 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Based Neural-Augmented Kalman Filter for Legged Robot State Estimation
Jan 26, 2026In this letter, we propose an Attention-Based Neural-Augmented Kalman Filter (AttenNKF) for state estimation in legged robots. Foot slip is a major source of estimation error: when slip occurs, kinematic measurements violate the no-slip assumption and inject bias during the update step. Our objective is to estimate this slip-induced error and compensate for it. To this end, we augment an Invariant Extended Kalman Filter (InEKF) with a neural compensator that uses an attention mechanism to infer error conditioned on foot-slip severity and then applies this estimate as a post-update compensation to the InEKF state (i.e., after the filter update). The compensator is trained in a latent space, which aims to reduce sensitivity to raw input scales and encourages structured slip-conditioned compensations, while preserving the InEKF recursion. Experiments demonstrate improved performance compared to existing legged-robot state estimators, particularly under slip-prone conditions.
Temperature Compensation Method of Six-Axis Force/Torque Sensor Using Gated Recurrent Unit
Feb 24, 2025



This study aims to enhance the accuracy of a six-axis force/torque sensor compared to existing approaches that utilize Multi-Layer Perceptron (MLP) and the Least Square Method. The sensor used in this study is based on a photo-coupler and operates with infrared light, making it susceptible to dark current effects, which cause drift due to temperature variations. Additionally, the sensor is compact and lightweight (45g), resulting in a low thermal capacity. Consequently, even small amounts of heat can induce rapid temperature changes, affecting the sensor's performance in real time. To address these challenges, this study compares the conventional MLP approach with the proposed Gated Recurrent Unit (GRU)-based method. Experimental results demonstrate that the GRU approach, leveraging sequential data, achieves superior performance.
AAPL: Adding Attributes to Prompt Learning for Vision-Language Models
Apr 25, 2024



Recent advances in large pre-trained vision-language models have demonstrated remarkable performance on zero-shot downstream tasks. Building upon this, recent studies, such as CoOp and CoCoOp, have proposed the use of prompt learning, where context within a prompt is replaced with learnable vectors, leading to significant improvements over manually crafted prompts. However, the performance improvement for unseen classes is still marginal, and to tackle this problem, data augmentation has been frequently used in traditional zero-shot learning techniques. Through our experiments, we have identified important issues in CoOp and CoCoOp: the context learned through traditional image augmentation is biased toward seen classes, negatively impacting generalization to unseen classes. To address this problem, we propose adversarial token embedding to disentangle low-level visual augmentation features from high-level class information when inducing bias in learnable prompts. Through our novel mechanism called "Adding Attributes to Prompt Learning", AAPL, we guide the learnable context to effectively extract text features by focusing on high-level features for unseen classes. We have conducted experiments across 11 datasets, and overall, AAPL shows favorable performances compared to the existing methods in few-shot learning, zero-shot learning, cross-dataset, and domain generalization tasks.
Latent Inversion with Timestep-aware Sampling for Training-free Non-rigid Editing
Feb 14, 2024



Text-guided non-rigid editing involves complex edits for input images, such as changing motion or compositions within their surroundings. Since it requires manipulating the input structure, existing methods often struggle with preserving object identity and background, particularly when combined with Stable Diffusion. In this work, we propose a training-free approach for non-rigid editing with Stable Diffusion, aimed at improving the identity preservation quality without compromising editability. Our approach comprises three stages: text optimization, latent inversion, and timestep-aware text injection sampling. Inspired by the recent success of Imagic, we employ their text optimization for smooth editing. Then, we introduce latent inversion to preserve the input image's identity without additional model fine-tuning. To fully utilize the input reconstruction ability of latent inversion, we suggest timestep-aware text inject sampling. This effectively retains the structure of the input image by injecting the source text prompt in early sampling steps and then transitioning to the target prompt in subsequent sampling steps. This strategic approach seamlessly harmonizes with text optimization, facilitating complex non-rigid edits to the input without losing the original identity. We demonstrate the effectiveness of our method in terms of identity preservation, editability, and aesthetic quality through extensive experiments.
CLIP Can Understand Depth
Feb 05, 2024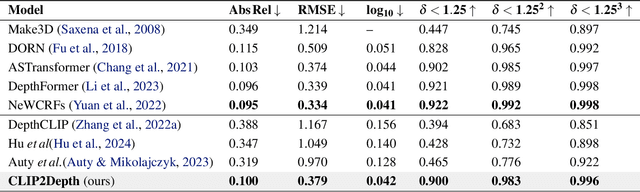
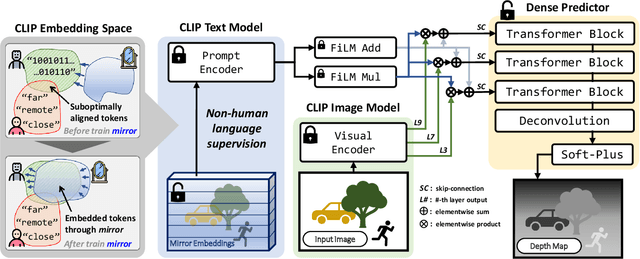
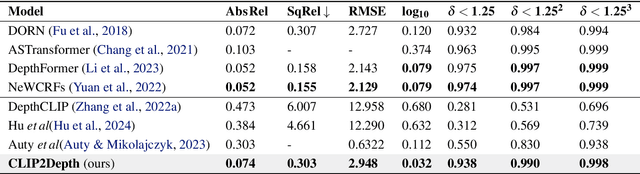

