 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing and Seeing Through CLIP: A Framework for Self-Supervised Sound Source Localization
May 08, 2025



Large-scale vision-language models demonstrate strong multimodal alignment and generalization across diverse tasks. Among them, CLIP stands out as one of the most successful approaches. In this work, we extend the application of CLIP to sound source localization, proposing a self-supervised method operates without explicit text input. We introduce a framework that maps audios into tokens compatible with CLIP's text encoder, producing audio-driven embeddings. These embeddings are used to generate sounding region masks, from which visual features are extracted and aligned with the audio embeddings through a contrastive audio-visual correspondence objective. Our findings show that alignment knowledge of pre-trained multimodal foundation model enables our method to generate more complete and compact localization for sounding objects. We further propose an LLM-guided extension that distills object-aware audio-visual scene understanding into the model during training to enhance alignment. Extensive experiments across five diverse tasks demonstrate that our method, in all variants, outperforms state-of-the-art approaches and achieves strong generalization in zero-shot settings.
Can CLIP Help Sound Source Localization?
Nov 07, 2023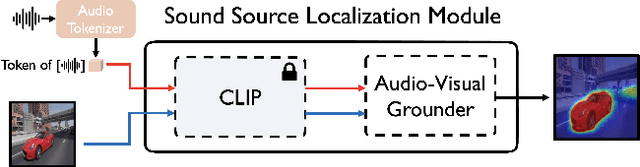
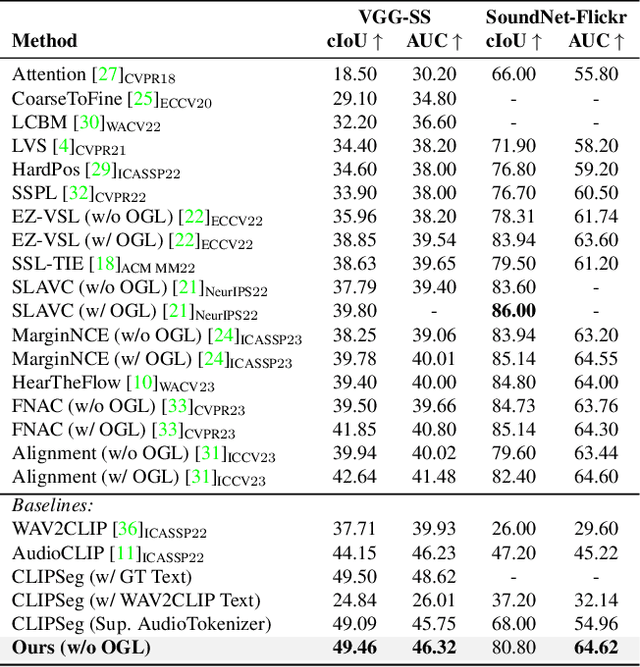
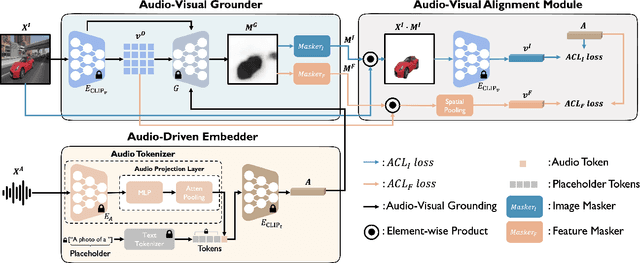
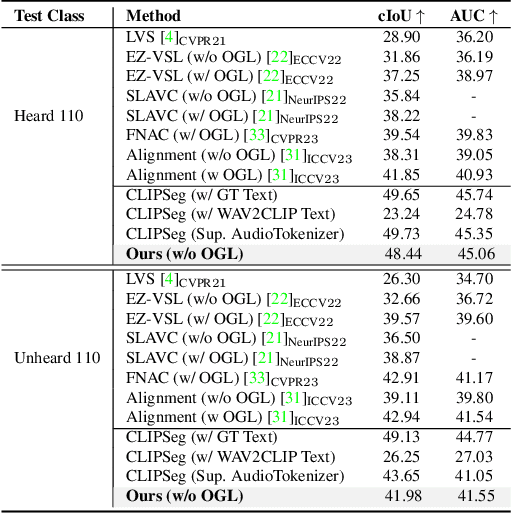
Large-scale pre-trained image-text models demonstrate remarkable versatility across diverse tasks, benefiting from their robust representational capabilities and effective multimodal alignment. We extend the application of these models, specifically CLIP, to the domain of sound source localization. Unlike conventional approaches, we employ the pre-trained CLIP model without explicit text input, relying solely on the audio-visual correspondence. To this end, we introduce a framework that translates audio signals into tokens compatible with CLIP's text encoder, yielding audio-driven embeddings. By directly using these embeddings, our method generates audio-grounded masks for the provided audio, extracts audio-grounded image features from the highlighted regions, and aligns them with the audio-driven embeddings using the audio-visual correspondence objective. Our findings suggest that utilizing pre-trained image-text models enable our model to generate more complete and compact localization maps for the sounding objects. Extensive experiments show that our method outperforms state-of-the-art approaches by a significant margin.
MarginNCE: Robust Sound Localization with a Negative Margin
Nov 03, 2022



The goal of this work is to localize sound sources in visual scenes with a self-supervised approach. Contrastive learning in the context of sound source localization leverages the natural correspondence between audio and visual signals where the audio-visual pairs from the same source are assumed as positive, while randomly selected pairs are negatives. However, this approach brings in noisy correspondences; for example, positive audio and visual pair signals that may be unrelated to each other, or negative pairs that may contain semantically similar samples to the positive one. Our key contribution in this work is to show that using a less strict decision boundary in contrastive learning can alleviate the effect of noisy correspondences in sound source localization. We propose a simple yet effective approach by slightly modifying the contrastive loss with a negative margin. Extensive experimental results show that our approach gives on-par or better performance than the state-of-the-art methods. Furthermore, we demonstrate that the introduction of a negative margin to existing methods results in a consistent improvement in performance.