 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Brain: A Neuroscience-inspired Framework for Embodied Agents
May 14, 2025The rapid evolution of artificial intelligence (AI) has shifted from static, data-driven models to dynamic systems capable of perceiving and interacting with real-world environments. Despite advancements in pattern recognition and symbolic reasoning, current AI systems, such as large language models, remain disembodied, unable to physically engage with the world. This limitation has driven the rise of embodied AI, where autonomous agents, such as humanoid robots, must navigate and manipulate unstructured environments with human-like adaptability. At the core of this challenge lies the concept of Neural Brain, a central intelligence system designed to drive embodied agents with human-like adaptability. A Neural Brain must seamlessly integrate multimodal sensing and perception with cognitive capabilities. Achieving this also requires an adaptive memory system and energy-efficient hardware-software co-design, enabling real-time action in dynamic environments. This paper introduces a unified framework for the Neural Brain of embodied agents, addressing two fundamental challenges: (1) defining the core components of Neural Brain and (2) bridging the gap between static AI models and the dynamic adaptability required for real-world deployment. To this end, we propose a biologically inspired architecture that integrates multimodal active sensing, perception-cognition-action function, neuroplasticity-based memory storage and updating, and neuromorphic hardware/software optimization. Furthermore, we also review the latest research on embodied agents across these four aspects and analyze the gap between current AI systems and human intelligence. By synthesizing insights from neuroscience, we outline a roadmap towards the development of generalizable, autonomous agents capable of human-level intelligence in real-world scenarios.
Let Me Finish My Sentence: Video Temporal Grounding with Holistic Text Understanding
Oct 17, 2024


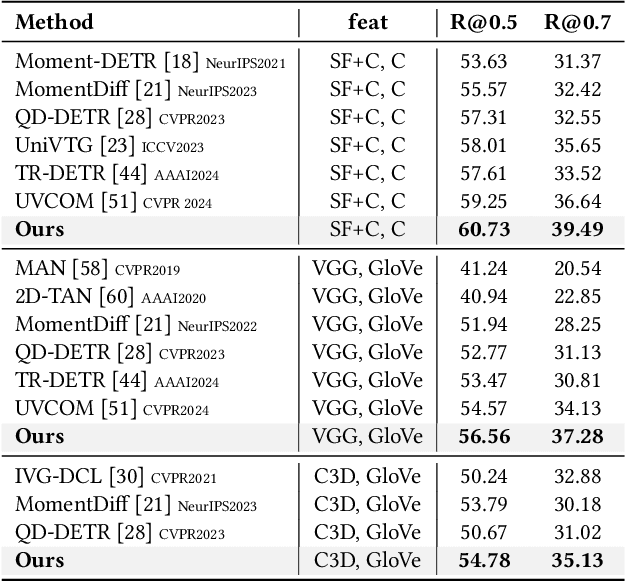
Video Temporal Grounding (VTG) aims to identify visual frames in a video clip that match text queries. Recent studies in VTG employ cross-attention to correlate visual frames and text queries as individual token sequences. However, these approaches overlook a crucial aspect of the problem: a holistic understanding of the query sentence. A model may capture correlations between individual word tokens and arbitrary visual frames while possibly missing out on the global meaning. To address this, we introduce two primary contributions: (1) a visual frame-level gate mechanism that incorporates holistic textual information, (2) cross-modal alignment loss to learn the fine-grained correlation between query and relevant frames. As a result, we regularize the effect of individual word tokens and suppress irrelevant visual frames. We demonstrate that our method outperforms state-of-the-art approaches in VTG benchmarks, indicating that holistic text understanding guides the model to focus on the semantically important parts within the video.
Preserving Multi-Modal Capabilities of Pre-trained VLMs for Improving Vision-Linguistic Compositionality
Oct 07, 2024



