 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualRefine: Self-Supervised Depth and Pose Estimation Through Iterative Epipolar Sampling and Refinement Toward Equilibrium
Apr 07, 2023Self-supervised multi-frame depth estimation achieves high accuracy by computing matching costs of pixel correspondences between adjacent frames, injecting geometric information into the network. These pixel-correspondence candidates are computed based on the relative pose estimates between the frames. Accurate pose predictions are essential for precise matching cost computation as they influence the epipolar geometry. Furthermore, improved depth estimates can, in turn, be used to align pose estimates. Inspired by traditional structure-from-motion (SfM) principles, we propose the DualRefine model, which tightly couples depth and pose estimation through a feedback loop. Our novel update pipeline uses a deep equilibrium model framework to iteratively refine depth estimates and a hidden state of feature maps by computing local matching costs based on epipolar geometry. Importantly, we used the refined depth estimates and feature maps to compute pose updates at each step. This update in the pose estimates slowly alters the epipolar geometry during the refinement process. Experimental results on the KITTI dataset demonstrate competitive depth prediction and odometry prediction performance surpassing published self-supervised baselines.
DGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Feb 26, 2022

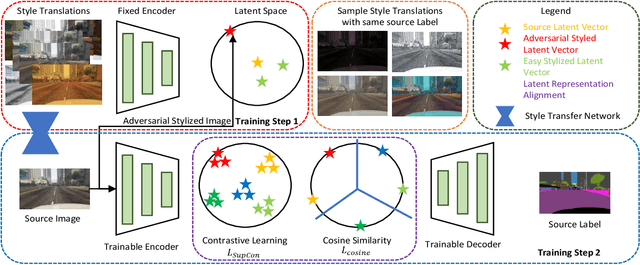

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021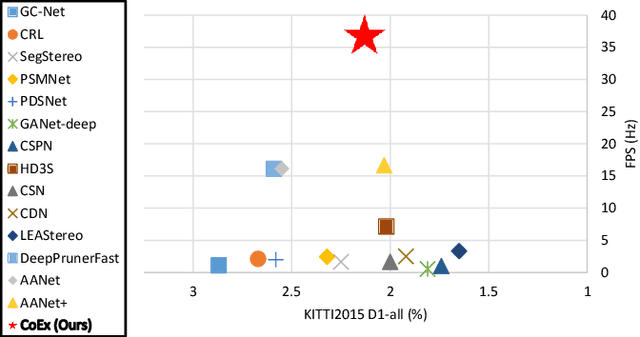
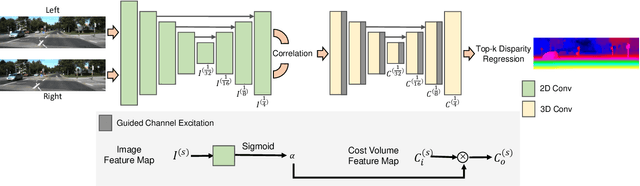

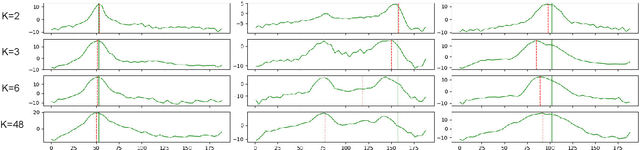
Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.
Retaining Image Feature Matching Performance Under Low Light Conditions
Sep 02, 2020
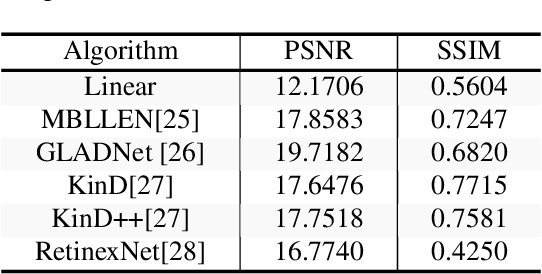

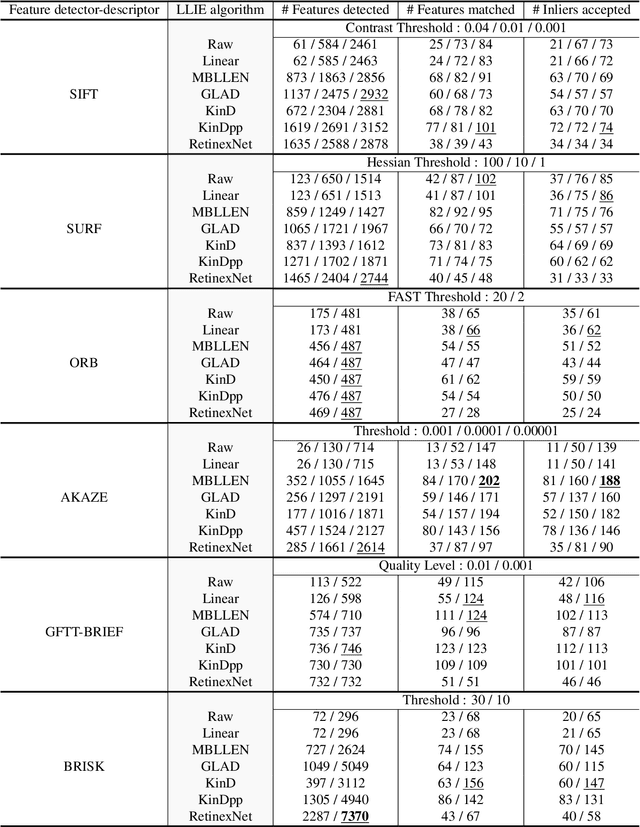
Poor image quality in low light images may result in a reduced number of feature matching between images. In this paper, we investigate the performance of feature extraction algorithms in low light environments. To find an optimal setting to retain feature matching performance in low light images, we look into the effect of changing feature acceptance threshold for feature detector and adding pre-processing in the form of Low Light Image Enhancement (LLIE) prior to feature detection. We observe that even in low light images, feature matching using traditional hand-crafted feature detectors still performs reasonably well by lowering the threshold parameter. We also show that applying Low Light Image Enhancement (LLIE) algorithms can improve feature matching even more when paired with the right feature extraction algorithm.