 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight HDR Camera ISP for Robust Perception in Dynamic Illumination Conditions via Fourier Adversarial Networks
Apr 04, 2022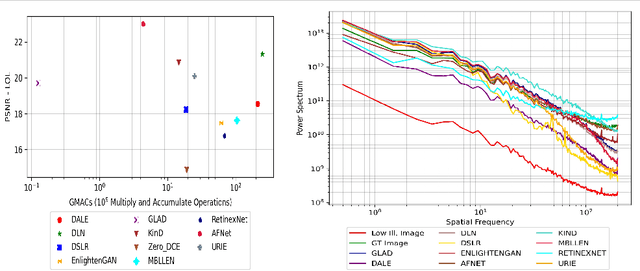
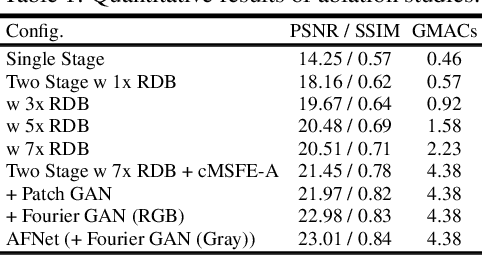
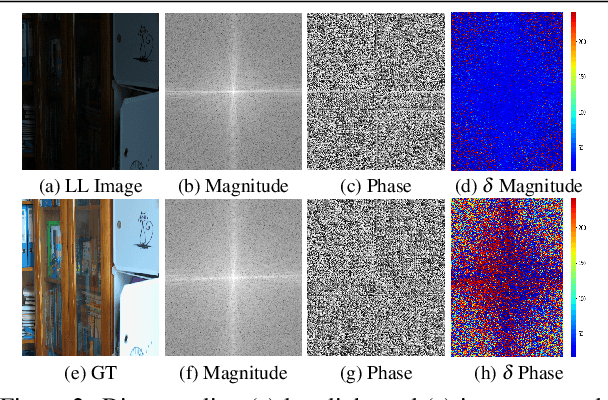
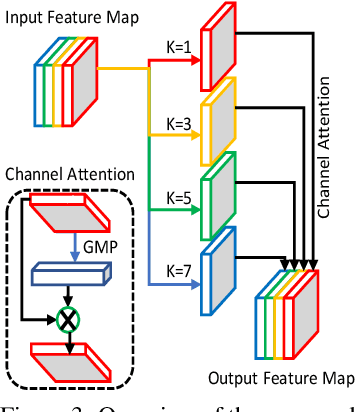
The limited dynamic range of commercial compact camera sensors results in an inaccurate representation of scenes with varying illumination conditions, adversely affecting image quality and subsequently limiting the performance of underlying image processing algorithms. Current state-of-the-art (SoTA) convolutional neural networks (CNN) are developed as post-processing techniques to independently recover under-/over-exposed images. However, when applied to images containing real-world degradations such as glare, high-beam, color bleeding with varying noise intensity, these algorithms amplify the degradations, further degrading image quality. We propose a lightweight two-stage image enhancement algorithm sequentially balancing illumination and noise removal using frequency priors for structural guidance to overcome these limitations. Furthermore, to ensure realistic image quality, we leverage the relationship between frequency and spatial domain properties of an image and propose a Fourier spectrum-based adversarial framework (AFNet) for consistent image enhancement under varying illumination conditions. While current formulations of image enhancement are envisioned as post-processing techniques, we examine if such an algorithm could be extended to integrate the functionality of the Image Signal Processing (ISP) pipeline within the camera sensor benefiting from RAW sensor data and lightweight CNN architecture. Based on quantitative and qualitative evaluations, we also examine the practicality and effects of image enhancement techniques on the performance of common perception tasks such as object detection and semantic segmentation in varying illumination conditions.
DGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Feb 26, 2022

