 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions
Jul 11, 2024



Transformers have rapidly overtaken CNN-based architectures as the new standard in audio classification. Transformer-based models, such as the Audio Spectrogram Transformers (AST), also inherit the fixed-size input paradigm from CNNs. However, this leads to performance degradation for ASTs in the inference when input lengths vary from the training. This paper introduces an approach that enables the use of variable-length audio inputs with AST models during both training and inference. By employing sequence packing, our method ElasticAST, accommodates any audio length during training, thereby offering flexibility across all lengths and resolutions at the inference. This flexibility allows ElasticAST to maintain evaluation capabilities at various lengths or resolutions and achieve similar performance to standard ASTs trained at specific lengths or resolutions. Moreover, experiments demonstrate ElasticAST's better performance when trained and evaluated on native-length audio datasets.
Audio Mamba: Bidirectional State Space Model for Audio Representation Learning
Jun 05, 2024Transformers have rapidly become the preferred choice for audio classification, surpassing methods based on CNNs. However, Audio Spectrogram Transformers (ASTs) exhibit quadratic scaling due to self-attention. The removal of this quadratic self-attention cost presents an appealing direction. Recently, state space models (SSMs), such as Mamba, have demonstrated potential in language and vision tasks in this regard. In this study, we explore whether reliance on self-attention is necessary for audio classification tasks. By introducing Audio Mamba (AuM), the first self-attention-free, purely SSM-based model for audio classification, we aim to address this question. We evaluate AuM on various audio datasets - comprising six different benchmarks - where it achieves comparable or better performance compared to well-established AST model.
From Coarse to Fine: Efficient Training for Audio Spectrogram Transformers
Jan 16, 2024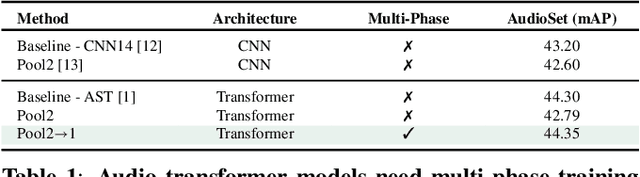
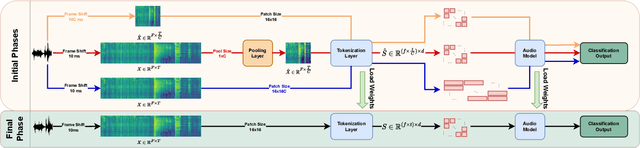
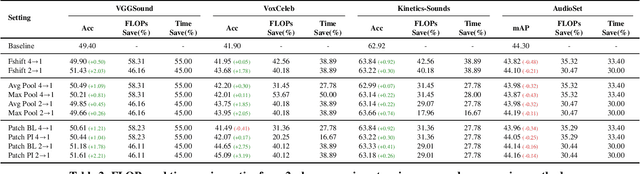
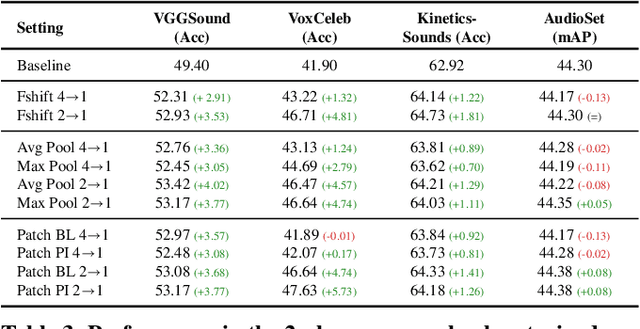
Transformers have become central to recent advances in audio classification. However, training an audio spectrogram transformer, e.g. AST, from scratch can be resource and time-intensive. Furthermore, the complexity of transformers heavily depends on the input audio spectrogram size. In this work, we aim to optimize AST training by linking to the resolution in the time-axis. We introduce multi-phase training of audio spectrogram transformers by connecting the seminal idea of coarse-to-fine with transformer models. To achieve this, we propose a set of methods for temporal compression. By employing one of these methods, the transformer model learns from lower-resolution (coarse) data in the initial phases, and then is fine-tuned with high-resolution data later in a curriculum learning strategy. Experimental results demonstrate that the proposed training mechanism for AST leads to improved (or on-par) performance with faster convergence, i.e. requiring fewer computational resources and less time. This approach is also generalizable to other AST-based methods regardless of their learning paradigms.
