 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVigilEye -- Artificial Intelligence-based Real-time Driver Drowsiness Detection
Jun 21, 2024This study presents a novel driver drowsiness detection system that combines deep learning techniques with the OpenCV framework. The system utilises facial landmarks extracted from the driver's face as input to Convolutional Neural Networks trained to recognise drowsiness patterns. The integration of OpenCV enables real-time video processing, making the system suitable for practical implementation. Extensive experiments on a diverse dataset demonstrate high accuracy, sensitivity, and specificity in detecting drowsiness. The proposed system has the potential to enhance road safety by providing timely alerts to prevent accidents caused by driver fatigue. This research contributes to advancing real-time driver monitoring systems and has implications for automotive safety and intelligent transportation systems. The successful application of deep learning techniques in this context opens up new avenues for future research in driver monitoring and vehicle safety. The implementation code for the paper is available at https://github.com/LUFFY7001/Driver-s-Drowsiness-Detection.
Efficient Human Pose Estimation: Leveraging Advanced Techniques with MediaPipe
Jun 21, 2024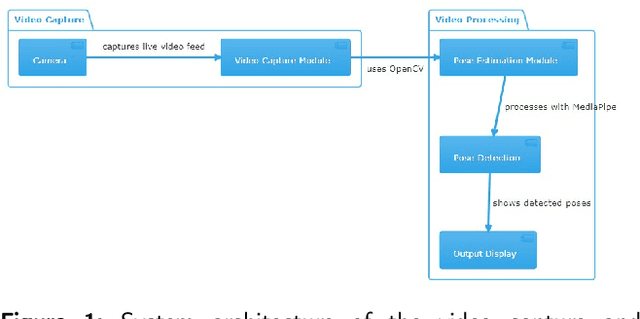
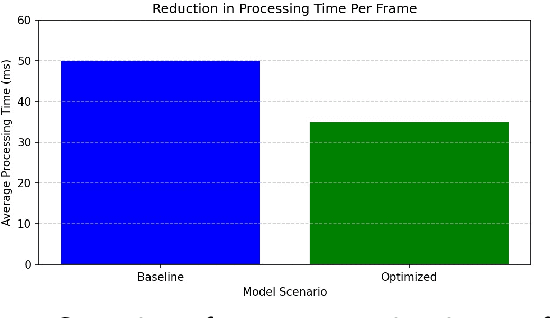

This study presents significant enhancements in human pose estimation using the MediaPipe framework. The research focuses on improving accuracy, computational efficiency, and real-time processing capabilities by comprehensively optimising the underlying algorithms. Novel modifications are introduced that substantially enhance pose estimation accuracy across challenging scenarios, such as dynamic movements and partial occlusions. The improved framework is benchmarked against traditional models, demonstrating considerable precision and computational speed gains. The advancements have wide-ranging applications in augmented reality, sports analytics, and healthcare, enabling more immersive experiences, refined performance analysis, and advanced patient monitoring. The study also explores the integration of these enhancements within mobile and embedded systems, addressing the need for computational efficiency and broader accessibility. The implications of this research set a new benchmark for real-time human pose estimation technologies and pave the way for future innovations in the field. The implementation code for the paper is available at https://github.com/avhixd/Human_pose_estimation.