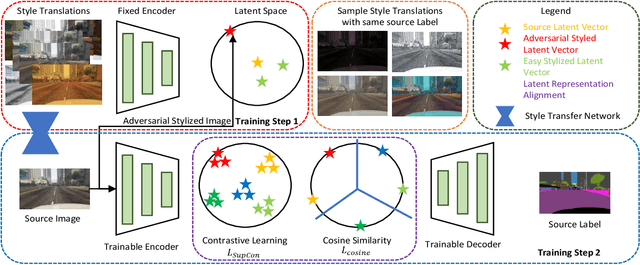

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.
Evaluating COPY-BLEND Augmentation for Low Level Vision Tasks
Mar 10, 2021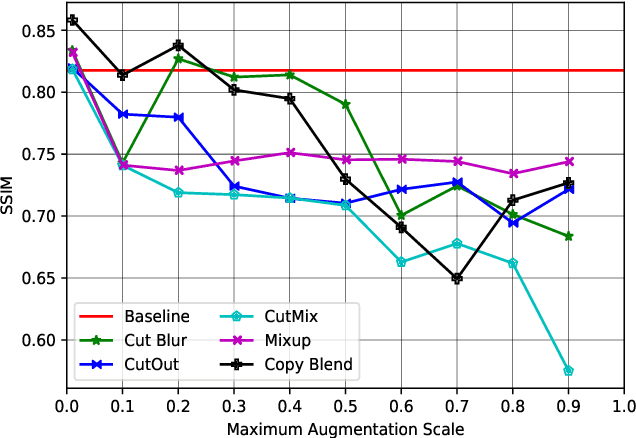
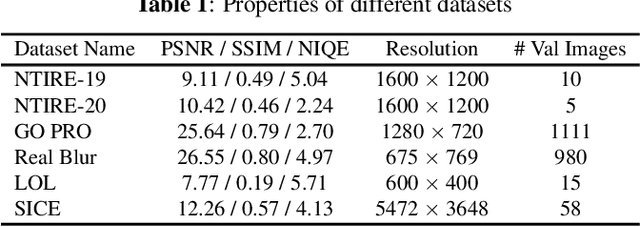

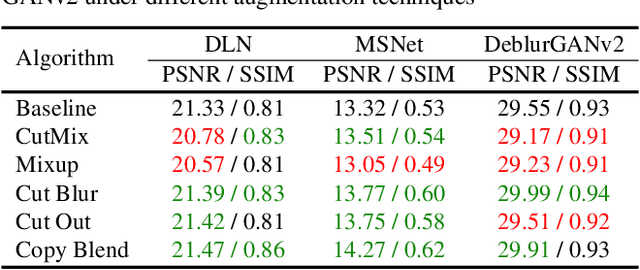
Region modification-based data augmentation techniques have shown to improve performance for high level vision tasks (object detection, semantic segmentation, image classification, etc.) by encouraging underlying algorithms to focus on multiple discriminative features. However, as these techniques destroy spatial relationship with neighboring regions, performance can be deteriorated when using them to train algorithms designed for low level vision tasks (low light image enhancement, image dehazing, deblurring, etc.) where textural consistency between recovered and its neighboring regions is important to ensure effective performance. In this paper, we examine the efficacy of a simple copy-blend data augmentation technique that copies patches from noisy images and blends onto a clean image and vice versa to ensure that an underlying algorithm localizes and recovers affected regions resulting in increased perceptual quality of a recovered image. To assess performance improvement, we perform extensive experiments alongside different region modification-based augmentation techniques and report observations such as improved performance, reduced requirement for training dataset, and early convergence across tasks such as low light image enhancement, image dehazing and image deblurring without any modification to baseline algorithm.
Towards Domain Invariant Single Image Dehazing
Jan 09, 2021


