 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Paper and Code
Feb 26, 2022

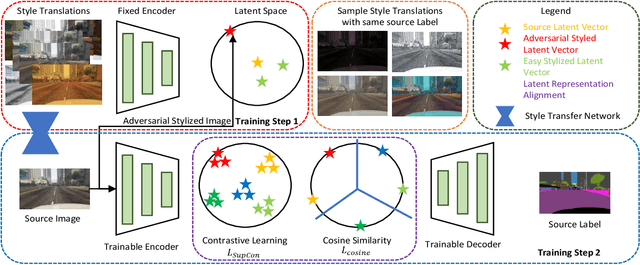

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.