In this paper, we propose a new method to enhance compositional understanding in pre-trained vision and language models (VLMs) without sacrificing performance in zero-shot multi-modal tasks. Traditional fine-tuning approaches often improve compositional reasoning at the cost of degrading multi-modal capabilities, primarily due to the use of global hard negative (HN) loss, which contrasts global representations of images and texts. This global HN loss pushes HN texts that are highly similar to the original ones, damaging the model's multi-modal representations. To overcome this limitation, we propose Fine-grained Selective Calibrated CLIP (FSC-CLIP), which integrates local hard negative loss and selective calibrated regularization. These innovations provide fine-grained negative supervision while preserving the model's representational integrity. Our extensive evaluations across diverse benchmarks for both compositionality and multi-modal tasks show that FSC-CLIP not only achieves compositionality on par with state-of-the-art models but also retains strong multi-modal capabilities. Code is available at: https://github.com/ytaek-oh/fsc-clip.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Self-Sufficient Framework for Continuous Sign Language Recognition
Mar 21, 2023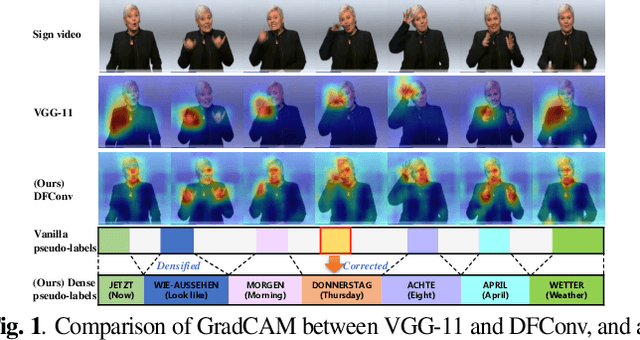
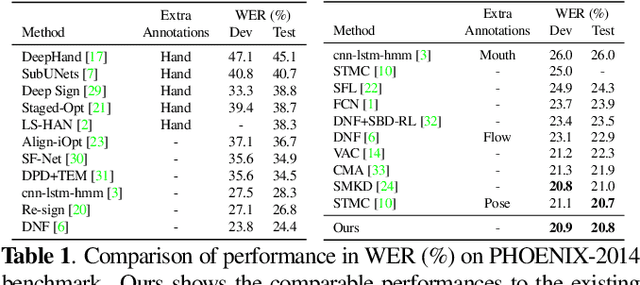
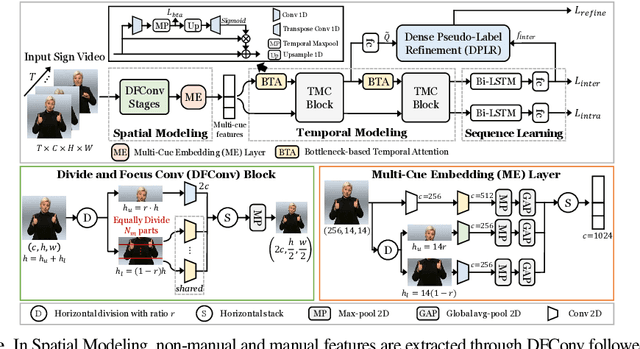

The goal of this work is to develop self-sufficient framework for Continuous Sign Language Recognition (CSLR) that addresses key issues of sign language recognition. These include the need for complex multi-scale features such as hands, face, and mouth for understanding, and absence of frame-level annotations. To this end, we propose (1) Divide and Focus Convolution (DFConv) which extracts both manual and non-manual features without the need for additional networks or annotations, and (2) Dense Pseudo-Label Refinement (DPLR) which propagates non-spiky frame-level pseudo-labels by combining the ground truth gloss sequence labels with the predicted sequence. We demonstrate that our model achieves state-of-the-art performance among RGB-based methods on large-scale CSLR benchmarks, PHOENIX-2014 and PHOENIX-2014-T, while showing comparable results with better efficiency when compared to other approaches that use multi-modality or extra annotations.
Signing Outside the Studio: Benchmarking Background Robustness for Continuous Sign Language Recognition
Nov 01, 2022