FlexiAST: Flexibility is What AST Needs
Jul 18, 2023



The objective of this work is to give patch-size flexibility to Audio Spectrogram Transformers (AST). Recent advancements in ASTs have shown superior performance in various audio-based tasks. However, the performance of standard ASTs degrades drastically when evaluated using different patch sizes from that used during training. As a result, AST models are typically re-trained to accommodate changes in patch sizes. To overcome this limitation, this paper proposes a training procedure to provide flexibility to standard AST models without architectural changes, allowing them to work with various patch sizes at the inference stage - FlexiAST. This proposed training approach simply utilizes random patch size selection and resizing of patch and positional embedding weights. Our experiments show that FlexiAST gives similar performance to standard AST models while maintaining its evaluation ability at various patch sizes on different datasets for audio classification tasks.
Decoupled Adversarial Contrastive Learning for Self-supervised Adversarial Robustness
Jul 22, 2022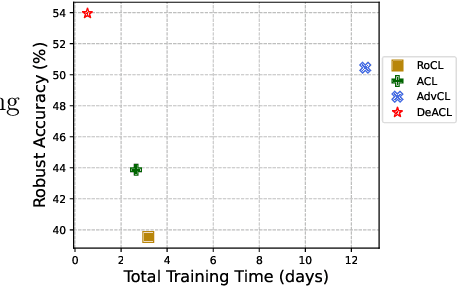

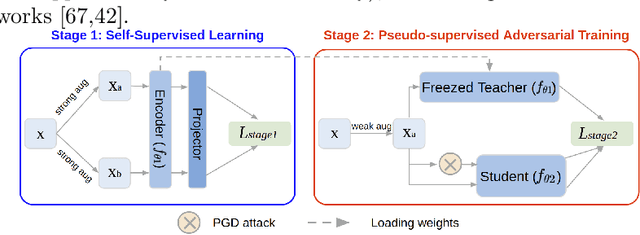

Adversarial training (AT) for robust representation learning and self-supervised learning (SSL) for unsupervised representation learning are two active research fields. Integrating AT into SSL, multiple prior works have accomplished a highly significant yet challenging task: learning robust representation without labels. A widely used framework is adversarial contrastive learning which couples AT and SSL, and thus constitute a very complex optimization problem. Inspired by the divide-and-conquer philosophy, we conjecture that it might be simplified as well as improved by solving two sub-problems: non-robust SSL and pseudo-supervised AT. This motivation shifts the focus of the task from seeking an optimal integrating strategy for a coupled problem to finding sub-solutions for sub-problems. With this said, this work discards prior practices of directly introducing AT to SSL frameworks and proposed a two-stage framework termed Decoupled Adversarial Contrastive Learning (DeACL). Extensive experimental results demonstrate that our DeACL achieves SOTA self-supervised adversarial robustness while significantly reducing the training time, which validates its effectiveness and efficiency. Moreover, our DeACL constitutes a more explainable solution, and its success also bridges the gap with semi-supervised AT for exploiting unlabeled samples for robust representation learning. The code is publicly accessible at https://github.com/pantheon5100/DeACL.
