 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget-free Continual Learning with Soft-Winning SubNetworks
Mar 27, 2023



Inspired by Regularized Lottery Ticket Hypothesis (RLTH), which states that competitive smooth (non-binary) subnetworks exist within a dense network in continual learning tasks, we investigate two proposed architecture-based continual learning methods which sequentially learn and select adaptive binary- (WSN) and non-binary Soft-Subnetworks (SoftNet) for each task. WSN and SoftNet jointly learn the regularized model weights and task-adaptive non-binary masks of subnetworks associated with each task whilst attempting to select a small set of weights to be activated (winning ticket) by reusing weights of the prior subnetworks. Our proposed WSN and SoftNet are inherently immune to catastrophic forgetting as each selected subnetwork model does not infringe upon other subnetworks in Task Incremental Learning (TIL). In TIL, binary masks spawned per winning ticket are encoded into one N-bit binary digit mask, then compressed using Huffman coding for a sub-linear increase in network capacity to the number of tasks. Surprisingly, in the inference step, SoftNet generated by injecting small noises to the backgrounds of acquired WSN (holding the foregrounds of WSN) provides excellent forward transfer power for future tasks in TIL. SoftNet shows its effectiveness over WSN in regularizing parameters to tackle the overfitting, to a few examples in Few-shot Class Incremental Learning (FSCIL).
Self-Supervised Visual Representation Learning via Residual Momentum
Nov 21, 2022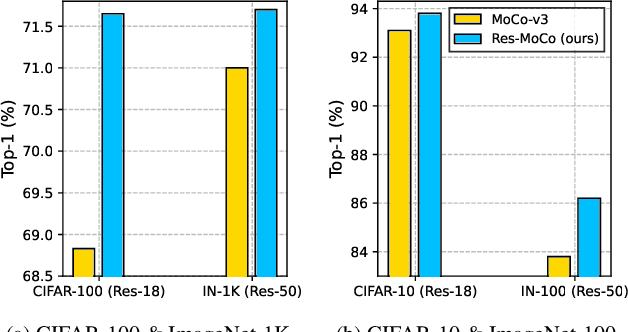
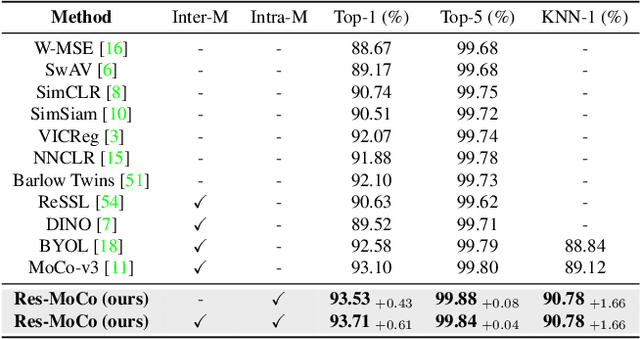
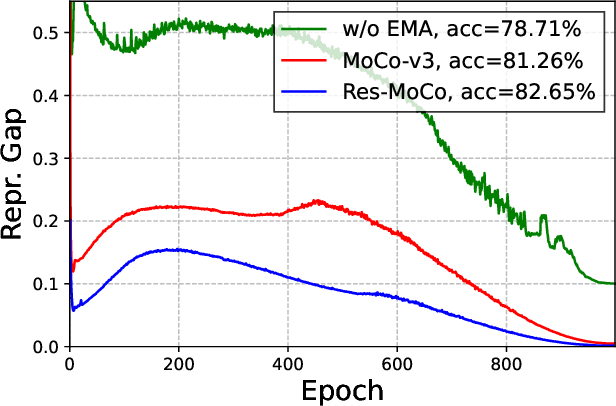
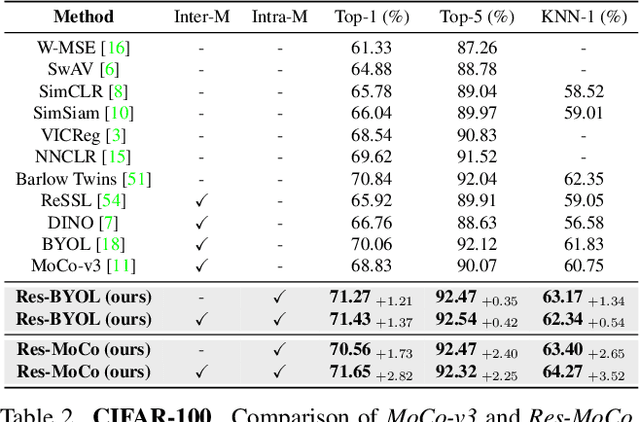
Self-supervised learning (SSL) approaches have shown promising capabilities in learning the representation from unlabeled data. Amongst them, momentum-based frameworks have attracted significant attention. Despite being a great success, these momentum-based SSL frameworks suffer from a large gap in representation between the online encoder (student) and the momentum encoder (teacher), which hinders performance on downstream tasks. This paper is the first to investigate and identify this invisible gap as a bottleneck that has been overlooked in the existing SSL frameworks, potentially preventing the models from learning good representation. To solve this problem, we propose "residual momentum" to directly reduce this gap to encourage the student to learn the representation as close to that of the teacher as possible, narrow the performance gap with the teacher, and significantly improve the existing SSL. Our method is straightforward, easy to implement, and can be easily plugged into other SSL frameworks. Extensive experimental results on numerous benchmark datasets and diverse network architectures have demonstrated the effectiveness of our method over the state-of-the-art contrastive learning baselines.
