 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-MD3C: Taming Masked Diffusion Transformers for Efficient Zero-Shot Object Customization
Feb 13, 2025We propose E-MD3C ($\underline{E}$fficient $\underline{M}$asked $\underline{D}$iffusion Transformer with Disentangled $\underline{C}$onditions and $\underline{C}$ompact $\underline{C}$ollector), a highly efficient framework for zero-shot object image customization. Unlike prior works reliant on resource-intensive Unet architectures, our approach employs lightweight masked diffusion transformers operating on latent patches, offering significantly improved computational efficiency. The framework integrates three core components: (1) an efficient masked diffusion transformer for processing autoencoder latents, (2) a disentangled condition design that ensures compactness while preserving background alignment and fine details, and (3) a learnable Conditions Collector that consolidates multiple inputs into a compact representation for efficient denoising and learning. E-MD3C outperforms the existing approach on the VITON-HD dataset across metrics such as PSNR, FID, SSIM, and LPIPS, demonstrating clear advantages in parameters, memory efficiency, and inference speed. With only $\frac{1}{4}$ of the parameters, our Transformer-based 468M model delivers $2.5\times$ faster inference and uses $\frac{2}{3}$ of the GPU memory compared to an 1720M Unet-based latent diffusion model.
Cross-view Masked Diffusion Transformers for Person Image Synthesis
Feb 02, 2024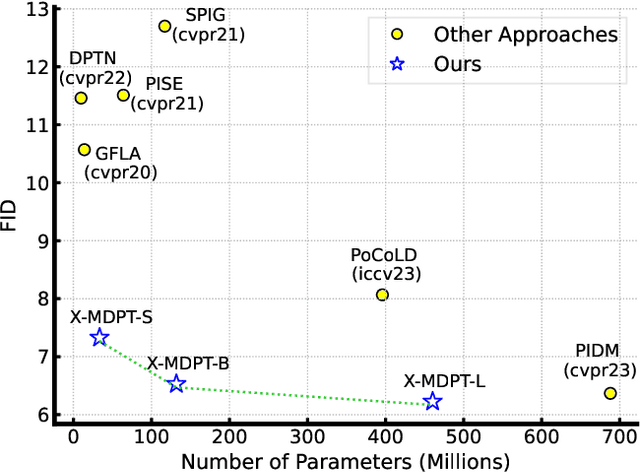


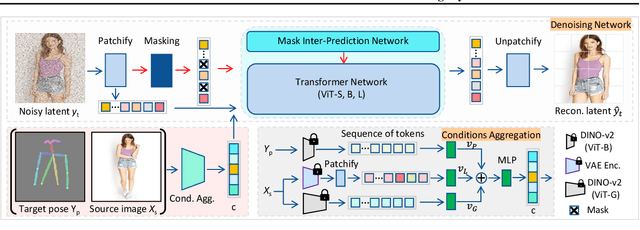
We present X-MDPT (Cross-view Masked Diffusion Prediction Transformers), a novel diffusion model designed for pose-guided human image generation. X-MDPT distinguishes itself by employing masked diffusion transformers that operate on latent patches, a departure from the commonly-used Unet structures in existing works. The model comprises three key modules: 1) a denoising diffusion Transformer, 2) an aggregation network that consolidates conditions into a single vector for the diffusion process, and 3) a mask cross-prediction module that enhances representation learning with semantic information from the reference image. X-MDPT demonstrates scalability, improving FID, SSIM, and LPIPS with larger models. Despite its simple design, our model outperforms state-of-the-art approaches on the DeepFashion dataset while exhibiting efficiency in terms of training parameters, training time, and inference speed. Our compact 33MB model achieves an FID of 7.42, surpassing a prior Unet latent diffusion approach (FID 8.07) using only $11\times$ fewer parameters. Our best model surpasses the pixel-based diffusion with $\frac{2}{3}$ of the parameters and achieves $5.43 \times$ faster inference.
