 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulcan: Instance-Optimal Systems Heuristics Through LLM-Driven Search
Dec 31, 2025Resource-management tasks in modern operating and distributed systems continue to rely primarily on hand-designed heuristics for tasks such as scheduling, caching, or active queue management. Designing performant heuristics is an expensive, time-consuming process that we are forced to continuously go through due to the constant flux of hardware, workloads and environments. We propose a new alternative: synthesizing instance-optimal heuristics -- specialized for the exact workloads and hardware where they will be deployed -- using code-generating large language models (LLMs). To make this synthesis tractable, Vulcan separates policy and mechanism through LLM-friendly, task-agnostic interfaces. With these interfaces, users specify the inputs and objectives of their desired policy, while Vulcan searches for performant policies via evolutionary search over LLM-generated code. This interface is expressive enough to capture a wide range of system policies, yet sufficiently constrained to allow even small, inexpensive LLMs to generate correct and executable code. We use Vulcan to synthesize performant heuristics for cache eviction and memory tiering, and find that these heuristics outperform all human-designed state-of-the-art algorithms by upto 69% and 7.9% in performance for each of these tasks respectively.
ConfigBot: Adaptive Resource Allocation for Robot Applications in Dynamic Environments
Jan 17, 2025



The growing use of autonomous mobile service robots (AMSRs) in dynamic environments requires flexible management of compute resources to optimize the performance of diverse tasks such as navigation, localization, perception, and so on. Current robot deployments, which oftentimes rely on static configurations (of the OS, applications, etc.) and system over-provisioning, fall short since they do not account for the tasks' performance variations resulting in poor system-wide behavior such as robot instability and/or inefficient resource use. This paper presents ConfigBot, a system designed to adaptively reconfigure AMSR applications to meet a predefined performance specification by leveraging runtime profiling and automated configuration tuning. Through experiments on a Boston Dynamics Spot robot equipped with NVIDIA AGX Orin, we demonstrate ConfigBot's efficacy in maintaining system stability and optimizing resource allocation across diverse scenarios. Our findings highlight the promise of tailored and dynamic configurations for robot deployments.
OMEGA: A Low-Latency GNN Serving System for Large Graphs
Jan 15, 2025



Graph Neural Networks (GNNs) have been widely adopted for their ability to compute expressive node representations in graph datasets. However, serving GNNs on large graphs is challenging due to the high communication, computation, and memory overheads of constructing and executing computation graphs, which represent information flow across large neighborhoods. Existing approximation techniques in training can mitigate the overheads but, in serving, still lead to high latency and/or accuracy loss. To this end, we propose OMEGA, a system that enables low-latency GNN serving for large graphs with minimal accuracy loss through two key ideas. First, OMEGA employs selective recomputation of precomputed embeddings, which allows for reusing precomputed computation subgraphs while selectively recomputing a small fraction to minimize accuracy loss. Second, we develop computation graph parallelism, which reduces communication overhead by parallelizing the creation and execution of computation graphs across machines. Our evaluation with large graph datasets and GNN models shows that OMEGA significantly outperforms state-of-the-art techniques.
Accelerating Distributed Deep Learning using Lossless Homomorphic Compression
Feb 12, 2024



As deep neural networks (DNNs) grow in complexity and size, the resultant increase in communication overhead during distributed training has become a significant bottleneck, challenging the scalability of distributed training systems. Existing solutions, while aiming to mitigate this bottleneck through worker-level compression and in-network aggregation, fall short due to their inability to efficiently reconcile the trade-offs between compression effectiveness and computational overhead, hindering overall performance and scalability. In this paper, we introduce a novel compression algorithm that effectively merges worker-level compression with in-network aggregation. Our solution is both homomorphic, allowing for efficient in-network aggregation without CPU/GPU processing, and lossless, ensuring no compromise on training accuracy. Theoretically optimal in compression and computational efficiency, our approach is empirically validated across diverse DNN models such as NCF, LSTM, VGG19, and BERT-base, showing up to a 6.33$\times$ improvement in aggregation throughput and a 3.74$\times$ increase in per-iteration training speed.
On a Foundation Model for Operating Systems
Dec 13, 2023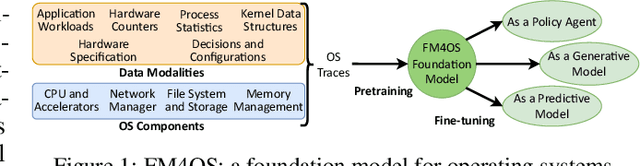
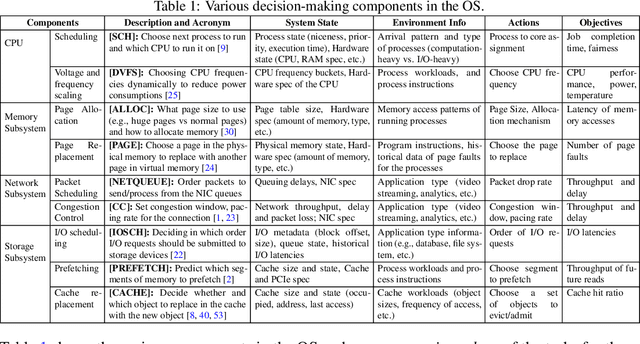
This paper lays down the research agenda for a domain-specific foundation model for operating systems (OSes). Our case for a foundation model revolves around the observations that several OS components such as CPU, memory, and network subsystems are interrelated and that OS traces offer the ideal dataset for a foundation model to grasp the intricacies of diverse OS components and their behavior in varying environments and workloads. We discuss a wide range of possibilities that then arise, from employing foundation models as policy agents to utilizing them as generators and predictors to assist traditional OS control algorithms. Our hope is that this paper spurs further research into OS foundation models and creating the next generation of operating systems for the evolving computing landscape.
Mitigating the Exposure Bias in Sentence-Level Grapheme-to-Phoneme (G2P) Transduction
Aug 16, 2023



