 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Human-AI Conceptual Alignment through the Prism of Chess
Oct 29, 2025Do AI systems truly understand human concepts or merely mimic surface patterns? We investigate this through chess, where human creativity meets precise strategic concepts. Analyzing a 270M-parameter transformer that achieves grandmaster-level play, we uncover a striking paradox: while early layers encode human concepts like center control and knight outposts with up to 85\% accuracy, deeper layers, despite driving superior performance, drift toward alien representations, dropping to 50-65\% accuracy. To test conceptual robustness beyond memorization, we introduce the first Chess960 dataset: 240 expert-annotated positions across 6 strategic concepts. When opening theory is eliminated through randomized starting positions, concept recognition drops 10-20\% across all methods, revealing the model's reliance on memorized patterns rather than abstract understanding. Our layer-wise analysis exposes a fundamental tension in current architectures: the representations that win games diverge from those that align with human thinking. These findings suggest that as AI systems optimize for performance, they develop increasingly alien intelligence, a critical challenge for creative AI applications requiring genuine human-AI collaboration. Dataset and code are available at: https://github.com/slomasov/ChessConceptsLLM.
Cost-of-Pass: An Economic Framework for Evaluating Language Models
Apr 17, 2025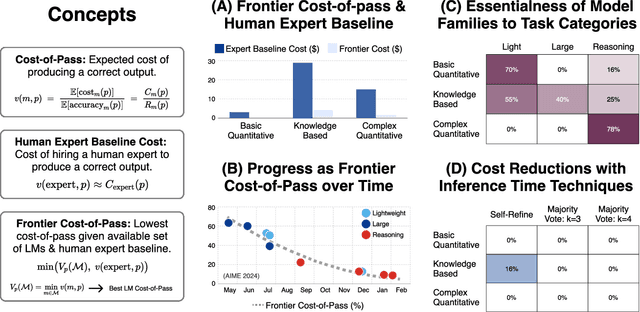
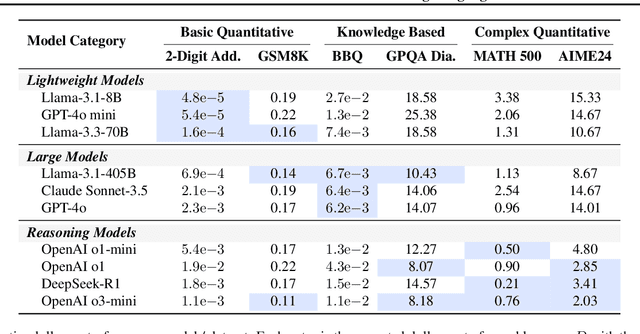
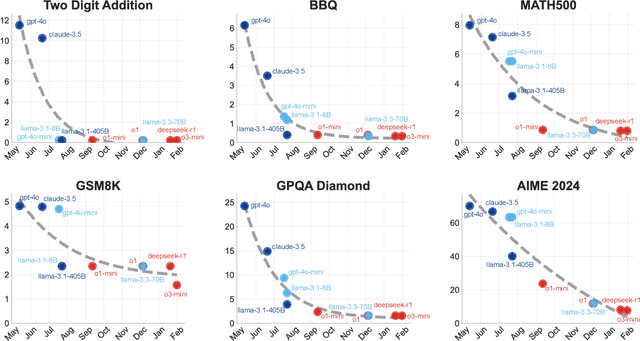

The widespread adoption of AI systems in the economy hinges on their ability to generate economic value that outweighs their inference costs. Evaluating this tradeoff requires metrics that account for both performance and costs. We propose a framework grounded in production theory for evaluating language models by combining accuracy and inference cost. We introduce "cost-of-pass", the expected monetary cost of generating a correct solution. We then define the "frontier cost-of-pass" as the minimum cost-of-pass achievable across available models or the "human-expert, using the approximate cost of hiring an expert. Our analysis reveals distinct economic insights. First, lightweight models are most cost-effective for basic quantitative tasks, large models for knowledge-intensive ones, and reasoning models for complex quantitative problems, despite higher per-token costs. Second, tracking this frontier cost-of-pass over the past year reveals significant progress, particularly for complex quantitative tasks where the cost has roughly halved every few months. Third, to trace key innovations driving this progress, we examine counterfactual frontiers: estimates of cost-efficiency without specific model classes. We find that innovations in lightweight, large, and reasoning models have been essential for pushing the frontier in basic quantitative, knowledge-intensive, and complex quantitative tasks, respectively. Finally, we assess the cost-reductions afforded by common inference-time techniques like majority voting and self-refinement, finding that their marginal accuracy gains rarely justify their costs. Our findings underscore that complementary model-level innovations are the primary drivers of cost-efficiency, and our economic framework provides a principled tool for measuring this progress and guiding deployment.
ElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions
Jul 11, 2024