The goal of this work is background-robust continuous sign language recognition. Most existing Continuous Sign Language Recognition (CSLR) benchmarks have fixed backgrounds and are filmed in studios with a static monochromatic background. However, signing is not limited only to studios in the real world. In order to analyze the robustness of CSLR models under background shifts, we first evaluate existing state-of-the-art CSLR models on diverse backgrounds. To synthesize the sign videos with a variety of backgrounds, we propose a pipeline to automatically generate a benchmark dataset utilizing existing CSLR benchmarks. Our newly constructed benchmark dataset consists of diverse scenes to simulate a real-world environment. We observe even the most recent CSLR method cannot recognize glosses well on our new dataset with changed backgrounds. In this regard, we also propose a simple yet effective training scheme including (1) background randomization and (2) feature disentanglement for CSLR models. The experimental results on our dataset demonstrate that our method generalizes well to other unseen background data with minimal additional training images.
Generative Bias for Visual Question Answering
Aug 02, 2022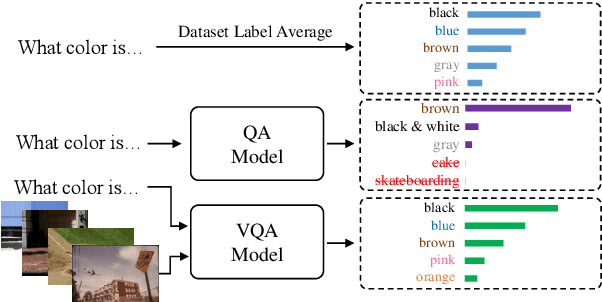
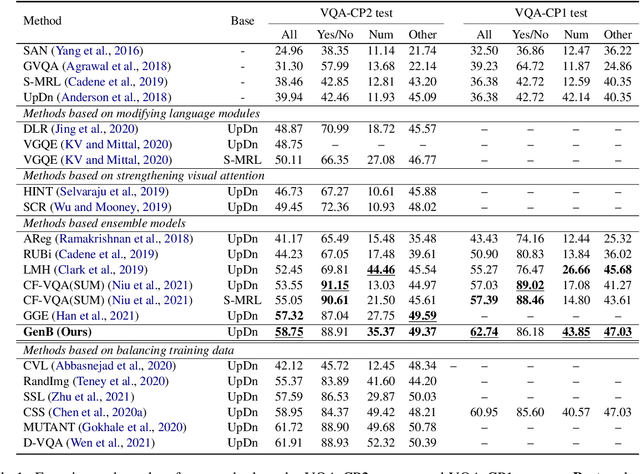

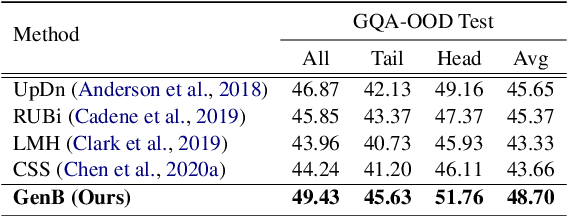
The task of Visual Question Answering (VQA) is known to be plagued by the issue of VQA models exploiting biases within the dataset to make its final prediction. Many previous ensemble based debiasing methods have been proposed where an additional model is purposefully trained to be biased in order to aid in training a robust target model. However, these methods compute the bias for a model from the label statistics of the training data or directly from single modal branches. In contrast, in this work, in order to better learn the bias a target VQA model suffers from, we propose a generative method to train the bias model \emph{directly from the target model}, called GenB. In particular, GenB employs a generative network to learn the bias through a combination of the adversarial objective and knowledge distillation. We then debias our target model with GenB as a bias model, and show through extensive experiments the effects of our method on various VQA bias datasets including VQA-CP2, VQA-CP1, GQA-OOD, and VQA-CE.
Investigating Top-$k$ White-Box and Transferable Black-box Attack
Mar 30, 2022
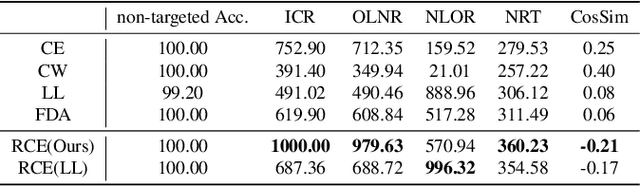


