 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Speech and Sound: Distinguishing and Locating Audios in Visual Scenes
Mar 24, 2025We present a unified model capable of simultaneously grounding both spoken language and non-speech sounds within a visual scene, addressing key limitations in current audio-visual grounding models. Existing approaches are typically limited to handling either speech or non-speech sounds independently, or at best, together but sequentially without mixing. This limitation prevents them from capturing the complexity of real-world audio sources that are often mixed. Our approach introduces a 'mix-and-separate' framework with audio-visual alignment objectives that jointly learn correspondence and disentanglement using mixed audio. Through these objectives, our model learns to produce distinct embeddings for each audio type, enabling effective disentanglement and grounding across mixed audio sources. Additionally, we created a new dataset to evaluate simultaneous grounding of mixed audio sources, demonstrating that our model outperforms prior methods. Our approach also achieves comparable or better performance in standard segmentation and cross-modal retrieval tasks, highlighting the benefits of our mix-and-separate approach.
Let Me Finish My Sentence: Video Temporal Grounding with Holistic Text Understanding
Oct 17, 2024


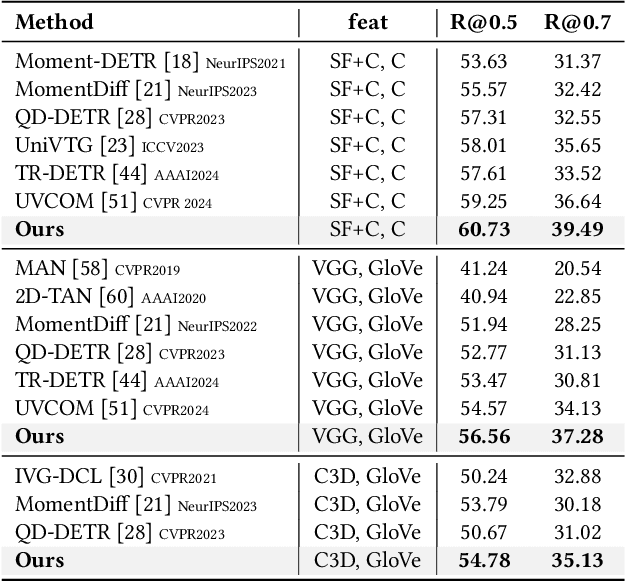
Video Temporal Grounding (VTG) aims to identify visual frames in a video clip that match text queries. Recent studies in VTG employ cross-attention to correlate visual frames and text queries as individual token sequences. However, these approaches overlook a crucial aspect of the problem: a holistic understanding of the query sentence. A model may capture correlations between individual word tokens and arbitrary visual frames while possibly missing out on the global meaning. To address this, we introduce two primary contributions: (1) a visual frame-level gate mechanism that incorporates holistic textual information, (2) cross-modal alignment loss to learn the fine-grained correlation between query and relevant frames. As a result, we regularize the effect of individual word tokens and suppress irrelevant visual frames. We demonstrate that our method outperforms state-of-the-art approaches in VTG benchmarks, indicating that holistic text understanding guides the model to focus on the semantically important parts within the video.
