 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIConFace: Identity-Structure Asymmetric Conditioning for Unified Reference-Aware Face Restoration
May 04, 2026Blind face restoration is highly ill-posed under severe degradation, where identity-critical details may be missing from the degraded input. Same-identity references reduce this ambiguity, but mismatched pose, expression, illumination, age, makeup, or local facial states can lead to overuse of reference appearance. We propose \textbf{IConFace}, a unified reference-aware and no-reference framework with identity--structure asymmetric conditioning. References are distilled into a norm-weighted global AdaFace identity anchor for image-only modulation, while the degraded image is reinforced as the spatial structure anchor through low-rank residuals and block-wise degraded cross-attention with two-route memory. The resulting single checkpoint exploits references when available and falls back to no-reference restoration when absent, improving identity consistency, fine-detail recovery, and degraded-only restoration quality in a unified model.
EAPFusion: Intrinsic Evolving Auxiliary Prior Guidance for Infrared and Visible Image Fusion
May 03, 2026Infrared-visible image fusion aims to create an information-rich fused image by integrating the complementary thermal saliency from infrared sensing and fine textures from visible imaging. Such accurate fusion is essential for real-world perception applications in complex scenes, including nighttime autonomous driving, search and rescue, and surveillance, and can further benefit downstream tasks such as semantic segmentation. However, most existing fusion methods rely upon static trained weights that cannot adapt to scene-specific content at inference time, and often suffer from a granularity mismatch when coarse auxiliary semantics are injected, which makes it difficult to simultaneously highlight targets and preserve details. In this work, we propose EAPFusion to address these issues by using self-evolving intrinsic priors instead of relying on external auxiliary models. Concretely, EAPFusion maintains a compact set of intrinsic priors and progressively updates them across scales. These evolved priors are utilized to dynamically generate convolutional kernels, shifting the paradigm from fixed, pre-trained filters to instance-adaptive parameters via prior-conditioned dynamic convolution. Furthermore, we design a channel-level fusion module that shuffles and interleaves infrared and visible channels, applying local channel mixing to boost cross-modal complementarity. Experiments on different datasets, including cross-dataset evaluation and semantic segmentation, show that the proposed method achieves state-of-the-art quantitative and qualitative fusion results, and consistently boosts downstream performance. Code is coming soon.
Redefining Quality Criteria and Distance-Aware Score Modeling for Image Editing Assessment
Apr 14, 2026Recent advances in image editing have heightened the need for reliable Image Editing Quality Assessment (IEQA). Unlike traditional methods, IEQA requires complex reasoning over multimodal inputs and multi-dimensional assessments. Existing MLLM-based approaches often rely on human heuristic prompting, leading to two key limitations: rigid metric prompting and distance-agnostic score modeling. These issues hinder alignment with implicit human criteria and fail to capture the continuous structure of score spaces. To address this, we propose Define-and-Score Image Editing Quality Assessment (DS-IEQA), a unified framework that jointly learns evaluation criteria and score representations. Specifically, we introduce Feedback-Driven Metric Prompt Optimization (FDMPO) to automatically refine metric definitions via probabilistic feedback. Furthermore, we propose Token-Decoupled Distance Regression Loss (TDRL), which decouples numerical tokens from language modeling to explicitly model score continuity through expected distance minimization. Extensive experiments show our method's superior performance; it ranks 4th in the 2026 NTIRE X-AIGC Quality Assessment Track 2 without any additional training data.
The Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
DualTSR: Unified Dual-Diffusion Transformer for Scene Text Image Super-Resolution
Mar 15, 2026Scene Text Image Super-Resolution (STISR) aims to restore high-resolution details in low-resolution text images, which is crucial for both human readability and machine recognition. Existing methods, however, often depend on external Optical Character Recognition (OCR) models for textual priors or rely on complex multi-component architectures that are difficult to train and reproduce. In this paper, we introduce DualTSR, a unified end-to-end framework that addresses both issues. DualTSR employs a single multimodal transformer backbone trained with a dual diffusion objective. It simultaneously models the continuous distribution of high-resolution images via Conditional Flow Matching and the discrete distribution of textual content via discrete diffusion. This shared design enables visual and textual information to interact at every layer, allowing the model to infer text priors internally instead of relying on an external OCR module. Compared with prior multi-branch diffusion systems, DualTSR offers a simpler end-to-end formulation with fewer hand-crafted components. Experiments on synthetic Chinese benchmarks and a curated real-world evaluation protocol show that DualTSR achieves strong perceptual quality and text fidelity.
TPGDiff: Hierarchical Triple-Prior Guided Diffusion for Image Restoration
Jan 28, 2026All-in-one image restoration aims to address diverse degradation types using a single unified model. Existing methods typically rely on degradation priors to guide restoration, yet often struggle to reconstruct content in severely degraded regions. Although recent works leverage semantic information to facilitate content generation, integrating it into the shallow layers of diffusion models often disrupts spatial structures (\emph{e.g.}, blurring artifacts). To address this issue, we propose a Triple-Prior Guided Diffusion (TPGDiff) network for unified image restoration. TPGDiff incorporates degradation priors throughout the diffusion trajectory, while introducing structural priors into shallow layers and semantic priors into deep layers, enabling hierarchical and complementary prior guidance for image reconstruction. Specifically, we leverage multi-source structural cues as structural priors to capture fine-grained details and guide shallow layers representations. To complement this design, we further develop a distillation-driven semantic extractor that yields robust semantic priors, ensuring reliable high-level guidance at deep layers even under severe degradations. Furthermore, a degradation extractor is employed to learn degradation-aware priors, enabling stage-adaptive control of the diffusion process across all timesteps. Extensive experiments on both single- and multi-degradation benchmarks demonstrate that TPGDiff achieves superior performance and generalization across diverse restoration scenarios. Our project page is: https://leoyjtu.github.io/tpgdiff-project.
Towards Understanding Dual BN In Hybrid Adversarial Training
Mar 28, 2024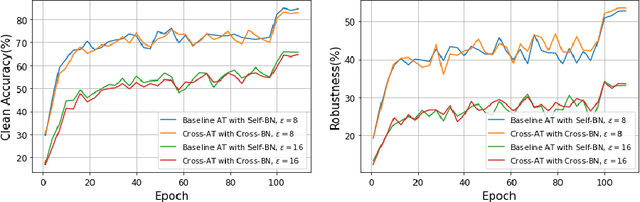