Existing works have identified the limitation of top-$1$ attack success rate (ASR) as a metric to evaluate the attack strength but exclusively investigated it in the white-box setting, while our work extends it to a more practical black-box setting: transferable attack. It is widely reported that stronger I-FGSM transfers worse than simple FGSM, leading to a popular belief that transferability is at odds with the white-box attack strength. Our work challenges this belief with empirical finding that stronger attack actually transfers better for the general top-$k$ ASR indicated by the interest class rank (ICR) after attack. For increasing the attack strength, with an intuitive interpretation of the logit gradient from the geometric perspective, we identify that the weakness of the commonly used losses lie in prioritizing the speed to fool the network instead of maximizing its strength. To this end, we propose a new normalized CE loss that guides the logit to be updated in the direction of implicitly maximizing its rank distance from the ground-truth class. Extensive results in various settings have verified that our proposed new loss is simple yet effective for top-$k$ attack. Code is available at: \url{https://bit.ly/3uCiomP}
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021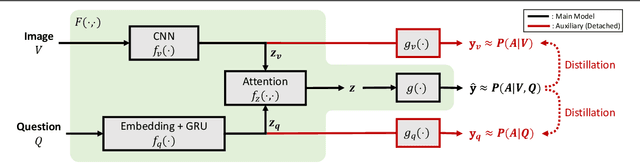
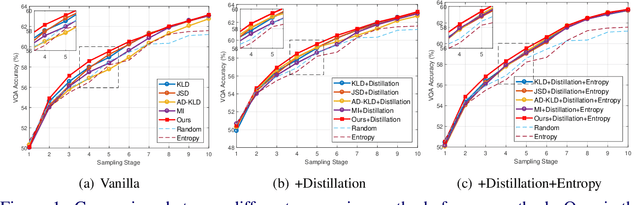
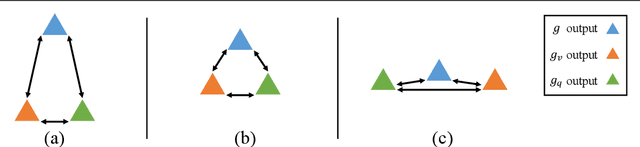
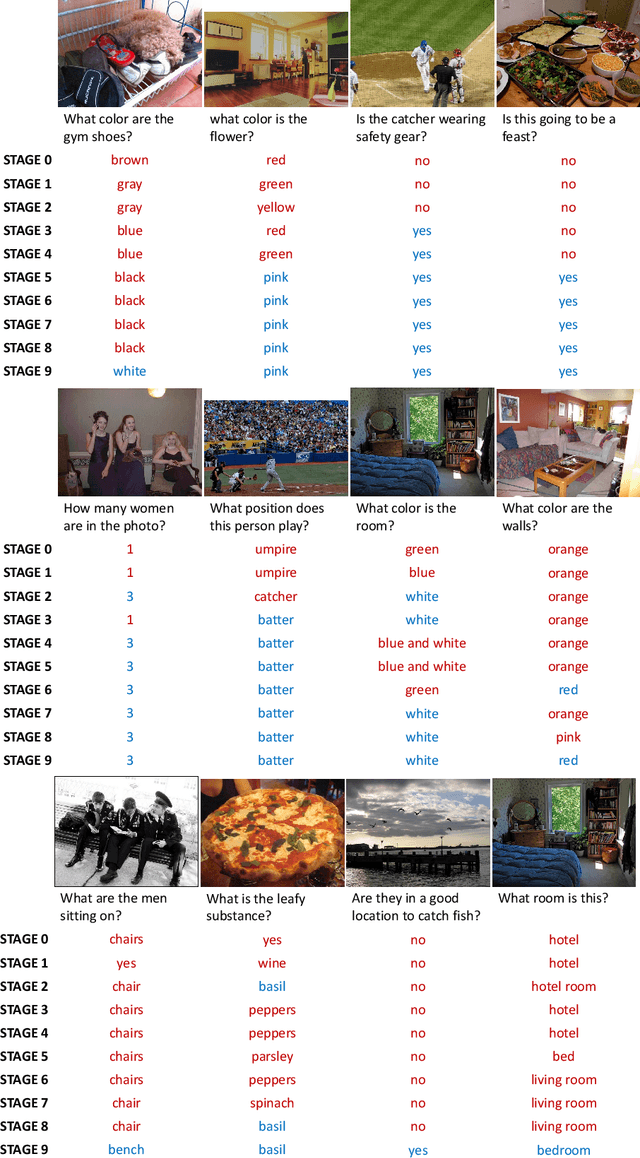
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021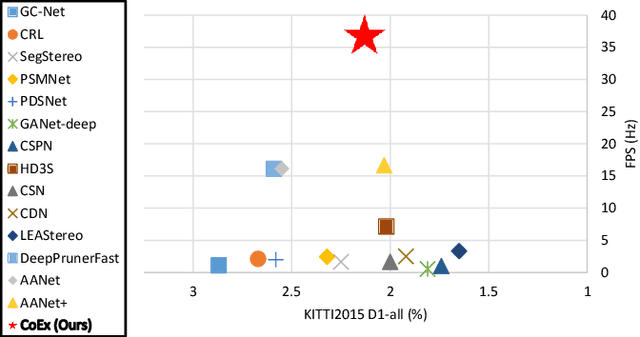
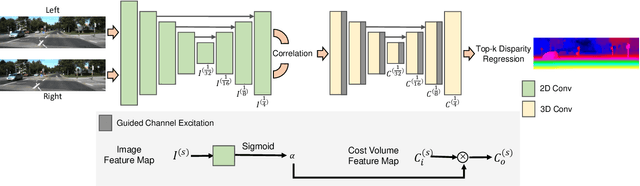

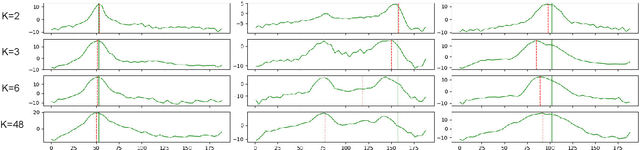
Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.