 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaLDiff: Camera Localization in NeRF via Pose Diffusion
Dec 23, 2023With the widespread use of NeRF-based implicit 3D representation, the need for camera localization in the same representation becomes manifestly apparent. Doing so not only simplifies the localization process -- by avoiding an outside-the-NeRF-based localization -- but also has the potential to offer the benefit of enhanced localization. This paper studies the problem of localizing cameras in NeRF using a diffusion model for camera pose adjustment. More specifically, given a pre-trained NeRF model, we train a diffusion model that iteratively updates randomly initialized camera poses, conditioned upon the image to be localized. At test time, a new camera is localized in two steps: first, coarse localization using the proposed pose diffusion process, followed by local refinement steps of a pose inversion process in NeRF. In fact, the proposed camera localization by pose diffusion (CaLDiff) method also integrates the pose inversion steps within the diffusion process. Such integration offers significantly better localization, thanks to our downstream refinement-aware diffusion process. Our exhaustive experiments on challenging real-world data validate our method by providing significantly better results than the compared methods and the established baselines. Our source code will be made publicly available.
A Deep Perceptual Measure for Lens and Camera Calibration
Aug 25, 2022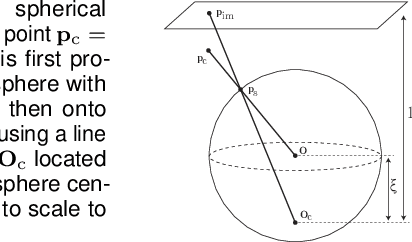


Image editing and compositing have become ubiquitous in entertainment, from digital art to AR and VR experiences. To produce beautiful composites, the camera needs to be geometrically calibrated, which can be tedious and requires a physical calibration target. In place of the traditional multi-images calibration process, we propose to infer the camera calibration parameters such as pitch, roll, field of view, and lens distortion directly from a single image using a deep convolutional neural network. We train this network using automatically generated samples from a large-scale panorama dataset, yielding competitive accuracy in terms of standard l2 error. However, we argue that minimizing such standard error metrics might not be optimal for many applications. In this work, we investigate human sensitivity to inaccuracies in geometric camera calibration. To this end, we conduct a large-scale human perception study where we ask participants to judge the realism of 3D objects composited with correct and biased camera calibration parameters. Based on this study, we develop a new perceptual measure for camera calibration and demonstrate that our deep calibration network outperforms previous single-image based calibration methods both on standard metrics as well as on this novel perceptual measure. Finally, we demonstrate the use of our calibration network for several applications, including virtual object insertion, image retrieval, and compositing. A demonstration of our approach is available at https://lvsn.github.io/deepcalib .