Transformers have rapidly overtaken CNN-based architectures as the new standard in audio classification. Transformer-based models, such as the Audio Spectrogram Transformers (AST), also inherit the fixed-size input paradigm from CNNs. However, this leads to performance degradation for ASTs in the inference when input lengths vary from the training. This paper introduces an approach that enables the use of variable-length audio inputs with AST models during both training and inference. By employing sequence packing, our method ElasticAST, accommodates any audio length during training, thereby offering flexibility across all lengths and resolutions at the inference. This flexibility allows ElasticAST to maintain evaluation capabilities at various lengths or resolutions and achieve similar performance to standard ASTs trained at specific lengths or resolutions. Moreover, experiments demonstrate ElasticAST's better performance when trained and evaluated on native-length audio datasets.
Audio Mamba: Bidirectional State Space Model for Audio Representation Learning
Jun 05, 2024Transformers have rapidly become the preferred choice for audio classification, surpassing methods based on CNNs. However, Audio Spectrogram Transformers (ASTs) exhibit quadratic scaling due to self-attention. The removal of this quadratic self-attention cost presents an appealing direction. Recently, state space models (SSMs), such as Mamba, have demonstrated potential in language and vision tasks in this regard. In this study, we explore whether reliance on self-attention is necessary for audio classification tasks. By introducing Audio Mamba (AuM), the first self-attention-free, purely SSM-based model for audio classification, we aim to address this question. We evaluate AuM on various audio datasets - comprising six different benchmarks - where it achieves comparable or better performance compared to well-established AST model.
From Coarse to Fine: Efficient Training for Audio Spectrogram Transformers
Jan 16, 2024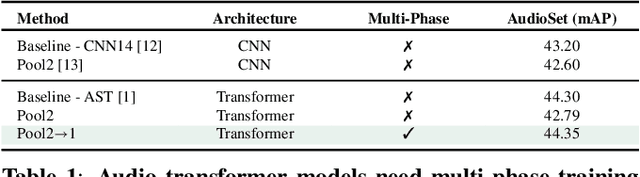
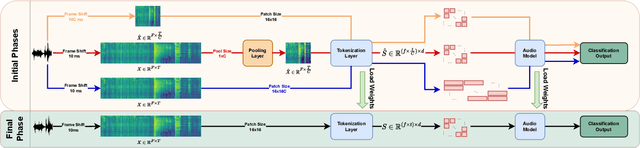
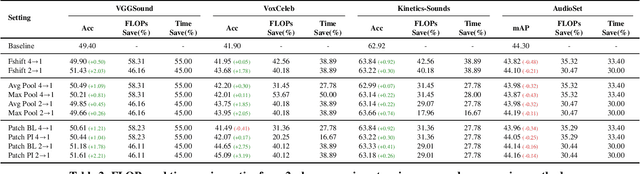
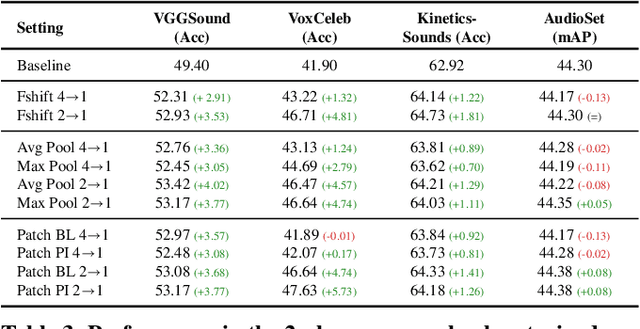
Transformers have become central to recent advances in audio classification. However, training an audio spectrogram transformer, e.g. AST, from scratch can be resource and time-intensive. Furthermore, the complexity of transformers heavily depends on the input audio spectrogram size. In this work, we aim to optimize AST training by linking to the resolution in the time-axis. We introduce multi-phase training of audio spectrogram transformers by connecting the seminal idea of coarse-to-fine with transformer models. To achieve this, we propose a set of methods for temporal compression. By employing one of these methods, the transformer model learns from lower-resolution (coarse) data in the initial phases, and then is fine-tuned with high-resolution data later in a curriculum learning strategy. Experimental results demonstrate that the proposed training mechanism for AST leads to improved (or on-par) performance with faster convergence, i.e. requiring fewer computational resources and less time. This approach is also generalizable to other AST-based methods regardless of their learning paradigms.
FlexiAST: Flexibility is What AST Needs
Jul 18, 2023



The objective of this work is to give patch-size flexibility to Audio Spectrogram Transformers (AST). Recent advancements in ASTs have shown superior performance in various audio-based tasks. However, the performance of standard ASTs degrades drastically when evaluated using different patch sizes from that used during training. As a result, AST models are typically re-trained to accommodate changes in patch sizes. To overcome this limitation, this paper proposes a training procedure to provide flexibility to standard AST models without architectural changes, allowing them to work with various patch sizes at the inference stage - FlexiAST. This proposed training approach simply utilizes random patch size selection and resizing of patch and positional embedding weights. Our experiments show that FlexiAST gives similar performance to standard AST models while maintaining its evaluation ability at various patch sizes on different datasets for audio classification tasks.