Robust compressive tracking via online weighted multiple instance learning
Jun 14, 2024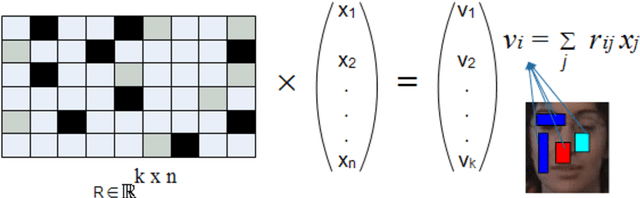
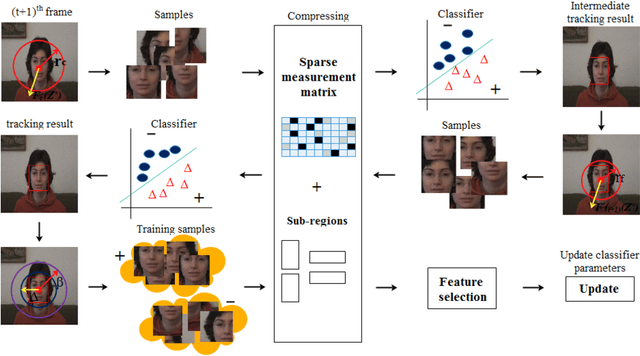
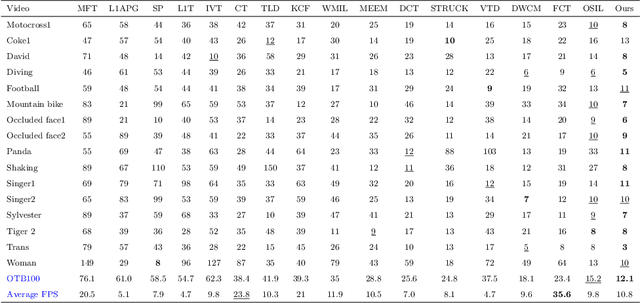
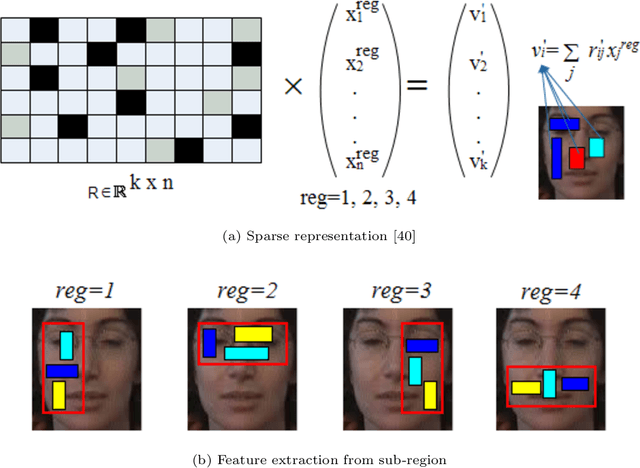
Developing a robust object tracker is a challenging task due to factors such as occlusion, motion blur, fast motion, illumination variations, rotation, background clutter, low resolution and deformation across the frames. In the literature, lots of good approaches based on sparse representation have already been presented to tackle the above problems. However, most of the algorithms do not focus on the learning of sparse representation. They only consider the modeling of target appearance and therefore drift away from the target with the imprecise training samples. By considering all the above factors in mind, we have proposed a visual object tracking algorithm by integrating a coarse-to-fine search strategy based on sparse representation and the weighted multiple instance learning (WMIL) algorithm. Compared with the other trackers, our approach has more information of the original signal with less complexity due to the coarse-to-fine search method, and also has weights for important samples. Thus, it can easily discriminate the background features from the foreground. Furthermore, we have also selected the samples from the un-occluded sub-regions to efficiently develop the strong classifier. As a consequence, a stable and robust object tracker is achieved to tackle all the aforementioned problems. Experimental results with quantitative as well as qualitative analysis on challenging benchmark datasets show the accuracy and efficiency of our method.
Generative Artificial Intelligence: A Systematic Review and Applications
May 17, 2024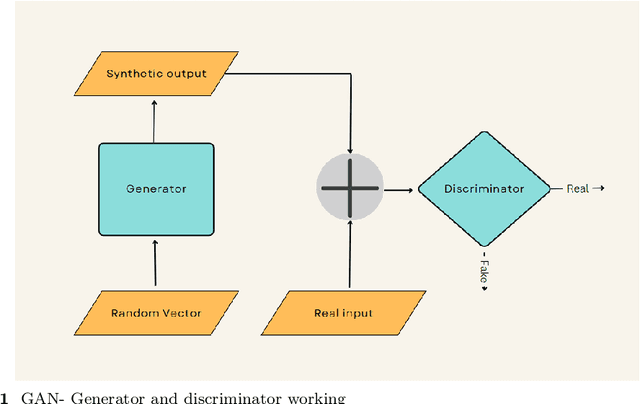

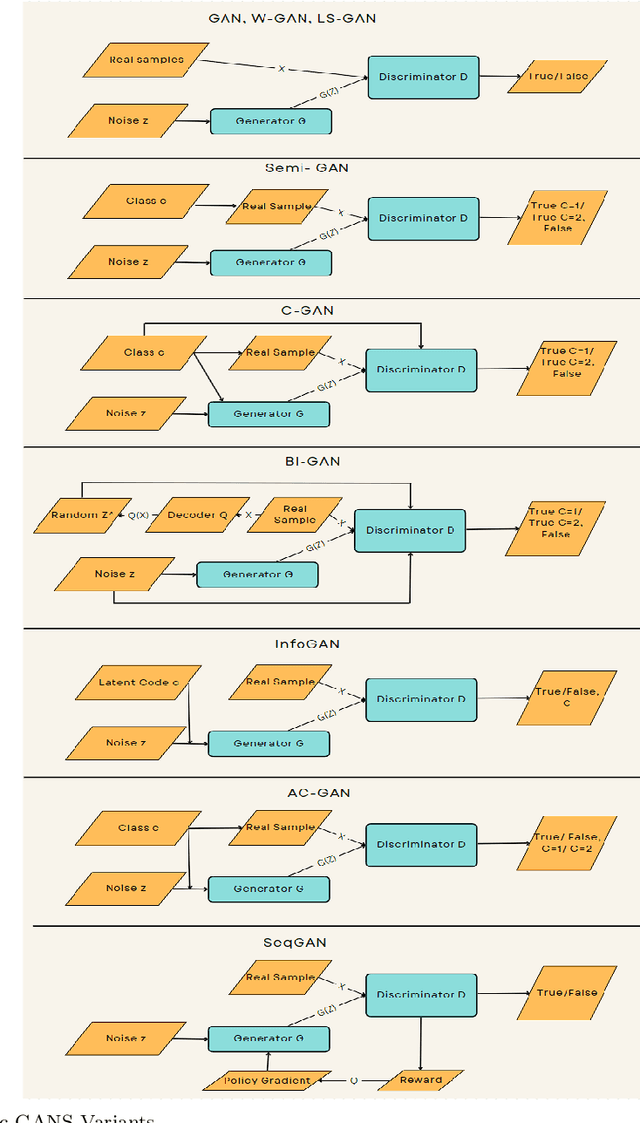

In recent years, the study of artificial intelligence (AI) has undergone a paradigm shift. This has been propelled by the groundbreaking capabilities of generative models both in supervised and unsupervised learning scenarios. Generative AI has shown state-of-the-art performance in solving perplexing real-world conundrums in fields such as image translation, medical diagnostics, textual imagery fusion, natural language processing, and beyond. This paper documents the systematic review and analysis of