LAD: A Hybrid Deep Learning System for Benign Paroxysmal Positional Vertigo Disorders Diagnostic
Oct 15, 2022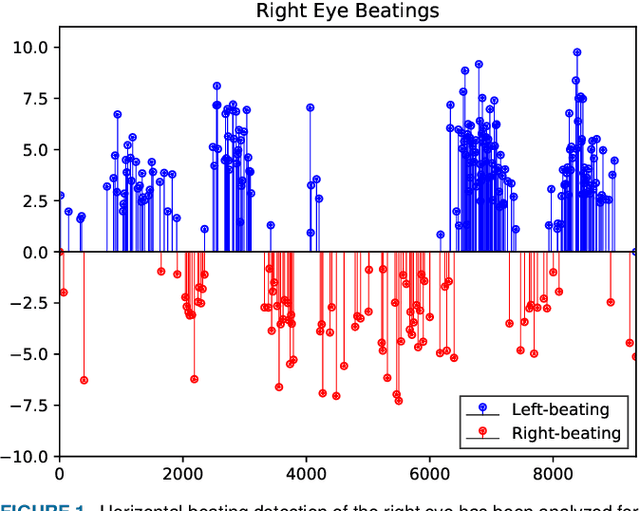
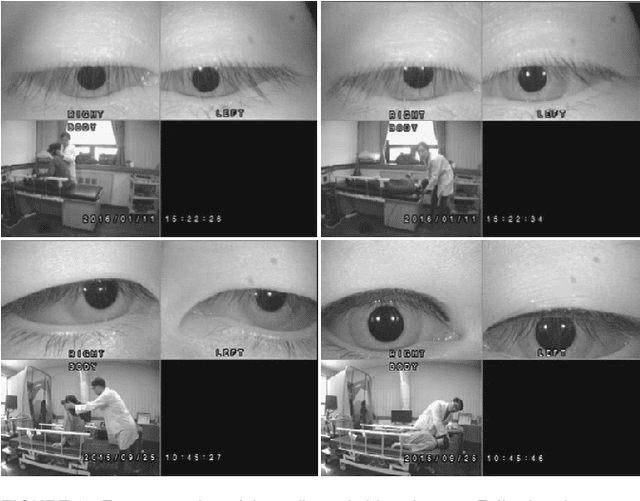
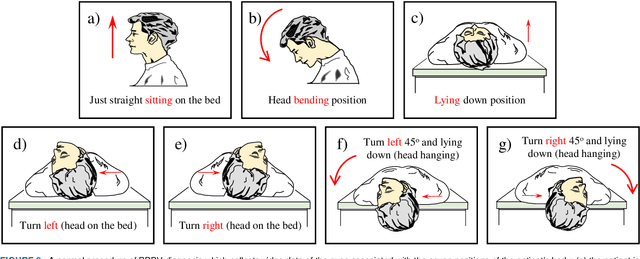

Herein, we introduce "Look and Diagnose" (LAD), a hybrid deep learning-based system that aims to support doctors in the medical field in diagnosing effectively the Benign Paroxysmal Positional Vertigo (BPPV) disorder. Given the body postures of the patient in the Dix-Hallpike and lateral head turns test, the visual information of both eyes is captured and fed into LAD for analyzing and classifying into one of six possible disorders the patient might be suffering from. The proposed system consists of two streams: (1) an RNN-based stream that takes raw RGB images of both eyes to extract visual features and optical flow of each eye followed by ternary classification to determine left/right posterior canal (PC) or other; and (2) pupil detector stream that detects the pupil when it is classified as Non-PC and classifies the direction and strength of the beating to categorize the Non-PC types into the remaining four classes: Geotropic BPPV (left and right) and Apogeotropic BPPV (left and right). Experimental results show that with the patient's body postures, the system can accurately classify given BPPV disorder into the six types of disorders with an accuracy of 91% on the validation set. The proposed method can successfully classify disorders with an accuracy of 93% for the Posterior Canal disorder and 95% for the Geotropic and Apogeotropic disorder, paving a potential direction for research with the medical data.