 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Optical Single-axis Joint Torque Sensor Using Redundant Photo-Reflectors and Quadratic-Programming Calibration
Mar 17, 2026This study proposes a non-contact photo-reflector-based joint torque sensor for precise joint-level torque control and safe physical interaction. Current-sensor-based torque estimation in many collaborative robots suffers from poor low-torque accuracy due to gearbox stiction/friction and current-torque nonlinearity, especially near static conditions. The proposed sensor optically measures micro-deformation of an elastic structure and employs a redundant array of photo-reflectors arranged in four directions to improve sensitivity and signal-to-noise ratio. We further present a quadratic-programming-based calibration method that exploits redundancy to suppress noise and enhance resolution compared to least-squares calibration. The sensor is implemented in a compact form factor (96 mm diameter, 12 mm thickness). Experiments demonstrate a maximum error of 0.083%FS and an RMS error of 0.0266 Nm for z-axis torque measurement. Calibration tests show that the proposed calibration achieves a 3 sigma resolution of 0.0224 Nm at 1 kHz without filtering, corresponding to a 2.14 times improvement over the least-squares baseline. Temperature chamber characterization and rational fitting based compensation mitigate zero drift induced by MCU self heating and motor heat. Motor-level validation via torque control and admittance control confirms improved low torque tracking and disturbance robustness relative to current-sensor-based control.
Attention-Based Neural-Augmented Kalman Filter for Legged Robot State Estimation
Jan 26, 2026In this letter, we propose an Attention-Based Neural-Augmented Kalman Filter (AttenNKF) for state estimation in legged robots. Foot slip is a major source of estimation error: when slip occurs, kinematic measurements violate the no-slip assumption and inject bias during the update step. Our objective is to estimate this slip-induced error and compensate for it. To this end, we augment an Invariant Extended Kalman Filter (InEKF) with a neural compensator that uses an attention mechanism to infer error conditioned on foot-slip severity and then applies this estimate as a post-update compensation to the InEKF state (i.e., after the filter update). The compensator is trained in a latent space, which aims to reduce sensitivity to raw input scales and encourages structured slip-conditioned compensations, while preserving the InEKF recursion. Experiments demonstrate improved performance compared to existing legged-robot state estimators, particularly under slip-prone conditions.
Dual-MPC Footstep Planning for Robust Quadruped Locomotion
Nov 11, 2025
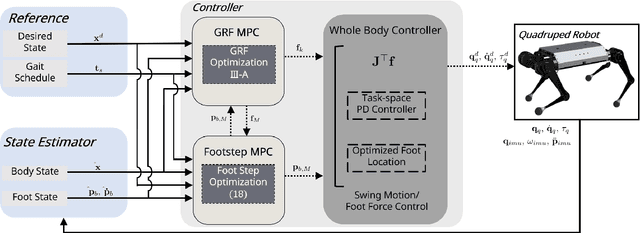


In this paper, we propose a footstep planning strategy based on model predictive control (MPC) that enables robust regulation of body orientation against undesired body rotations by optimizing footstep placement. Model-based locomotion approaches typically adopt heuristic methods or planning based on the linear inverted pendulum model. These methods account for linear velocity in footstep planning, while excluding angular velocity, which leads to angular momentum being handled exclusively via ground reaction force (GRF). Footstep planning based on MPC that takes angular velocity into account recasts the angular momentum control problem as a dual-input approach that coordinates GRFs and footstep placement, instead of optimizing GRFs alone, thereby improving tracking performance. A mutual-feedback loop couples the footstep planner and the GRF MPC, with each using the other's solution to iteratively update footsteps and GRFs. The use of optimal solutions reduces body oscillation and enables extended stance and swing phases. The method is validated on a quadruped robot, demonstrating robust locomotion with reduced oscillations, longer stance and swing phases across various terrains.
