 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Augmentation Is All You Need For FGSM Fast Adversarial Training: Catastrophic Overfitting And Robust Overfitting Require Different Augmentation
Paper and Code
Feb 11, 2022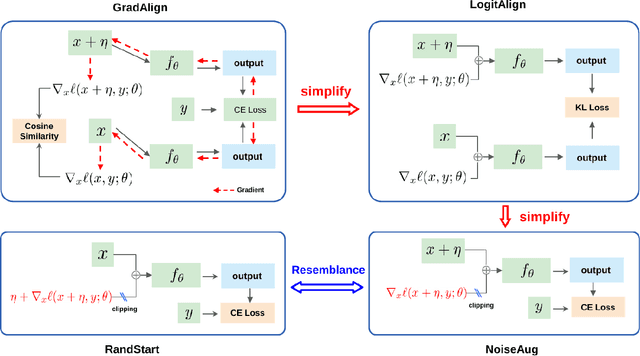
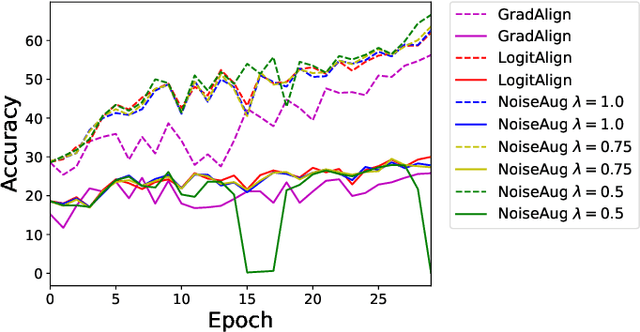
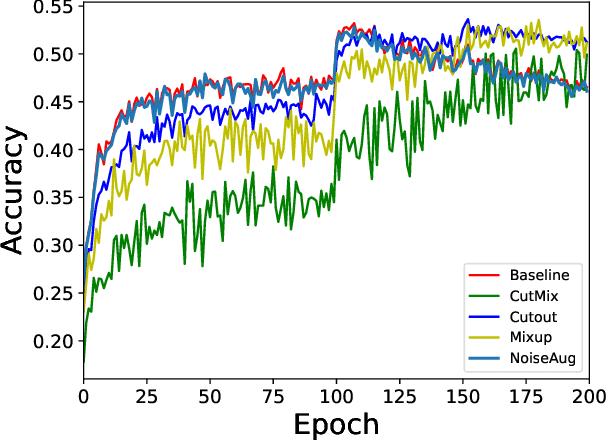
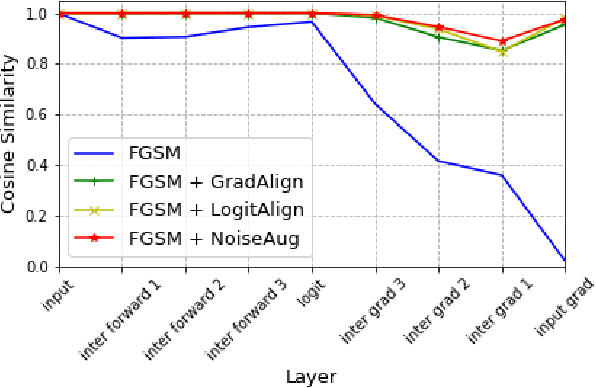
Adversarial training (AT) and its variants are the most effective approaches for obtaining adversarially robust models. A unique characteristic of AT is that an inner maximization problem needs to be solved repeatedly before the model weights can be updated, which makes the training slow. FGSM AT significantly improves its efficiency but it fails when the step size grows. The SOTA GradAlign makes FGSM AT compatible with a higher step size, however, its regularization on input gradient makes it 3 to 4 times slower than FGSM AT. Our proposed NoiseAug removes the extra computation overhead by directly regularizing on the input itself. The key contribution of this work lies in an empirical finding that single-step FGSM AT is not as hard as suggested in the past line of work: noise augmentation is all you need for (FGSM) fast AT. Towards understanding the success of our NoiseAug, we perform an extensive analysis and find that mitigating Catastrophic Overfitting (CO) and Robust Overfitting (RO) need different augmentations. Instead of more samples caused by data augmentation, we identify what makes NoiseAug effective for preventing CO might lie in its improved local linearity.