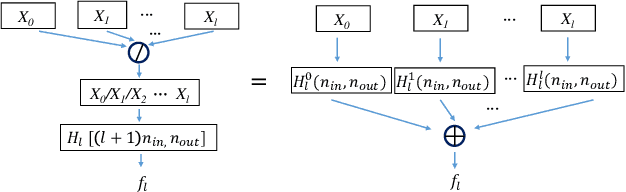

ResNet or DenseNet? Nowadays, most deep learning based approaches are implemented with seminal backbone networks, among them the two arguably most famous ones are ResNet and DenseNet. Despite their competitive performance and overwhelming popularity, inherent drawbacks exist for both of them. For ResNet, the identity shortcut that stabilizes training also limits its representation capacity, while DenseNet has a higher capacity with multi-layer feature concatenation. However, the dense concatenation causes a new problem of requiring high GPU memory and more training time. Partially due to this, it is not a trivial choice between ResNet and DenseNet. This paper provides a unified perspective of dense summation to analyze them, which facilitates a better understanding of their core difference. We further propose dense weighted normalized shortcuts as a solution to the dilemma between them. Our proposed dense shortcut inherits the design philosophy of simple design in ResNet and DenseNet. On several benchmark datasets, the experimental results show that the proposed DSNet achieves significantly better results than ResNet, and achieves comparable performance as DenseNet but requiring fewer computation resources.
Partial Sum Minimization of Singular Values in Robust PCA: Algorithm and Applications
Aug 13, 2015
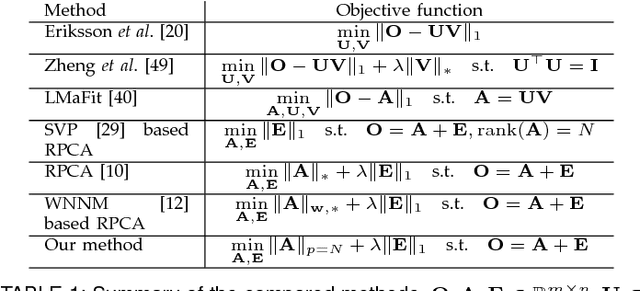
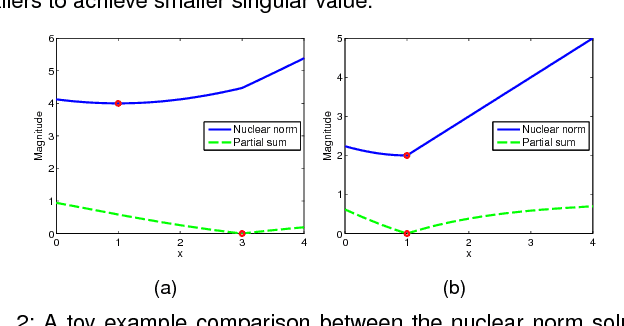

Robust Principal Component Analysis (RPCA) via rank minimization is a powerful tool for recovering underlying low-rank structure of clean data corrupted with sparse noise/outliers. In many low-level vision problems, not only it is known that the underlying structure of clean data is low-rank, but the exact rank of clean data is also known. Yet, when applying conventional rank minimization for those problems, the objective function is formulated in a way that does not fully utilize a priori target rank information about the problems. This observation motivates us to investigate whether there is a better alternative solution when using rank minimization. In this paper, instead of minimizing the nuclear norm, we propose to minimize the partial sum of singular values, which implicitly encourages the target rank constraint. Our experimental analyses show that, when the number of samples is deficient, our approach leads to a higher success rate than conventional rank minimization, while the solutions obtained by the two approaches are almost identical when the number of samples is more than sufficient. We apply our approach to various low-level vision problems, e.g. high dynamic range imaging, motion edge detection, photometric stereo, image alignment and recovery, and show that our results outperform those obtained by the conventional nuclear norm rank minimization method.