Ground-Aware Octree-A* Hybrid Path Planning for Memory-Efficient 3D Navigation of Ground Vehicles
Sep 05, 2025
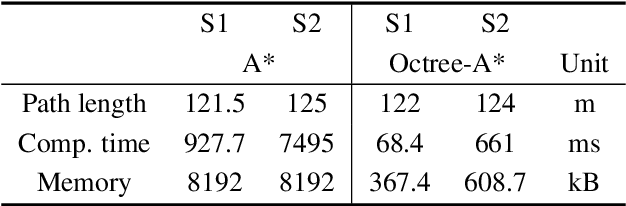


In this paper, we propose a 3D path planning method that integrates the A* algorithm with the octree structure. Unmanned Ground Vehicles (UGVs) and legged robots have been extensively studied, enabling locomotion across a variety of terrains. Advances in mobility have enabled obstacles to be regarded not only as hindrances to be avoided, but also as navigational aids when beneficial. A modified 3D A* algorithm generates an optimal path by leveraging obstacles during the planning process. By incorporating a height-based penalty into the cost function, the algorithm enables the use of traversable obstacles to aid locomotion while avoiding those that are impassable, resulting in more efficient and realistic path generation. The octree-based 3D grid map achieves compression by merging high-resolution nodes into larger blocks, especially in obstacle-free or sparsely populated areas. This reduces the number of nodes explored by the A* algorithm, thereby improving computational efficiency and memory usage, and supporting real-time path planning in practical environments. Benchmark results demonstrate that the use of octree structure ensures an optimal path while significantly reducing memory usage and computation time.
A Novel 6-axis Force/Torque Sensor Using Inductance Sensors
May 14, 2025This paper presents a novel six-axis force/torque (F/T) sensor based on inductive sensing technology. Unlike conventional strain gauge-based sensors that require direct contact and external amplification, the proposed sensor utilizes non-contact inductive measurements to estimate force via displacement of a conductive target. A compact, fully integrated architecture is achieved by incorporating a CAN-FD based signal processing module directly onto the PCB, enabling high-speed data acquisition at up to 4~kHz without external DAQ systems. The sensing mechanism is modeled and calibrated through a rational function fitting approach, which demonstrated superior performance in terms of root mean square error (RMSE), coefficient of determination ($R^2$), and linearity error compared to other nonlinear models. Static and repeatability experiments validate the sensor's accuracy, achieving a resolution of 0.03~N and quantization levels exceeding 55,000 steps, surpassing that of commercial sensors. The sensor also exhibits low crosstalk, high sensitivity, and robust noise characteristics. Its performance and structure make it suitable for precision robotic applications, especially in scenarios where compactness, non-contact operation, and integrated processing are essential.
Temperature Compensation Method of Six-Axis Force/Torque Sensor Using Gated Recurrent Unit
Feb 24, 2025



This study aims to enhance the accuracy of a six-axis force/torque sensor compared to existing approaches that utilize Multi-Layer Perceptron (MLP) and the Least Square Method. The sensor used in this study is based on a photo-coupler and operates with infrared light, making it susceptible to dark current effects, which cause drift due to temperature variations. Additionally, the sensor is compact and lightweight (45g), resulting in a low thermal capacity. Consequently, even small amounts of heat can induce rapid temperature changes, affecting the sensor's performance in real time. To address these challenges, this study compares the conventional MLP approach with the proposed Gated Recurrent Unit (GRU)-based method. Experimental results demonstrate that the GRU approach, leveraging sequential data, achieves superior performance.
Parameter Optimization of Optical Six-Axis Force/Torque Sensor for Legged Robots
Feb 11, 2025This paper introduces a novel six-axis force/torque sensor tailored for compact and lightweight legged robots. Unlike traditional strain gauge-based sensors, the proposed non-contact design employs photocouplers, enhancing resistance to physical impacts and reducing damage risk. This approach simplifies manufacturing, lowers costs, and meets the demands of legged robots by combining small size, light weight, and a wide force measurement range. A methodology for optimizing sensor parameters is also presented, focusing on maximizing sensitivity and minimizing error. Precise modeling and analysis of objective functions enabled the derivation of optimal design parameters. The sensor's performance was validated through extensive testing and integration into quadruped robots, demonstrating alignment with theoretical modeling. The sensor's precise measurement capabilities make it suitable for diverse robotic environments, particularly in analyzing interactions between robot feet and the ground. This innovation addresses existing sensor limitations while contributing to advancements in robotics and sensor technology, paving the way for future applications in robotic systems.