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Jul 18, 2024Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
Sound Source Localization is All about Cross-Modal Alignment
Sep 19, 2023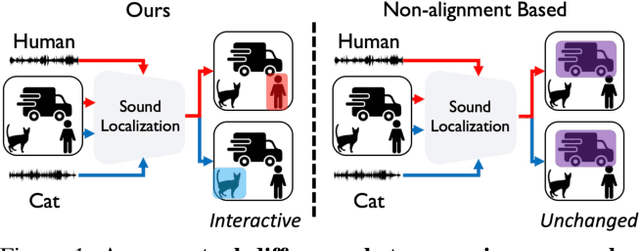
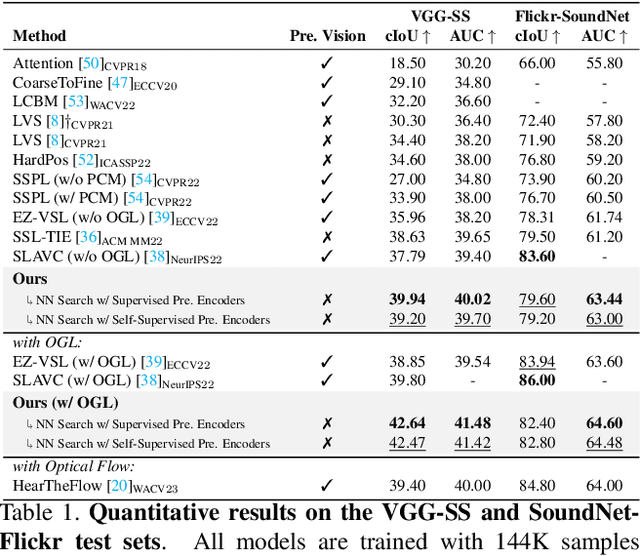
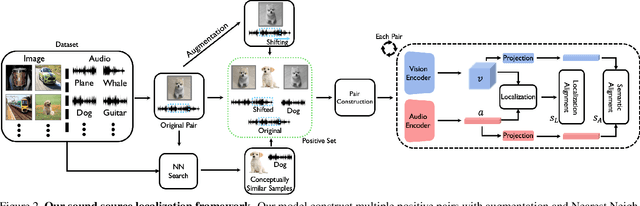
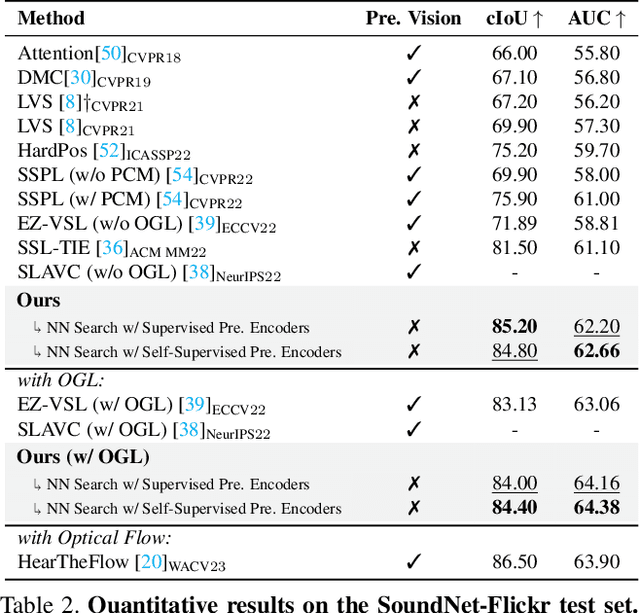
Humans can easily perceive the direction of sound sources in a visual scene, termed sound source localization. Recent studies on learning-based sound source localization have mainly explored the problem from a localization perspective. However, prior arts and existing benchmarks do not account for a more important aspect of the problem, cross-modal semantic understanding, which is essential for genuine sound source localization. Cross-modal semantic understanding is important in understanding semantically mismatched audio-visual events, e.g., silent objects, or off-screen sounds. To account for this, we propose a cross-modal alignment task as a joint task with sound source localization to better learn the interaction between audio and visual modalities. Thereby, we achieve high localization performance with strong cross-modal semantic understanding. Our method outperforms the state-of-the-art approaches in both sound source localization and cross-modal retrieval. Our work suggests that jointly tackling both tasks is necessary to conquer genuine sound source localization.
Hindi as a Second Language: Improving Visually Grounded Speech with Semantically Similar Samples
Mar 30, 2023



The objective of this work is to explore the learning of visually grounded speech models (VGS) from multilingual perspective. Bilingual VGS models are generally trained with an equal number of spoken captions from both languages. However, in reality, there can be an imbalance among the languages for the available spoken captions. Our key contribution in this work is to leverage the power of a high-resource language in a bilingual visually grounded speech model to improve the performance of a low-resource language. We introduce two methods to distill the knowledge of high-resource language into low-resource languages: (1) incorporating a strong pre-trained high-resource language encoder and (2) using semantically similar spoken captions. Our experiments show that combining these two approaches effectively enables the low-resource language to surpass the performances of monolingual and bilingual counterparts for cross-modal retrieval tasks.
