 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinematic Audio Source Separation Using Visual Cues
Mar 27, 2026Cinematic Audio Source Separation (CASS) aims to decompose mixed film audio into speech, music, and sound effects, enabling applications like dubbing and remastering. Existing CASS approaches are audio-only, overlooking the inherent audio-visual nature of films, where sounds often align with visual cues. We present the first framework for audio-visual CASS (AV-CASS), leveraging visual context to enhance separation quality. Our method formulates CASS as a conditional generative modeling problem using conditional flow matching, enabling multimodal audio source separation. To address the lack of cinematic datasets with isolated sound tracks, we introduce a training data synthesis pipeline that pairs in-the-wild audio and video streams (e.g., facial videos for speech, scene videos for effects) and design a dedicated visual encoder for this dual-stream setup. Trained entirely on synthetic data, our model generalizes effectively to real-world cinematic content and achieves strong performance on synthetic, real-world, and audio-only CASS benchmarks. Code and demo are available at \url{https://cass-flowmatching.github.io}.
Hearing and Seeing Through CLIP: A Framework for Self-Supervised Sound Source Localization
May 08, 2025



Large-scale vision-language models demonstrate strong multimodal alignment and generalization across diverse tasks. Among them, CLIP stands out as one of the most successful approaches. In this work, we extend the application of CLIP to sound source localization, proposing a self-supervised method operates without explicit text input. We introduce a framework that maps audios into tokens compatible with CLIP's text encoder, producing audio-driven embeddings. These embeddings are used to generate sounding region masks, from which visual features are extracted and aligned with the audio embeddings through a contrastive audio-visual correspondence objective. Our findings show that alignment knowledge of pre-trained multimodal foundation model enables our method to generate more complete and compact localization for sounding objects. We further propose an LLM-guided extension that distills object-aware audio-visual scene understanding into the model during training to enhance alignment. Extensive experiments across five diverse tasks demonstrate that our method, in all variants, outperforms state-of-the-art approaches and achieves strong generalization in zero-shot settings.
Seeing Speech and Sound: Distinguishing and Locating Audios in Visual Scenes
Mar 24, 2025We present a unified model capable of simultaneously grounding both spoken language and non-speech sounds within a visual scene, addressing key limitations in current audio-visual grounding models. Existing approaches are typically limited to handling either speech or non-speech sounds independently, or at best, together but sequentially without mixing. This limitation prevents them from capturing the complexity of real-world audio sources that are often mixed. Our approach introduces a 'mix-and-separate' framework with audio-visual alignment objectives that jointly learn correspondence and disentanglement using mixed audio. Through these objectives, our model learns to produce distinct embeddings for each audio type, enabling effective disentanglement and grounding across mixed audio sources. Additionally, we created a new dataset to evaluate simultaneous grounding of mixed audio sources, demonstrating that our model outperforms prior methods. Our approach also achieves comparable or better performance in standard segmentation and cross-modal retrieval tasks, highlighting the benefits of our mix-and-separate approach.
Sound2Vision: Generating Diverse Visuals from Audio through Cross-Modal Latent Alignment
Dec 09, 2024



How does audio describe the world around us? In this work, we propose a method for generating images of visual scenes from diverse in-the-wild sounds. This cross-modal generation task is challenging due to the significant information gap between auditory and visual signals. We address this challenge by designing a model that aligns audio-visual modalities by enriching audio features with visual information and translating them into the visual latent space. These features are then fed into the pre-trained image generator to produce images. To enhance image quality, we use sound source localization to select audio-visual pairs with strong cross-modal correlations. Our method achieves substantially better results on the VEGAS and VGGSound datasets compared to previous work and demonstrates control over the generation process through simple manipulations to the input waveform or latent space. Furthermore, we analyze the geometric properties of the learned embedding space and demonstrate that our learning approach effectively aligns audio-visual signals for cross-modal generation. Based on this analysis, we show that our method is agnostic to specific design choices, showing its generalizability by integrating various model architectures and different types of audio-visual data.