A Compact Optical Six-Axis Force/Torque Sensor for Legged Robots Using a Polymorphic Calibration Method
Sep 20, 2023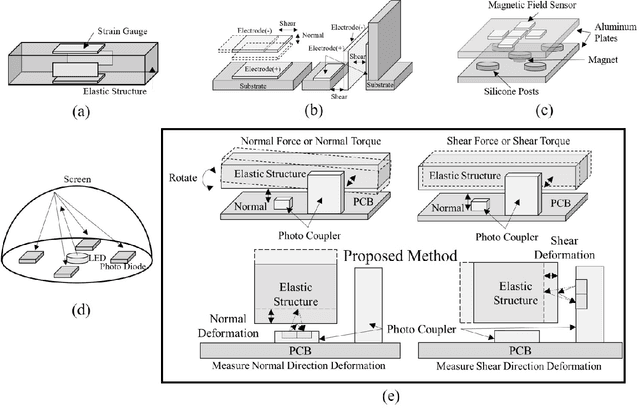
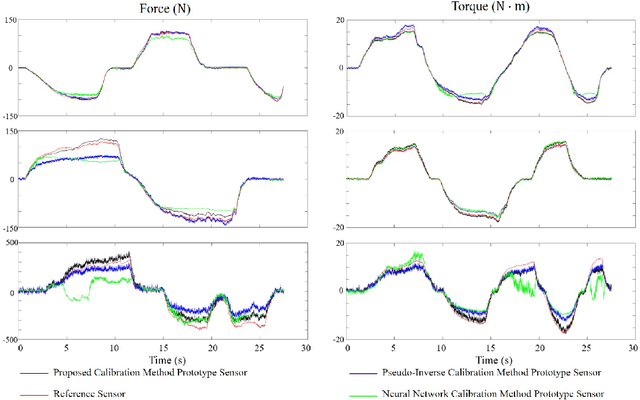
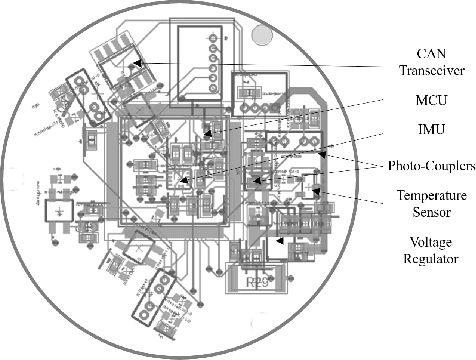
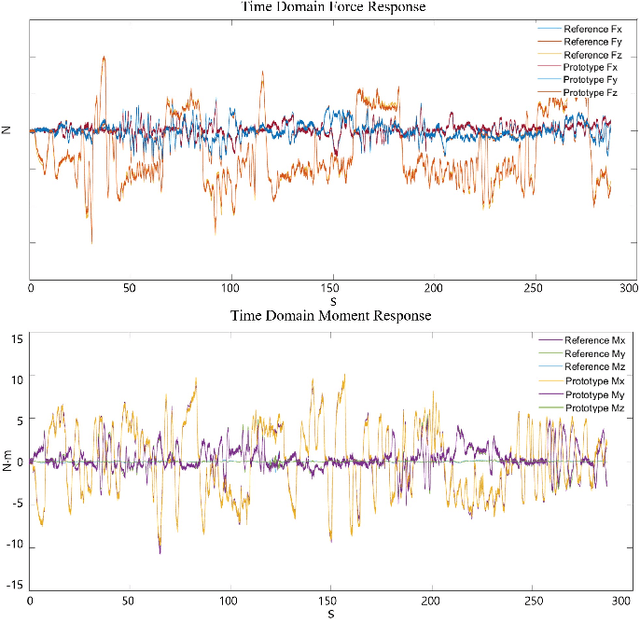
This paper presents a novel design for a compact, lightweight 6-axis force/torque sensor intended for use in legged robots. The design promotes easy manufacturing and cost reduction, while introducing innovative calibration methods that simplify the calibration process and minimize effort. The sensor's advantages are achieved by streamlining the structure for durability, implementing noncontact sensors, and providing a wider sensing range compared to commercial sensors. To maintain a simple structure, the paper proposes a force sensing scheme using photocouplers where the sensing elements are aligned in-plane. This strategy enables all sensing elements to be fabricated on a single printed circuit board, eliminating manual labor tasks such as bonding and coating the sensing elements. The prototype sensor contains only four parts, costs less than $250, and exhibits high response frequency and performance. Traditional calibration methods present challenges, such as the need for specialized equipment and extensive labor. To facilitate easy calibration without the need for specialized equipment, a new method using optimal control is proposed. To verify the feasibility of these ideas, a prototype six-axis F/T sensor was manufactured. Its performance was evaluated and compared to a reference F/T sensor and previous calibration methods.