Generative Bias for Visual Question Answering
Aug 02, 2022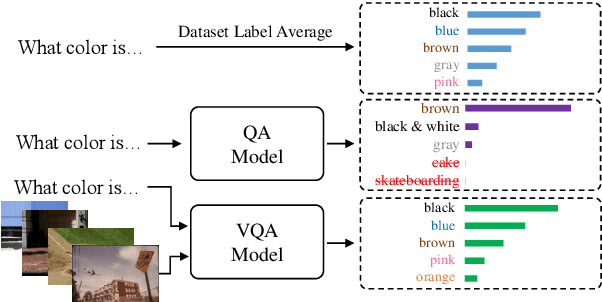
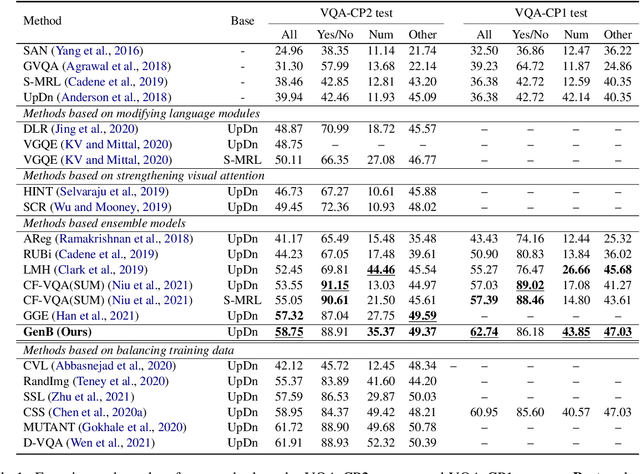

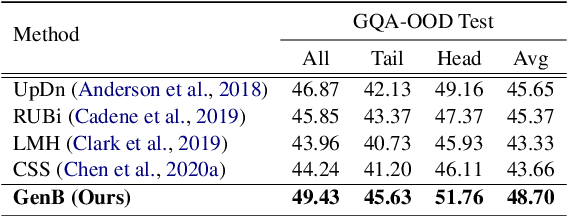
The task of Visual Question Answering (VQA) is known to be plagued by the issue of VQA models exploiting biases within the dataset to make its final prediction. Many previous ensemble based debiasing methods have been proposed where an additional model is purposefully trained to be biased in order to aid in training a robust target model. However, these methods compute the bias for a model from the label statistics of the training data or directly from single modal branches. In contrast, in this work, in order to better learn the bias a target VQA model suffers from, we propose a generative method to train the bias model \emph{directly from the target model}, called GenB. In particular, GenB employs a generative network to learn the bias through a combination of the adversarial objective and knowledge distillation. We then debias our target model with GenB as a bias model, and show through extensive experiments the effects of our method on various VQA bias datasets including VQA-CP2, VQA-CP1, GQA-OOD, and VQA-CE.