Self-Supervised Visual Representation Learning via Residual Momentum
Nov 21, 2022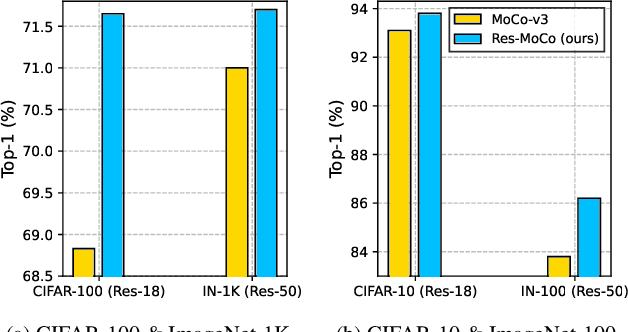
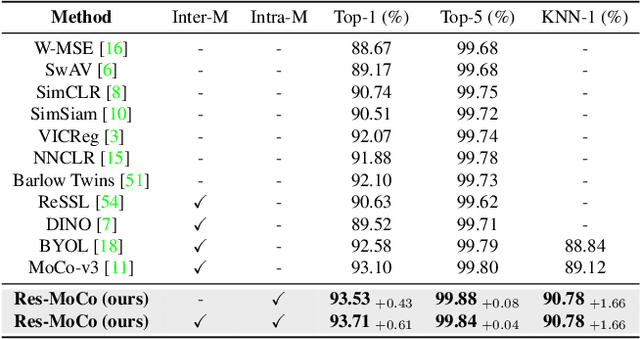
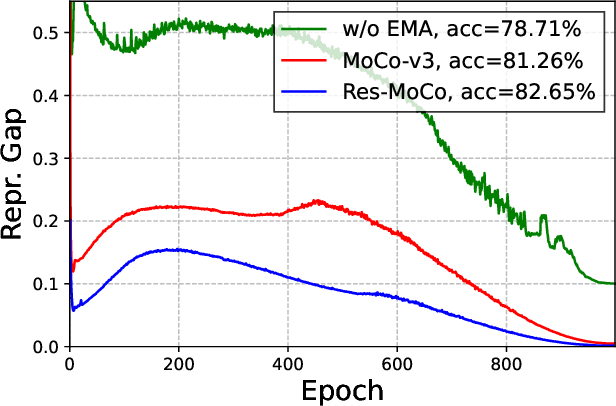
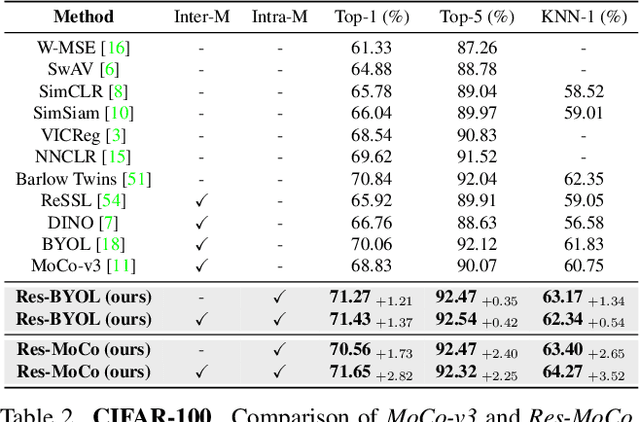
Self-supervised learning (SSL) approaches have shown promising capabilities in learning the representation from unlabeled data. Amongst them, momentum-based frameworks have attracted significant attention. Despite being a great success, these momentum-based SSL frameworks suffer from a large gap in representation between the online encoder (student) and the momentum encoder (teacher), which hinders performance on downstream tasks. This paper is the first to investigate and identify this invisible gap as a bottleneck that has been overlooked in the existing SSL frameworks, potentially preventing the models from learning good representation. To solve this problem, we propose "residual momentum" to directly reduce this gap to encourage the student to learn the representation as close to that of the teacher as possible, narrow the performance gap with the teacher, and significantly improve the existing SSL. Our method is straightforward, easy to implement, and can be easily plugged into other SSL frameworks. Extensive experimental results on numerous benchmark datasets and diverse network architectures have demonstrated the effectiveness of our method over the state-of-the-art contrastive learning baselines.