 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidTune: Creating Video Soundtracks with Generative Music and Contextual Thumbnails
Jan 17, 2026Music shapes the tone of videos, yet creators often struggle to find soundtracks that match their video's mood and narrative. Recent text-to-music models let creators generate music from text prompts, but our formative study (N=8) shows creators struggle to construct diverse prompts, quickly review and compare tracks, and understand their impact on the video. We present VidTune, a system that supports soundtrack creation by generating diverse music options from a creator's prompt and producing contextual thumbnails for rapid review. VidTune extracts representative video subjects to ground thumbnails in context, maps each track's valence and energy onto visual cues like color and brightness, and depicts prominent genres and instruments. Creators can refine tracks through natural language edits, which VidTune expands into new generations. In a controlled user study (N=12) and an exploratory case study (N=6), participants found VidTune helpful for efficiently reviewing and comparing music options and described the process as playful and enriching.
Rewriting Video: Text-Driven Reauthoring of Video Footage
Jan 13, 2026Video is a powerful medium for communication and storytelling, yet reauthoring existing footage remains challenging. Even simple edits often demand expertise, time, and careful planning, constraining how creators envision and shape their narratives. Recent advances in generative AI suggest a new paradigm: what if editing a video were as straightforward as rewriting text? To investigate this, we present a tech probe and a study on text-driven video reauthoring. Our approach involves two technical contributions: (1) a generative reconstruction algorithm that reverse-engineers video into an editable text prompt, and (2) an interactive probe, Rewrite Kit, that allows creators to manipulate these prompts. A technical evaluation of the algorithm reveals a critical human-AI perceptual gap. A probe study with 12 creators surfaced novel use cases such as virtual reshooting, synthetic continuity, and aesthetic restyling. It also highlighted key tensions around coherence, control, and creative alignment in this new paradigm. Our work contributes empirical insights into the opportunities and challenges of text-driven video reauthoring, offering design implications for future co-creative video tools.
SweeperBot: Making 3D Browsing Accessible through View Analysis and Visual Question Answering
Nov 19, 2025Accessing 3D models remains challenging for Screen Reader (SR) users. While some existing 3D viewers allow creators to provide alternative text, they often lack sufficient detail about the 3D models. Grounded on a formative study, this paper introduces SweeperBot, a system that enables SR users to leverage visual question answering to explore and compare 3D models. SweeperBot answers SR users' visual questions by combining an optimal view selection technique with the strength of generative- and recognition-based foundation models. An expert review with 10 Blind and Low-Vision (BLV) users with SR experience demonstrated the feasibility of using SweeperBot to assist BLV users in exploring and comparing 3D models. The quality of the descriptions generated by SweeperBot was validated by a second survey study with 30 sighted participants.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
VideoMix: Aggregating How-To Videos for Task-Oriented Learning
Mar 27, 2025Tutorial videos are a valuable resource for people looking to learn new tasks. People often learn these skills by viewing multiple tutorial videos to get an overall understanding of a task by looking at different approaches to achieve the task. However, navigating through multiple videos can be time-consuming and mentally demanding as these videos are scattered and not easy to skim. We propose VideoMix, a system that helps users gain a holistic understanding of a how-to task by aggregating information from multiple videos on the task. Insights from our formative study (N=12) reveal that learners value understanding potential outcomes, required materials, alternative methods, and important details shared by different videos. Powered by a Vision-Language Model pipeline, VideoMix extracts and organizes this information, presenting concise textual summaries alongside relevant video clips, enabling users to quickly digest and navigate the content. A comparative user study (N=12) demonstrated that VideoMix enabled participants to gain a more comprehensive understanding of tasks with greater efficiency than a baseline video interface, where videos are viewed independently. Our findings highlight the potential of a task-oriented, multi-video approach where videos are organized around a shared goal, offering an enhanced alternative to conventional video-based learning.