recent advancements and techniques in Generative AI with a detailed discussion of their applications including application-specific models. Indeed, the major impact that generative AI has made to date, has been in language generation with the development of large language models, in the field of image translation and several other interdisciplinary applications of generative AI. Moreover, the primary contribution of this paper lies in its coherent synthesis of the latest advancements in these areas, seamlessly weaving together contemporary breakthroughs in the field. Particularly, how it shares an exploration of the future trajectory for generative AI. In conclusion, the paper ends with a discussion of Responsible AI principles, and the necessary ethical considerations for the sustainability and growth of these generative models.
RepVGG-GELAN: Enhanced GELAN with VGG-STYLE ConvNets for Brain Tumour Detection
May 06, 2024



Object detection algorithms particularly those based on YOLO have demonstrated remarkable efficiency in balancing speed and accuracy. However, their application in brain tumour detection remains underexplored. This study proposes RepVGG-GELAN, a novel YOLO architecture enhanced with RepVGG, a reparameterized convolutional approach for object detection tasks particularly focusing on brain tumour detection within medical images. RepVGG-GELAN leverages the RepVGG architecture to improve both speed and accuracy in detecting brain tumours. Integrating RepVGG into the YOLO framework aims to achieve a balance between computational efficiency and detection performance. This study includes a spatial pyramid pooling-based Generalized Efficient Layer Aggregation Network (GELAN) architecture which further enhances the capability of RepVGG. Experimental evaluation conducted on a brain tumour dataset demonstrates the effectiveness of RepVGG-GELAN surpassing existing RCS-YOLO in terms of precision and speed. Specifically, RepVGG-GELAN achieves an increased precision of 4.91% and an increased AP50 of 2.54% over the latest existing approach while operating at 240.7 GFLOPs. The proposed RepVGG-GELAN with GELAN architecture presents promising results establishing itself as a state-of-the-art solution for accurate and efficient brain tumour detection in medical images. The implementation code is publicly available at https://github.com/ThensiB/RepVGG-GELAN.