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
Oct 23, 2024
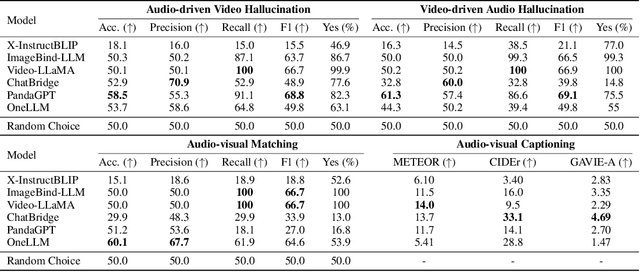

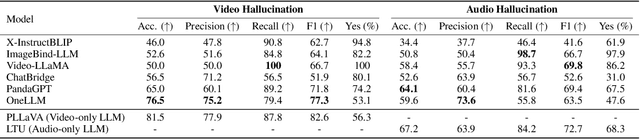
Following the success of Large Language Models (LLMs), expanding their boundaries to new modalities represents a significant paradigm shift in multimodal understanding. Human perception is inherently multimodal, relying not only on text but also on auditory and visual cues for a complete understanding of the world. In recognition of this fact, audio-visual LLMs have recently emerged. Despite promising developments, the lack of dedicated benchmarks poses challenges for understanding and evaluating models. In this work, we show that audio-visual LLMs struggle to discern subtle relationships between audio and visual signals, leading to hallucinations, underscoring the need for reliable benchmarks. To address this, we introduce AVHBench, the first comprehensive benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs. Our benchmark includes tests for assessing hallucinations, as well as the cross-modal matching and reasoning abilities of these models. Our results reveal that most existing audio-visual LLMs struggle with hallucinations caused by cross-interactions between modalities, due to their limited capacity to perceive complex multimodal signals and their relationships. Additionally, we demonstrate that simple training with our AVHBench improves robustness of audio-visual LLMs against hallucinations.
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Jul 18, 2024Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
ElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions
Jul 11, 2024



Transformers have rapidly overtaken CNN-based architectures as the new standard in audio classification. Transformer-based models, such as the Audio Spectrogram Transformers (AST), also inherit the fixed-size input paradigm from CNNs. However, this leads to performance degradation for ASTs in the inference when input lengths vary from the training. This paper introduces an approach that enables the use of variable-length audio inputs with AST models during both training and inference. By employing sequence packing, our method ElasticAST, accommodates any audio length during training, thereby offering flexibility across all lengths and resolutions at the inference. This flexibility allows ElasticAST to maintain evaluation capabilities at various lengths or resolutions and achieve similar performance to standard ASTs trained at specific lengths or resolutions. Moreover, experiments demonstrate ElasticAST's better performance when trained and evaluated on native-length audio datasets.
Audio Mamba: Bidirectional State Space Model for Audio Representation Learning
Jun 05, 2024Transformers have rapidly become the preferred choice for audio classification, surpassing methods based on CNNs. However, Audio Spectrogram Transformers (ASTs) exhibit quadratic scaling due to self-attention. The removal of this quadratic self-attention cost presents an appealing direction. Recently, state space models (SSMs), such as Mamba, have demonstrated potential in language and vision tasks in this regard. In this study, we explore whether reliance on self-attention is necessary for audio classification tasks. By introducing Audio Mamba (AuM), the first self-attention-free, purely SSM-based model for audio classification, we aim to address this question. We evaluate AuM on various audio datasets - comprising six different benchmarks - where it achieves comparable or better performance compared to well-established AST model.
From Coarse to Fine: Efficient Training for Audio Spectrogram Transformers
Jan 16, 2024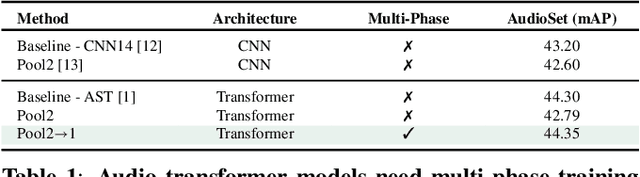
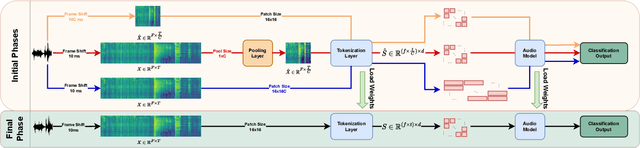
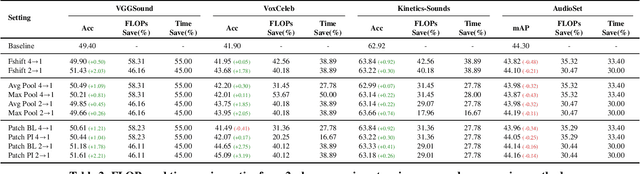
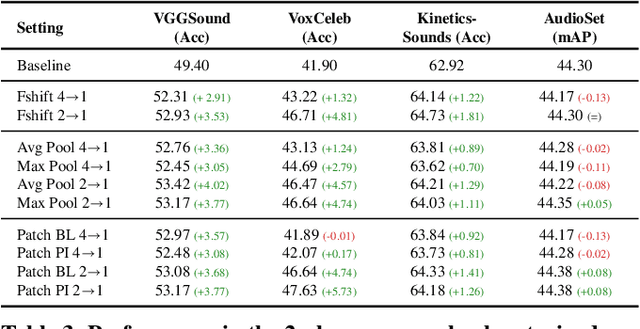
Transformers have become central to recent advances in audio classification. However, training an audio spectrogram transformer, e.g. AST, from scratch can be resource and time-intensive. Furthermore, the complexity of transformers heavily depends on the input audio spectrogram size. In this work, we aim to optimize AST training by linking to the resolution in the time-axis. We introduce multi-phase training of audio spectrogram transformers by connecting the seminal idea of coarse-to-fine with transformer models. To achieve this, we propose a set of methods for temporal compression. By employing one of these methods, the transformer model learns from lower-resolution (coarse) data in the initial phases, and then is fine-tuned with high-resolution data later in a curriculum learning strategy. Experimental results demonstrate that the proposed training mechanism for AST leads to improved (or on-par) performance with faster convergence, i.e. requiring fewer computational resources and less time. This approach is also generalizable to other AST-based methods regardless of their learning paradigms.