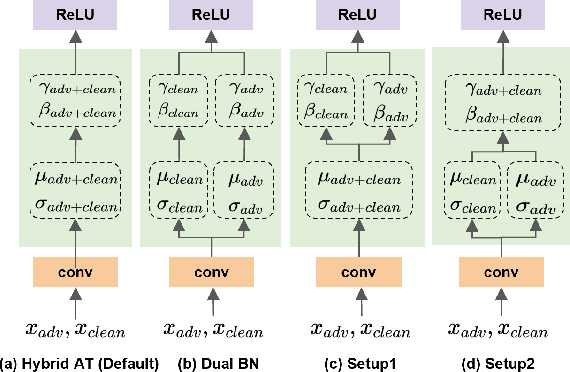
There is a growing concern about applying batch normalization (BN) in adversarial training (AT), especially when the model is trained on both adversarial samples and clean samples (termed Hybrid-AT). With the assumption that adversarial and clean samples are from two different domains, a common practice in prior works is to adopt Dual BN, where BN and BN are used for adversarial and clean branches, respectively. A popular belief for motivating Dual BN is that estimating normalization statistics of this mixture distribution is challenging and thus disentangling it for normalization achieves stronger robustness. In contrast to this belief, we reveal that disentangling statistics plays a less role than disentangling affine parameters in model training. This finding aligns with prior work (Rebuffi et al., 2023), and we build upon their research for further investigations. We demonstrate that the domain gap between adversarial and clean samples is not very large, which is counter-intuitive considering the significant influence of adversarial perturbation on the model accuracy. We further propose a two-task hypothesis which serves as the empirical foundation and a unified framework for Hybrid-AT improvement. We also investigate Dual BN in test-time and reveal that affine parameters characterize the robustness during inference. Overall, our work sheds new light on understanding the mechanism of Dual BN in Hybrid-AT and its underlying justification.
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023



It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
Multiple Object Tracking based on Occlusion-Aware Embedding Consistency Learning
Nov 05, 2023


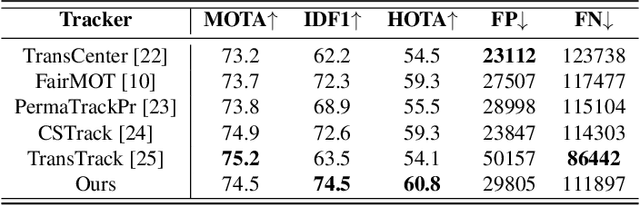
The Joint Detection and Embedding (JDE) framework has achieved remarkable progress for multiple object tracking. Existing methods often employ extracted embeddings to re-establish associations between new detections and previously disrupted tracks. However, the reliability of embeddings diminishes when the region of the occluded object frequently contains adjacent objects or clutters, especially in scenarios with severe occlusion. To alleviate this problem, we propose a novel multiple object tracking method based on visual embedding consistency, mainly including: 1) Occlusion Prediction Module (OPM) and 2) Occlusion-Aware Association Module (OAAM). The OPM predicts occlusion information for each true detection, facilitating the selection of valid samples for consistency learning of the track's visual embedding. The OAAM leverages occlusion cues and visual embeddings to generate two separate embeddings for each track, guaranteeing consistency in both unoccluded and occluded detections. By integrating these two modules, our method is capable of addressing track interruptions caused by occlusion in online tracking scenarios. Extensive experimental results demonstrate that our approach achieves promising performance levels in both unoccluded and occluded tracking scenarios.
ACDMSR: Accelerated Conditional Diffusion Models for Single Image Super-Resolution
Jul 03, 2023Diffusion models have gained significant popularity in the field of image-to-image translation. Previous efforts applying diffusion models to image super-resolution (SR) have demonstrated that iteratively refining pure Gaussian noise using a U-Net architecture trained on denoising at various noise levels can yield satisfactory high-resolution images from low-resolution inputs. However, this iterative refinement process comes with the drawback of low inference speed, which strongly limits its applications. To speed up inference and further enhance the performance, our research revisits diffusion models in image super-resolution and proposes a straightforward yet significant diffusion model-based super-resolution method called ACDMSR (accelerated conditional diffusion model for image super-resolution). Specifically, our method adapts the standard diffusion model to perform super-resolution through a deterministic iterative denoising process. Our study also highlights the effectiveness of using a pre-trained SR model to provide the conditional image of the given low-resolution (LR) image to achieve superior high-resolution results. We demonstrate that our method surpasses previous attempts in qualitative and quantitative results through extensive experiments conducted on benchmark datasets such as Set5, Set14, Urban100, BSD100, and Manga109. Moreover, our approach generates more visually realistic counterparts for low-resolution images, emphasizing its effectiveness in practical scenarios.