BetterNet: An Efficient CNN Architecture with Residual Learning and Attention for Precision Polyp Segmentation
May 05, 2024

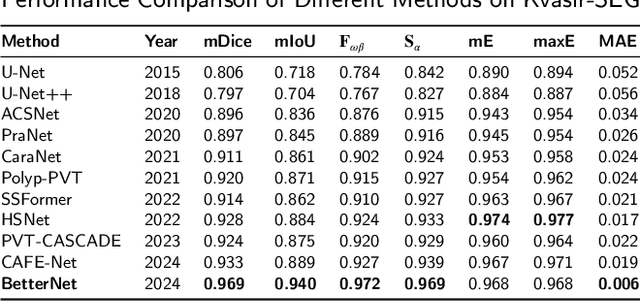
Colorectal cancer contributes significantly to cancer-related mortality. Timely identification and elimination of polyps through colonoscopy screening is crucial in order to decrease mortality rates. Accurately detecting polyps in colonoscopy images is difficult because of the differences in characteristics such as size, shape, texture, and similarity to surrounding tissues. Current deep-learning methods often face difficulties in capturing long-range connections necessary for segmentation. This research presents BetterNet, a convolutional neural network (CNN) architecture that combines residual learning and attention methods to enhance the accuracy of polyp segmentation. The primary characteristics encompass (1) a residual decoder architecture that facilitates efficient gradient propagation and integration of multiscale features. (2) channel and spatial attention blocks within the decoder block to concentrate the learning process on the relevant areas of polyp regions. (3) Achieving state-of-the-art performance on polyp segmentation benchmarks while still ensuring computational efficiency. (4) Thorough ablation tests have been conducted to confirm the influence of architectural components. (5) The model code has been made available as open-source for further contribution. Extensive evaluations conducted on datasets such as Kvasir-SEG, CVC ClinicDB, Endoscene, EndoTect, and Kvasir-Sessile demonstrate that BetterNets outperforms current SOTA models in terms of segmentation accuracy by significant margins. The lightweight design enables real-time inference for various applications. BetterNet shows promise in integrating computer-assisted diagnosis techniques to enhance the detection of polyps and the early recognition of cancer. Link to the code: https://github.com/itsOwen/BetterNet
Age-Stratified Differences in Morphological Connectivity Patterns in ASD: An sMRI and Machine Learning Approach
Aug 14, 2023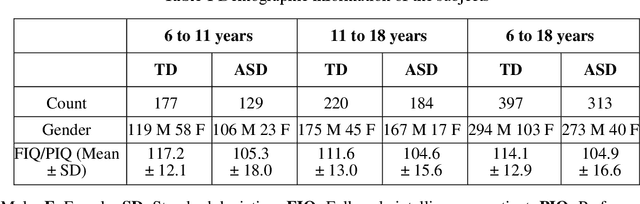
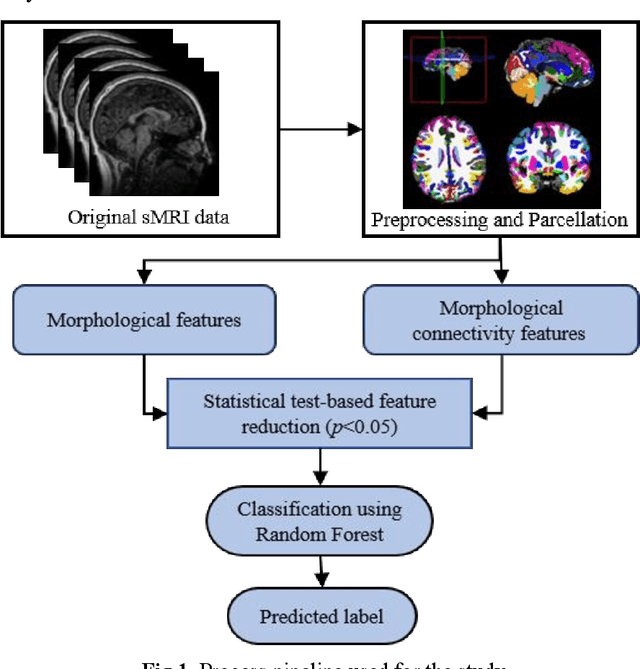
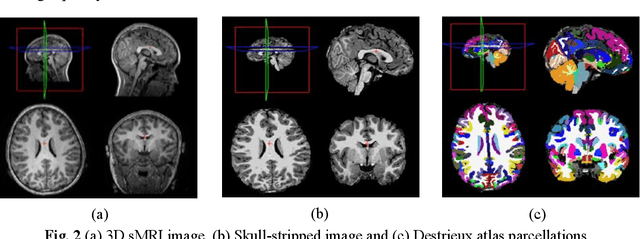
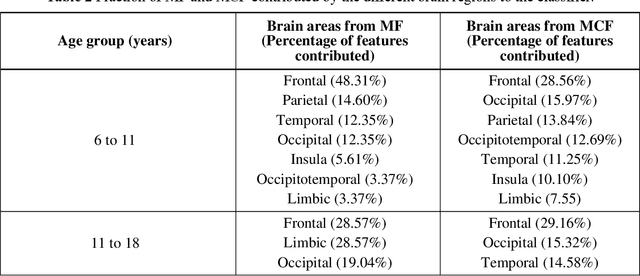
Purpose: Age biases have been identified as an essential factor in the diagnosis of ASD. The objective of this study was to compare the effect of different age groups in classifying ASD using morphological features (MF) and morphological connectivity features (MCF). Methods: The structural magnetic resonance imaging (sMRI) data for the study was obtained from the two publicly available databases, ABIDE-I and ABIDE-II. We considered three age groups, 6 to 11, 11 to 18, and 6 to 18, for our analysis. The sMRI data was pre-processed using a standard pipeline and was then parcellated