Recent studies on generalizing CLIP for monocular depth estimation reveal that CLIP pre-trained on web-crawled data is inefficient for deriving proper similarities between image patches and depth-related prompts. In this paper, we adapt CLIP for meaningful quality of monocular depth estimation with dense prediction, without fine-tuning its original vision-language alignment. By jointly training a compact deconvolutional decoder with a tiny learnable embedding matrix named mirror, as a static prompt for its text encoder, CLIP is enabled to understand depth. With this approach, our model exhibits impressive performance matching several previous state-of-the-art vision-only models on the NYU Depth v2 and KITTI datasets, outperforming every CLIP-based depth estimation model with a large margin. Experiments on temporal depth consistency and spatial continuity demonstrate that the prior knowledge of CLIP can be effectively refined by our proposed framework. Furthermore, an ablation study on mirror proves that the resulting model estimates depth utilizing knowledge not only from the image encoder but also text encoder despite not being given any prompt written in a human way. This research demonstrates that through minimal adjustments, the prior knowledge of vision-language foundation models, such as CLIP, can be generalized even to domains where learning during pretraining is challenging. We facilitate future works focused on methods to adjust suboptimal prior knowledge of vision-language models using non-human language prompts, achieving performance on par with task-specific state-of-the-art methodologies.
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Sep 21, 2023



Unsupervised domain adaptation (UDA) is an effective approach to handle the lack of annotations in the target domain for the semantic segmentation task. In this work, we consider a more practical UDA setting where the target domain contains sequential frames of the unlabeled videos which are easy to collect in practice. A recent study suggests self-supervised learning of the object motion from unlabeled videos with geometric constraints. We design a motion-guided domain adaptive semantic segmentation framework (MoDA), that utilizes self-supervised object motion to learn effective representations in the target domain. MoDA differs from previous methods that use temporal consistency regularization for the target domain frames. Instead, MoDA deals separately with the domain alignment on the foreground and background categories using different strategies. Specifically, MoDA contains foreground object discovery and foreground semantic mining to align the foreground domain gaps by taking the instance-level guidance from the object motion. Additionally, MoDA includes background adversarial training which contains a background category-specific discriminator to handle the background domain gaps. Experimental results on multiple benchmarks highlight the effectiveness of MoDA against existing approaches in the domain adaptive image segmentation and domain adaptive video segmentation. Moreover, MoDA is versatile and can be used in conjunction with existing state-of-the-art approaches to further improve performance.
ML-BPM: Multi-teacher Learning with Bidirectional Photometric Mixing for Open Compound Domain Adaptation in Semantic Segmentation
Jul 19, 2022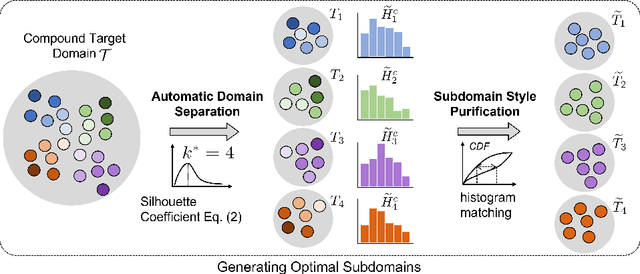
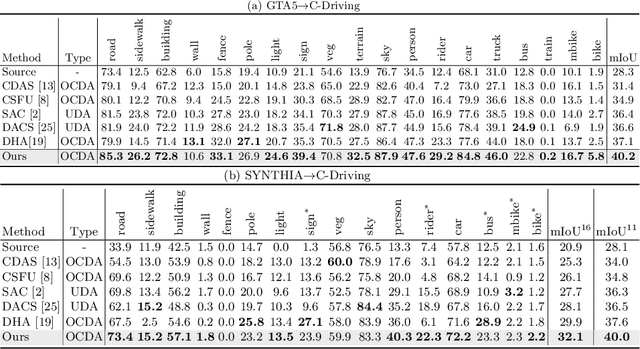