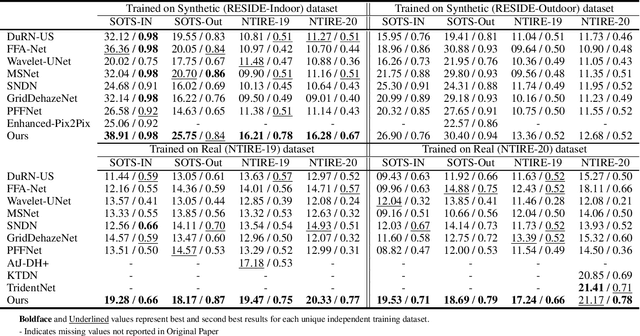
Presence of haze in images obscures underlying information, which is undesirable in applications requiring accurate environment information. To recover such an image, a dehazing algorithm should localize and recover affected regions while ensuring consistency between recovered and its neighboring regions. However owing to fixed receptive field of convolutional kernels and non uniform haze distribution, assuring consistency between regions is difficult. In this paper, we utilize an encoder-decoder based network architecture to perform the task of dehazing and integrate an spatially aware channel attention mechanism to enhance features of interest beyond the receptive field of traditional conventional kernels. To ensure performance consistency across diverse range of haze densities, we utilize greedy localized data augmentation mechanism. Synthetic datasets are typically used to ensure a large amount of paired training samples, however the methodology to generate such samples introduces a gap between them and real images while accounting for only uniform haze distribution and overlooking more realistic scenario of non-uniform haze distribution resulting in inferior dehazing performance when evaluated on real datasets. Despite this, the abundance of paired samples within synthetic datasets cannot be ignored. Thus to ensure performance consistency across diverse datasets, we train the proposed network within an adversarial prior-guided framework that relies on a generated image along with its low and high frequency components to determine if properties of dehazed images matches those of ground truth. We preform extensive experiments to validate the dehazing and domain invariance performance of proposed framework across diverse domains and report state-of-the-art (SoTA) results.
Retaining Image Feature Matching Performance Under Low Light Conditions
Sep 02, 2020
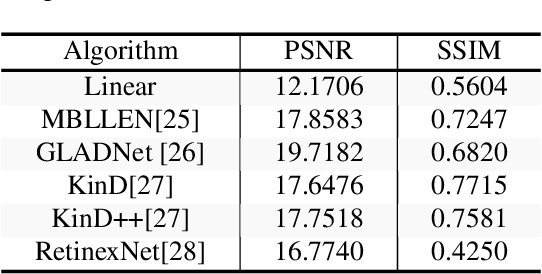

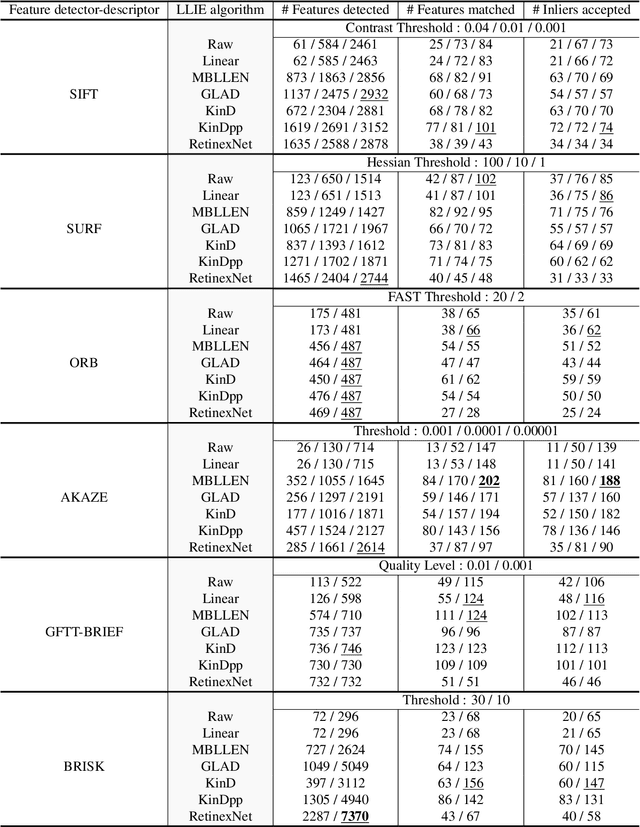
Poor image quality in low light images may result in a reduced number of feature matching between images. In this paper, we investigate the performance of feature extraction algorithms in low light environments. To find an optimal setting to retain feature matching performance in low light images, we look into the effect of changing feature acceptance threshold for feature detector and adding pre-processing in the form of Low Light Image Enhancement (LLIE) prior to feature detection. We observe that even in low light images, feature matching using traditional hand-crafted feature detectors still performs reasonably well by lowering the threshold parameter. We also show that applying Low Light Image Enhancement (LLIE) algorithms can improve feature matching even more when paired with the right feature extraction algorithm.