into 148 different regions according to the Destrieux atlas. The area, thickness, volume, and mean curvature information was then extracted for each region which was used to create a total of 592 MF and 10,878 MCF for each subject. Significant features were identified using a statistical t-test (p<0.05) which was then used to train a random forest (RF) classifier. Results: The results of our study suggested that the performance of the 6 to 11 age group was the highest, followed by the 6 to 18 and 11 to 18 ages in both MF and MCF. Overall, the MCF with RF in the 6 to 11 age group performed better in the classification than the other groups and produced an accuracy, F1 score, recall, and precision of 75.8%, 83.1%, 86%, and 80.4%, respectively. Conclusion: Our study thus demonstrates that morphological connectivity and age-related diagnostic model could be an effective approach to discriminating ASD.
Lightweight HDR Camera ISP for Robust Perception in Dynamic Illumination Conditions via Fourier Adversarial Networks
Apr 04, 2022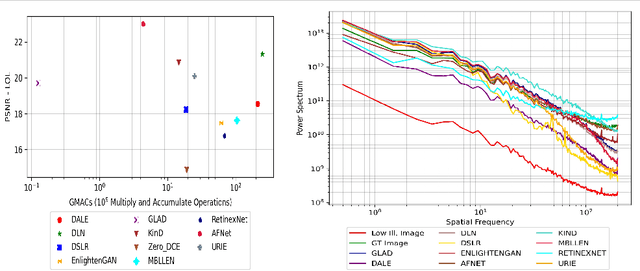
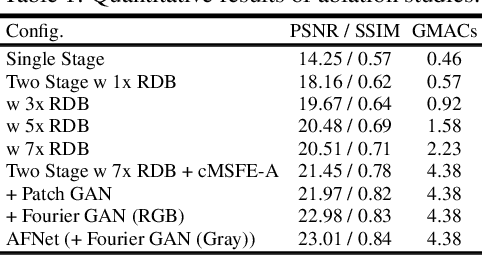
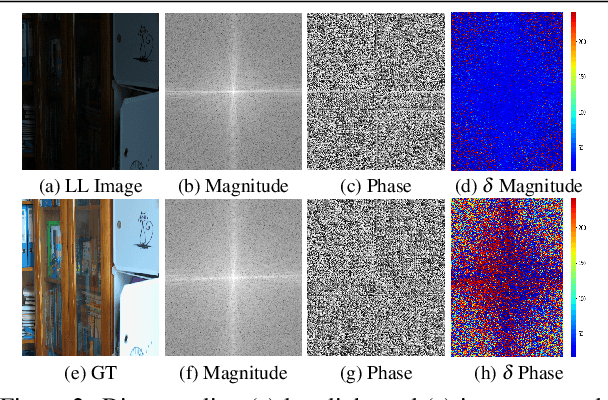
The limited dynamic range of commercial compact camera sensors results in an inaccurate representation of scenes with varying illumination conditions, adversely affecting image quality and subsequently limiting the performance of underlying image processing algorithms. Current state-of-the-art (SoTA) convolutional neural networks (CNN) are developed as post-processing techniques to independently recover under-/over-exposed images. However, when applied to images containing real-world degradations such as glare, high-beam, color bleeding with varying noise intensity, these algorithms amplify the degradations, further degrading image quality. We propose a lightweight two-stage image enhancement algorithm sequentially balancing illumination and noise removal using frequency priors for structural guidance to overcome these limitations. Furthermore, to ensure realistic image quality, we leverage the relationship between frequency and spatial domain properties of an image and propose a Fourier spectrum-based adversarial framework (AFNet) for consistent image enhancement under varying illumination conditions. While current formulations of image enhancement are envisioned as post-processing techniques, we examine if such an algorithm could be extended to integrate the functionality of the Image Signal Processing (ISP) pipeline within the camera sensor benefiting from RAW sensor data and lightweight CNN architecture. Based on quantitative and qualitative evaluations, we also examine the practicality and effects of image enhancement techniques on the performance of common perception tasks such as object detection and semantic segmentation in varying illumination conditions.