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Apr 05, 2024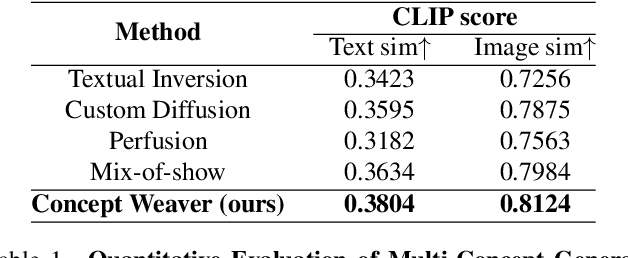
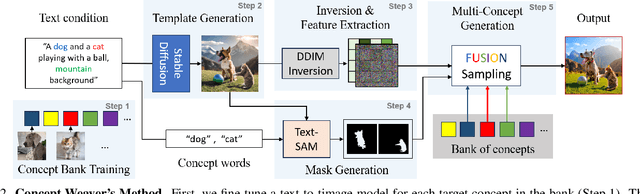
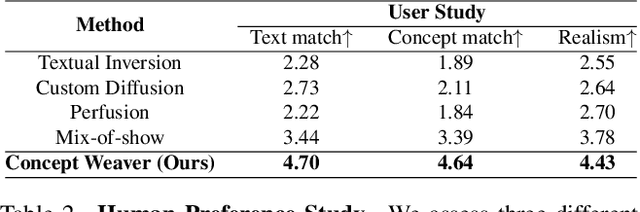
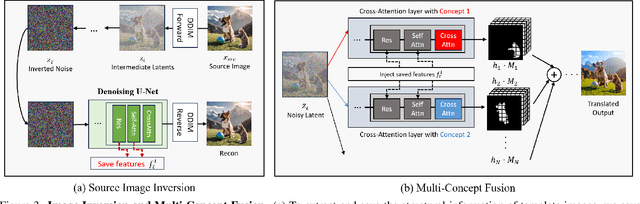
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
Next Steps for Human-Centered Generative AI: A Technical Perspective
Jun 27, 2023
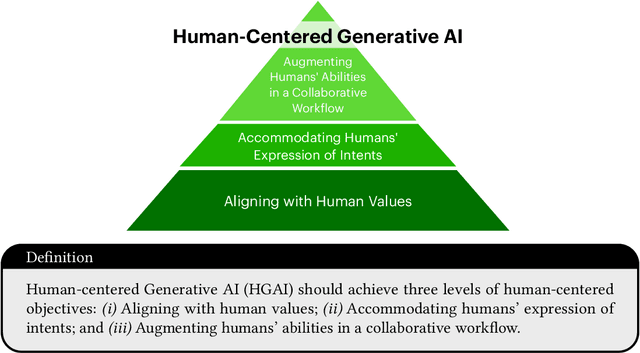
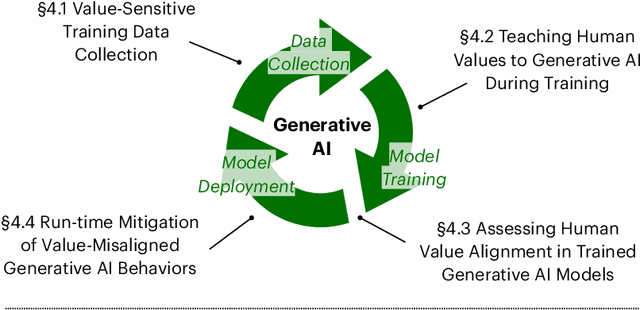

Through iterative, cross-disciplinary discussions, we define and propose next-steps for Human-centered Generative AI (HGAI) from a technical perspective. We contribute a roadmap that lays out future directions of Generative AI spanning three levels: Aligning with human values; Accommodating humans' expression of intents; and Augmenting humans' abilities in a collaborative workflow. This roadmap intends to draw interdisciplinary research teams to a comprehensive list of emergent ideas in HGAI, identifying their interested topics while maintaining a coherent big picture of the future work landscape.
ReelFramer: Co-creating News Reels on Social Media with Generative AI
Apr 19, 2023



Short videos on social media are a prime way many young people find and consume content. News outlets would like to reach audiences through news reels, but currently struggle to translate traditional journalistic formats into the short, entertaining videos that match the style of the platform. There are many ways to frame a reel-style narrative around a news story, and selecting one is a challenge. Different news stories call for different framings, and require a different trade-off between entertainment and information. We present a system called ReelFramer that uses text and image generation to help journalists explore multiple narrative framings for a story, then generate scripts, character boards and storyboards they can edit and iterate on. A user study of five graduate students in journalism-related fields found the system greatly eased the burden of transforming a written story into a reel, and that exploring framings to find the right one was a rewarding process.