Audio-Visual Fusion Layers for Event Type Aware Video Recognition
Feb 12, 2022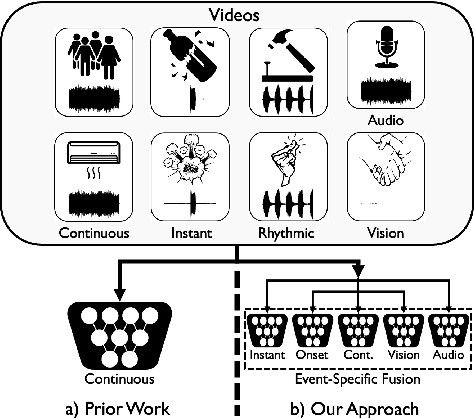
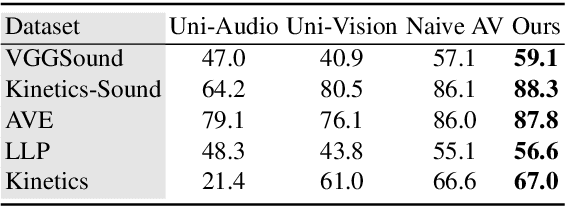
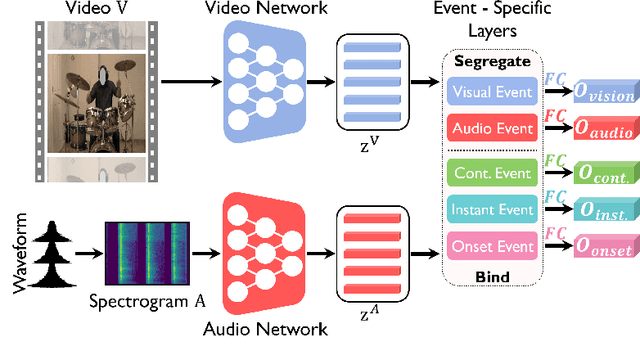
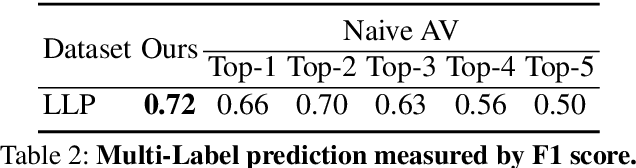
Human brain is continuously inundated with the multisensory information and their complex interactions coming from the outside world at any given moment. Such information is automatically analyzed by binding or segregating in our brain. While this task might seem effortless for human brains, it is extremely challenging to build a machine that can perform similar tasks since complex interactions cannot be dealt with single type of integration but requires more sophisticated approaches. In this paper, we propose a new model to address the multisensory integration problem with individual event-specific layers in a multi-task learning scheme. Unlike previous works where single type of fusion is used, we design event-specific layers to deal with different audio-visual relationship tasks, enabling different ways of audio-visual formation. Experimental results show that our event-specific layers can discover unique properties of the audio-visual relationships in the videos. Moreover, although our network is formulated with single labels, it can output additional true multi-labels to represent the given videos. We demonstrate that our proposed framework also exposes the modality bias of the video data category-wise and dataset-wise manner in popular benchmark datasets.
Learning Sound Localization Better From Semantically Similar Samples
Feb 07, 2022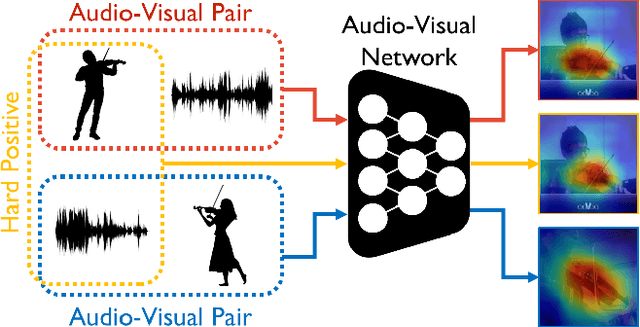



The objective of this work is to localize the sound sources in visual scenes. Existing audio-visual works employ contrastive learning by assigning corresponding audio-visual pairs from the same source as positives while randomly mismatched pairs as negatives. However, these negative pairs may contain semantically matched audio-visual information. Thus, these semantically correlated pairs, "hard positives", are mistakenly grouped as negatives. Our key contribution is showing that hard positives can give similar response maps to the corresponding pairs. Our approach incorporates these hard positives by adding their response maps into a contrastive learning objective directly. We demonstrate the effectiveness of our approach on VGG-SS and SoundNet-Flickr test sets, showing favorable performance to the state-of-the-art methods.