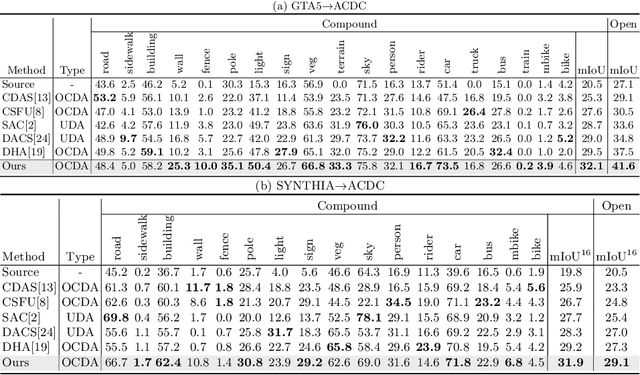
Open compound domain adaptation (OCDA) considers the target domain as the compound of multiple unknown homogeneous subdomains. The goal of OCDA is to minimize the domain gap between the labeled source domain and the unlabeled compound target domain, which benefits the model generalization to the unseen domains. Current OCDA for semantic segmentation methods adopt manual domain separation and employ a single model to simultaneously adapt to all the target subdomains. However, adapting to a target subdomain might hinder the model from adapting to other dissimilar target subdomains, which leads to limited performance. In this work, we introduce a multi-teacher framework with bidirectional photometric mixing to separately adapt to every target subdomain. First, we present an automatic domain separation to find the optimal number of subdomains. On this basis, we propose a multi-teacher framework in which each teacher model uses bidirectional photometric mixing to adapt to one target subdomain. Furthermore, we conduct an adaptive distillation to learn a student model and apply consistency regularization to improve the student generalization. Experimental results on benchmark datasets show the efficacy of the proposed approach for both the compound domain and the open domains against existing state-of-the-art approaches.
Attentive and Contrastive Learning for Joint Depth and Motion Field Estimation
Oct 13, 2021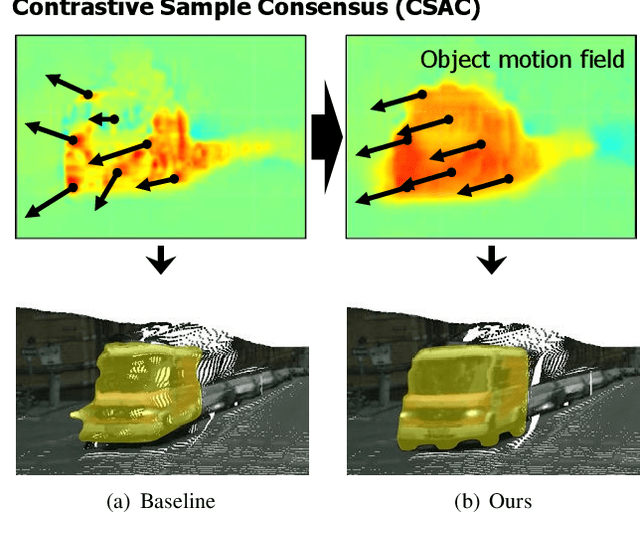
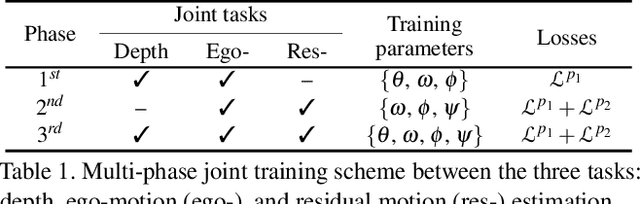
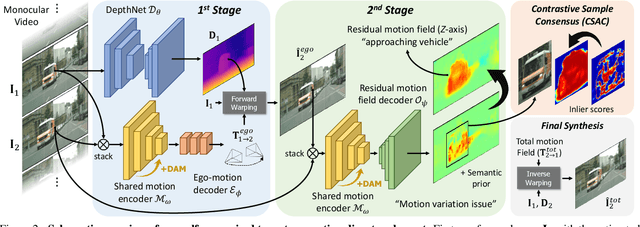