DualRefine: Self-Supervised Depth and Pose Estimation Through Iterative Epipolar Sampling and Refinement Toward Equilibrium
Apr 07, 2023Self-supervised multi-frame depth estimation achieves high accuracy by computing matching costs of pixel correspondences between adjacent frames, injecting geometric information into the network. These pixel-correspondence candidates are computed based on the relative pose estimates between the frames. Accurate pose predictions are essential for precise matching cost computation as they influence the epipolar geometry. Furthermore, improved depth estimates can, in turn, be used to align pose estimates. Inspired by traditional structure-from-motion (SfM) principles, we propose the DualRefine model, which tightly couples depth and pose estimation through a feedback loop. Our novel update pipeline uses a deep equilibrium model framework to iteratively refine depth estimates and a hidden state of feature maps by computing local matching costs based on epipolar geometry. Importantly, we used the refined depth estimates and feature maps to compute pose updates at each step. This update in the pose estimates slowly alters the epipolar geometry during the refinement process. Experimental results on the KITTI dataset demonstrate competitive depth prediction and odometry prediction performance surpassing published self-supervised baselines.
Lightweight HDR Camera ISP for Robust Perception in Dynamic Illumination Conditions via Fourier Adversarial Networks
Apr 04, 2022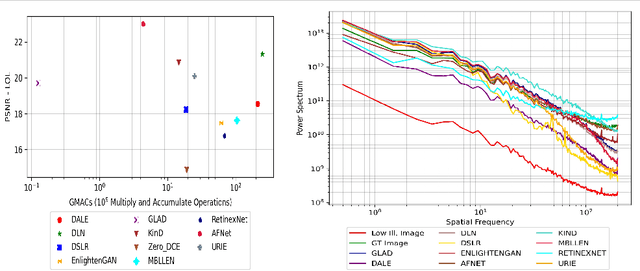
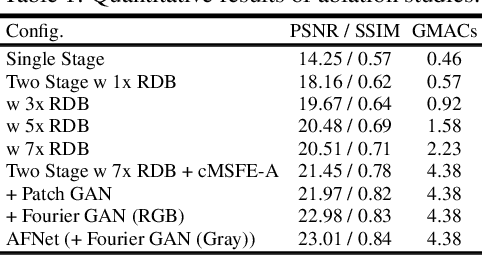
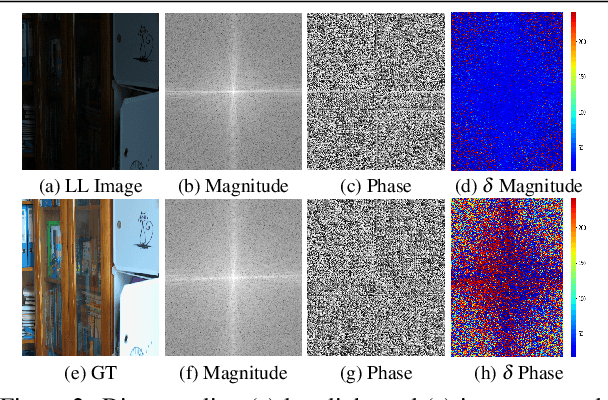
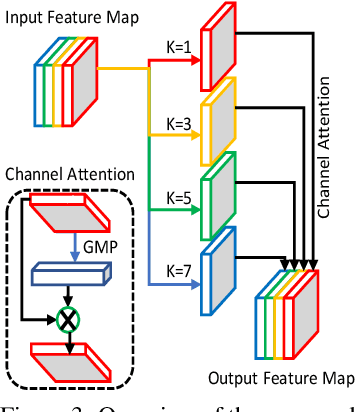
The limited dynamic range of commercial compact camera sensors results in an inaccurate representation of scenes with varying illumination conditions, adversely affecting image quality and subsequently limiting the performance of underlying image processing algorithms. Current state-of-the-art (SoTA) convolutional neural networks (CNN) are developed as post-processing techniques to independently recover under-/over-exposed images. However, when applied to images containing real-world degradations such as glare, high-beam, color bleeding with varying noise intensity, these algorithms amplify the degradations, further degrading image quality. We propose a lightweight two-stage image enhancement algorithm sequentially balancing illumination and noise removal using frequency priors for structural guidance to overcome these limitations. Furthermore, to ensure realistic image quality, we leverage the relationship between frequency and spatial domain properties of an image and propose a Fourier spectrum-based adversarial framework (AFNet) for consistent image enhancement under varying illumination conditions. While current formulations of image enhancement are envisioned as post-processing techniques, we examine if such an algorithm could be extended to integrate the functionality of the Image Signal Processing (ISP) pipeline within the camera sensor benefiting from RAW sensor data and lightweight CNN architecture. Based on quantitative and qualitative evaluations, we also examine the practicality and effects of image enhancement techniques on the performance of common perception tasks such as object detection and semantic segmentation in varying illumination conditions.