Can CLIP Help Sound Source Localization?
Nov 07, 2023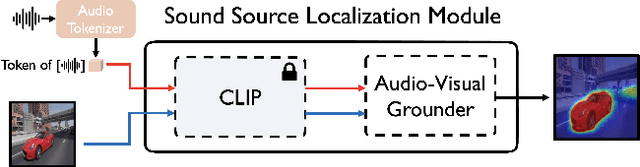
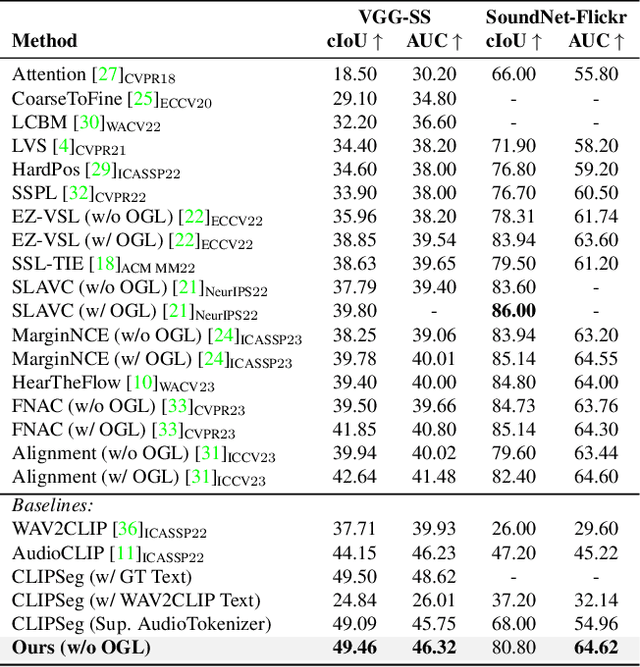
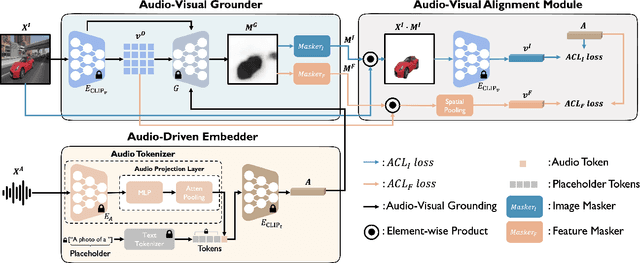
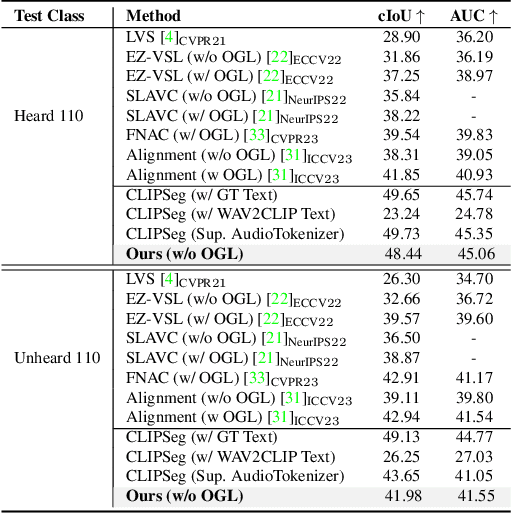
Large-scale pre-trained image-text models demonstrate remarkable versatility across diverse tasks, benefiting from their robust representational capabilities and effective multimodal alignment. We extend the application of these models, specifically CLIP, to the domain of sound source localization. Unlike conventional approaches, we employ the pre-trained CLIP model without explicit text input, relying solely on the audio-visual correspondence. To this end, we introduce a framework that translates audio signals into tokens compatible with CLIP's text encoder, yielding audio-driven embeddings. By directly using these embeddings, our method generates audio-grounded masks for the provided audio, extracts audio-grounded image features from the highlighted regions, and aligns them with the audio-driven embeddings using the audio-visual correspondence objective. Our findings suggest that utilizing pre-trained image-text models enable our model to generate more complete and compact localization maps for the sounding objects. Extensive experiments show that our method outperforms state-of-the-art approaches by a significant margin.