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022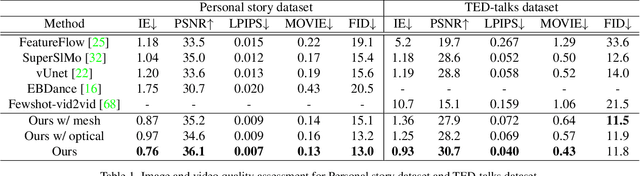
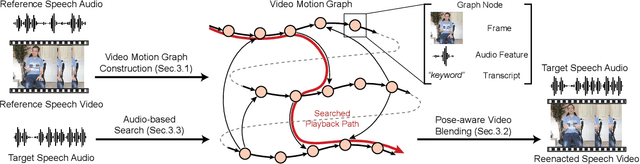
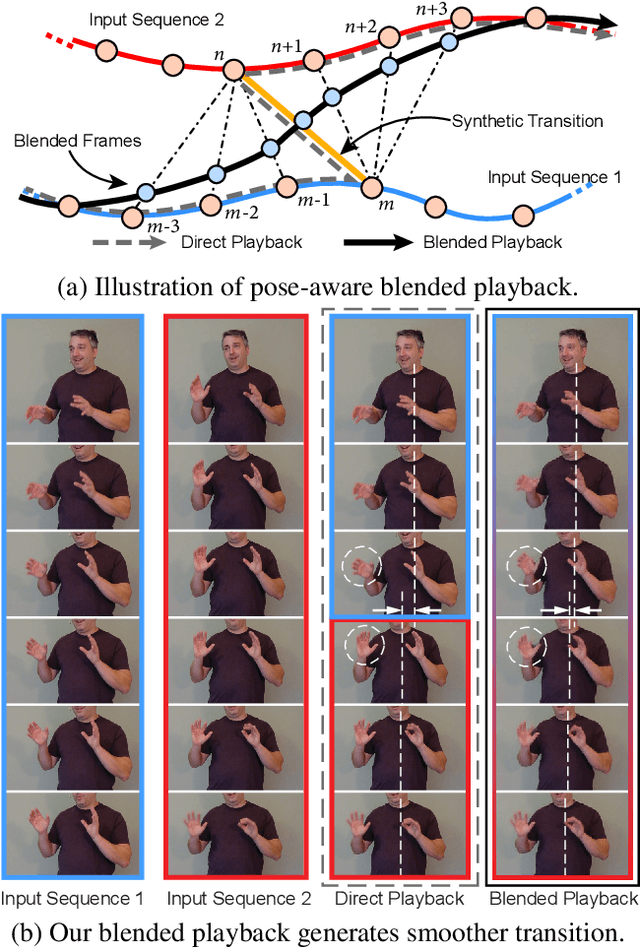
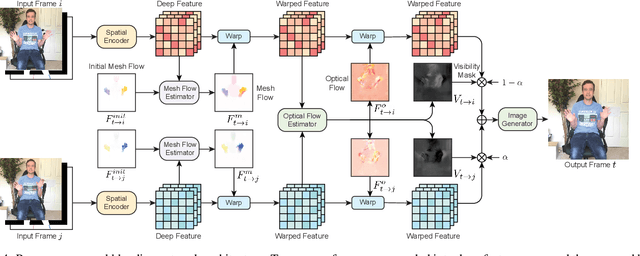
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.
Audio-Visual Fusion Layers for Event Type Aware Video Recognition
Feb 12, 2022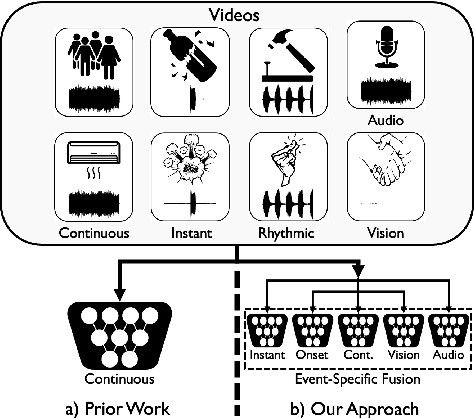
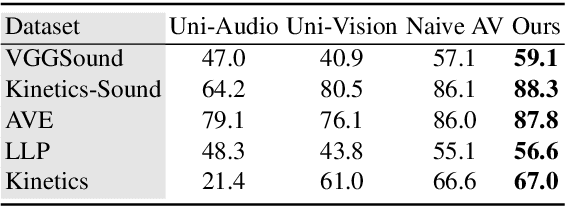
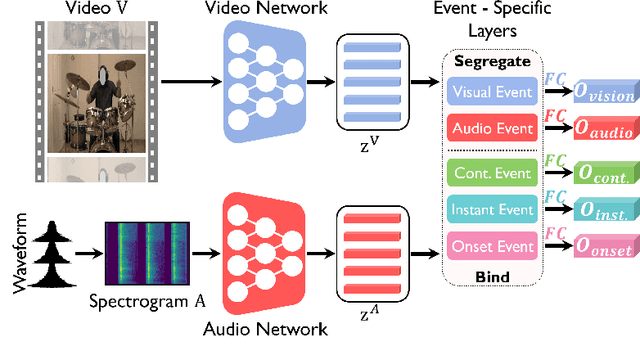
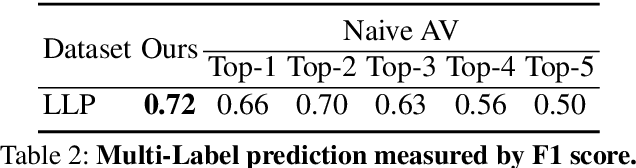
Human brain is continuously inundated with the multisensory information and their complex interactions coming from the outside world at any given moment. Such information is automatically analyzed by binding or segregating in our brain. While this task might seem effortless for human brains, it is extremely challenging to build a machine that can perform similar tasks since complex interactions cannot be dealt with single type of integration but requires more sophisticated approaches. In this paper, we propose a new model to address the multisensory integration problem with individual event-specific layers in a multi-task learning scheme. Unlike previous works where single type of fusion is used, we design event-specific layers to deal with different audio-visual relationship tasks, enabling different ways of audio-visual formation. Experimental results show that our event-specific layers can discover unique properties of the audio-visual relationships in the videos. Moreover, although our network is formulated with single labels, it can output additional true multi-labels to represent the given videos. We demonstrate that our proposed framework also exposes the modality bias of the video data category-wise and dataset-wise manner in popular benchmark datasets.