Text-to-Text Transfer Transformer (T5) has recently been considered for the Grapheme-to-Phoneme (G2P) transduction. As a follow-up, a tokenizer-free byte-level model based on T5 referred to as ByT5, recently gave promising results on word-level G2P conversion by representing each input character with its corresponding UTF-8 encoding. Although it is generally understood that sentence-level or paragraph-level G2P can improve usability in real-world applications as it is better suited to perform on heteronyms and linking sounds between words, we find that using ByT5 for these scenarios is nontrivial. Since ByT5 operates on the character level, it requires longer decoding steps, which deteriorates the performance due to the exposure bias commonly observed in auto-regressive generation models. This paper shows that the performance of sentence-level and paragraph-level G2P can be improved by mitigating such exposure bias using our proposed loss-based sampling method.
Self-Supervised Visual Representation Learning via Residual Momentum
Nov 21, 2022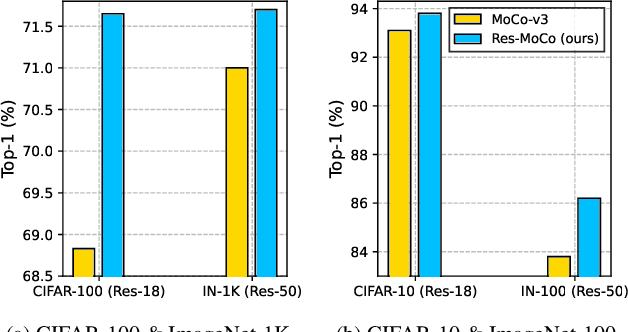
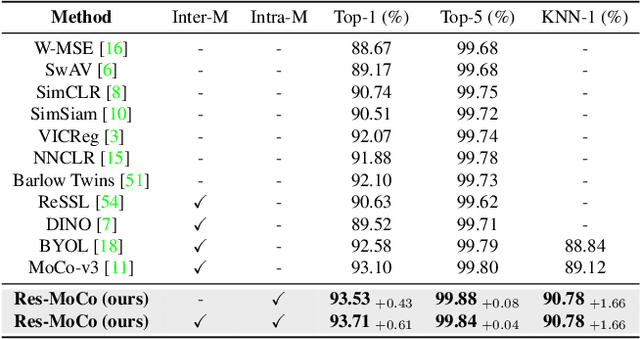
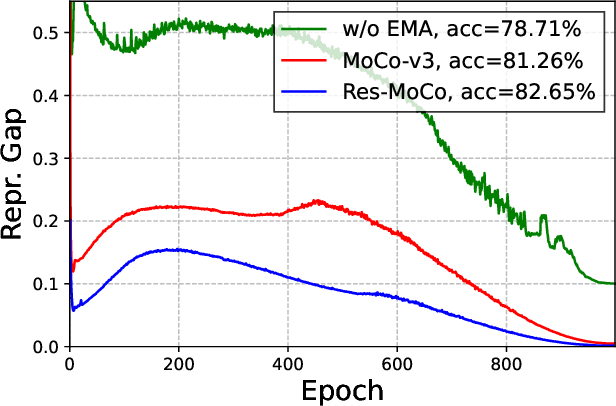
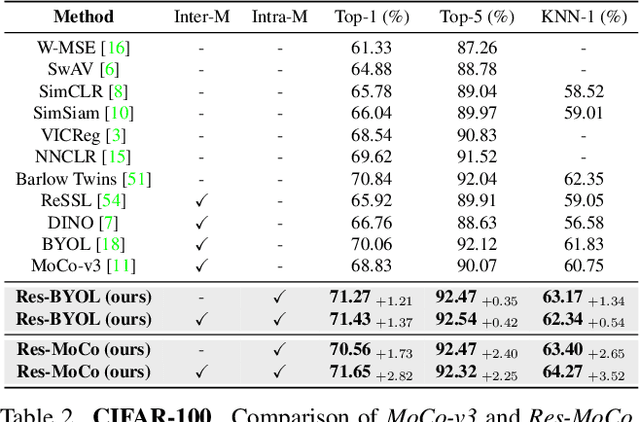
Self-supervised learning (SSL) approaches have shown promising capabilities in learning the representation from unlabeled data. Amongst them, momentum-based frameworks have attracted significant attention. Despite being a great success, these momentum-based SSL frameworks suffer from a large gap in representation between the online encoder (student) and the momentum encoder (teacher), which hinders performance on downstream tasks. This paper is the first to investigate and identify this invisible gap as a bottleneck that has been overlooked in the existing SSL frameworks, potentially preventing the models from learning good representation. To solve this problem, we propose "residual momentum" to directly reduce this gap to encourage the student to learn the representation as close to that of the teacher as possible, narrow the performance gap with the teacher, and significantly improve the existing SSL. Our method is straightforward, easy to implement, and can be easily plugged into other SSL frameworks. Extensive experimental results on numerous benchmark datasets and diverse network architectures have demonstrated the effectiveness of our method over the state-of-the-art contrastive learning baselines.