Noise Augmentation Is All You Need For FGSM Fast Adversarial Training: Catastrophic Overfitting And Robust Overfitting Require Different Augmentation
Feb 11, 2022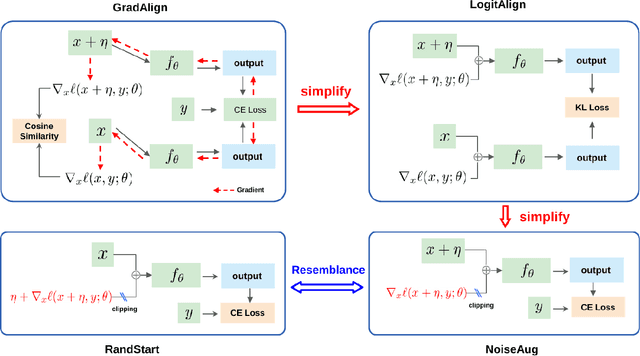
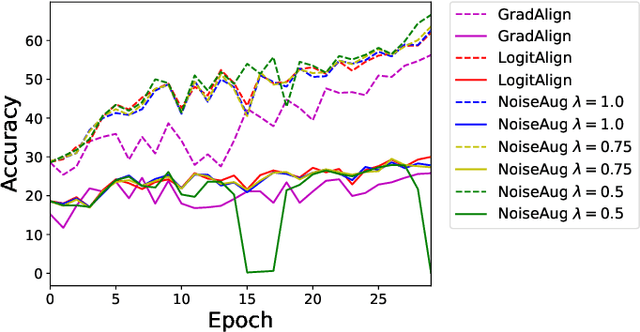
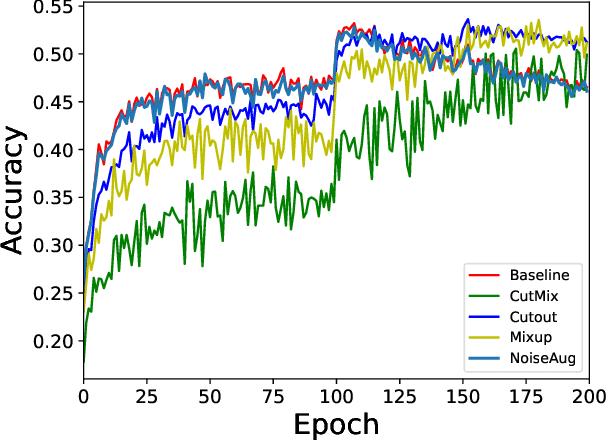
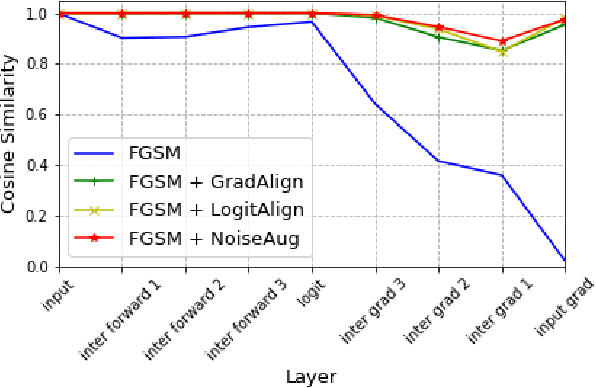
Adversarial training (AT) and its variants are the most effective approaches for obtaining adversarially robust models. A unique characteristic of AT is that an inner maximization problem needs to be solved repeatedly before the model weights can be updated, which makes the training slow. FGSM AT significantly improves its efficiency but it fails when the step size grows. The SOTA GradAlign makes FGSM AT compatible with a higher step size, however, its regularization on input gradient makes it 3 to 4 times slower than FGSM AT. Our proposed NoiseAug removes the extra computation overhead by directly regularizing on the input itself. The key contribution of this work lies in an empirical finding that single-step FGSM AT is not as hard as suggested in the past line of work: noise augmentation is all you need for (FGSM) fast AT. Towards understanding the success of our NoiseAug, we perform an extensive analysis and find that mitigating Catastrophic Overfitting (CO) and Robust Overfitting (RO) need different augmentations. Instead of more samples caused by data augmentation, we identify what makes NoiseAug effective for preventing CO might lie in its improved local linearity.