Evaluating COPY-BLEND Augmentation for Low Level Vision Tasks
Mar 10, 2021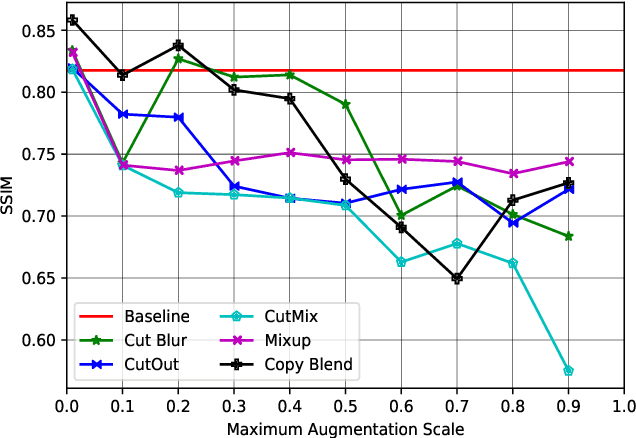

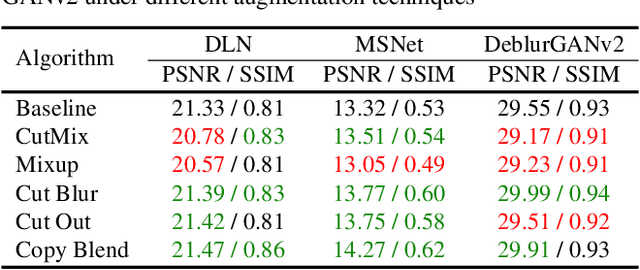
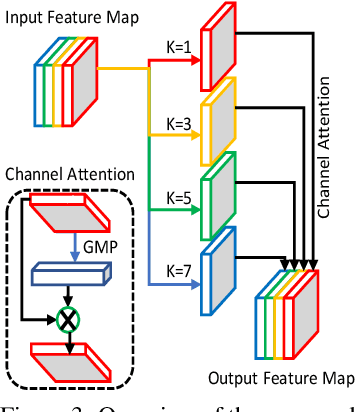
Region modification-based data augmentation techniques have shown to improve performance for high level vision tasks (object detection, semantic segmentation, image classification, etc.) by encouraging underlying algorithms to focus on multiple discriminative features. However, as these techniques destroy spatial relationship with neighboring regions, performance can be deteriorated when using them to train algorithms designed for low level vision tasks (low light image enhancement, image dehazing, deblurring, etc.) where textural consistency between recovered and its neighboring regions is important to ensure effective performance. In this paper, we examine the efficacy of a simple copy-blend data augmentation technique that copies patches from noisy images and blends onto a clean image and vice versa to ensure that an underlying algorithm localizes and recovers affected regions resulting in increased perceptual quality of a recovered image. To assess performance improvement, we perform extensive experiments alongside different region modification-based augmentation techniques and report observations such as improved performance, reduced requirement for training dataset, and early convergence across tasks such as low light image enhancement, image dehazing and image deblurring without any modification to baseline algorithm.