Estimating the motion of the camera together with the 3D structure of the scene from a monocular vision system is a complex task that often relies on the so-called scene rigidity assumption. When observing a dynamic environment, this assumption is violated which leads to an ambiguity between the ego-motion of the camera and the motion of the objects. To solve this problem, we present a self-supervised learning framework for 3D object motion field estimation from monocular videos. Our contributions are two-fold. First, we propose a two-stage projection pipeline to explicitly disentangle the camera ego-motion and the object motions with dynamics attention module, called DAM. Specifically, we design an integrated motion model that estimates the motion of the camera and object in the first and second warping stages, respectively, controlled by the attention module through a shared motion encoder. Second, we propose an object motion field estimation through contrastive sample consensus, called CSAC, taking advantage of weak semantic prior (bounding box from an object detector) and geometric constraints (each object respects the rigid body motion model). Experiments on KITTI, Cityscapes, and Waymo Open Dataset demonstrate the relevance of our approach and show that our method outperforms state-of-the-art algorithms for the tasks of self-supervised monocular depth estimation, object motion segmentation, monocular scene flow estimation, and visual odometry.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021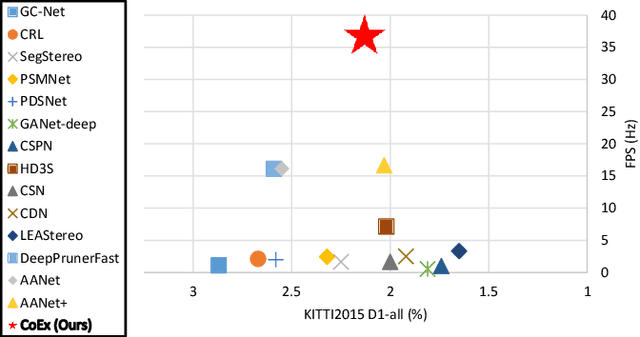
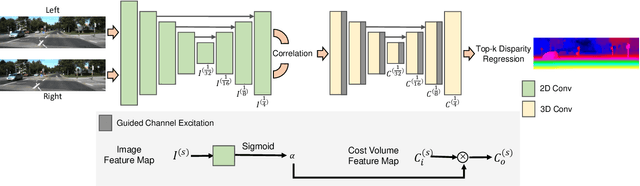

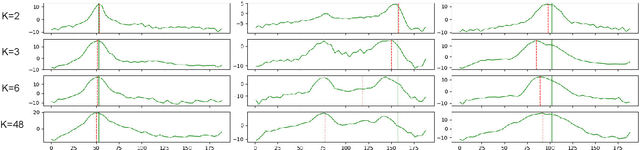
Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.
Unsupervised Depth and Ego-motion Estimation for Monocular Thermal Video using Multi-spectral Consistency Loss
Mar 03, 2021
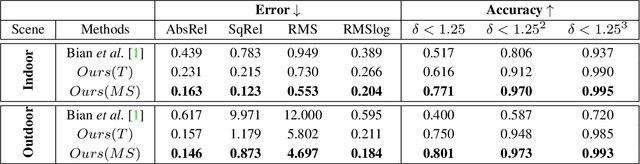

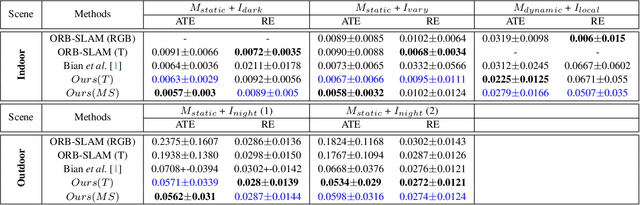
Most of the deep-learning based depth and ego-motion networks have been designed for visible cameras. However, visible cameras heavily rely on the presence of an external light source. Therefore, it is challenging to use them under low-light conditions such as night scenes, tunnels, and other harsh conditions. A thermal camera is one solution to compensate for this problem because it detects Long Wave Infrared Radiation(LWIR) regardless of any external light sources. However, despite this advantage, both depth and ego-motion estimation research for the thermal camera are not actively explored until so far. In this paper, we propose an unsupervised learning method for the all-day depth and ego-motion estimation. The proposed method exploits multi-spectral consistency loss to gives complementary supervision for the networks by reconstructing visible and thermal images with the depth and pose estimated from thermal images. The networks trained with the proposed method robustly estimate the depth and pose from monocular thermal video under low-light and even zero-light conditions. To the best of our knowledge, this is the first work to simultaneously estimate both depth and ego-motion from the monocular thermal video in an unsupervised manner.