 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed Distillation for Diffusion Models
Nov 13, 2024



Diffusion models have recently emerged as a potent tool in generative modeling. However, their inherent iterative nature often results in sluggish image generation due to the requirement for multiple model evaluations. Recent progress has unveiled the intrinsic link between diffusion models and Probability Flow Ordinary Differential Equations (ODEs), thus enabling us to conceptualize diffusion models as ODE systems. Simultaneously, Physics Informed Neural Networks (PINNs) have substantiated their effectiveness in solving intricate differential equations through implicit modeling of their solutions. Building upon these foundational insights, we introduce Physics Informed Distillation (PID), which employs a student model to represent the solution of the ODE system corresponding to the teacher diffusion model, akin to the principles employed in PINNs. Through experiments on CIFAR 10 and ImageNet 64x64, we observe that PID achieves performance comparable to recent distillation methods. Notably, it demonstrates predictable trends concerning method-specific hyperparameters and eliminates the need for synthetic dataset generation during the distillation process. Both of which contribute to its easy-to-use nature as a distillation approach for Diffusion Models. Our code and pre-trained checkpoint are publicly available at: https://github.com/pantheon5100/pid_diffusion.git.
BI-MDRG: Bridging Image History in Multimodal Dialogue Response Generation
Aug 12, 2024
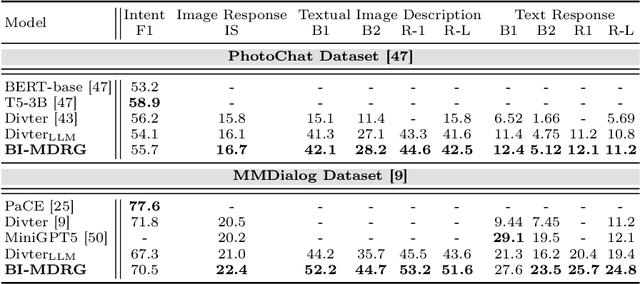


Multimodal Dialogue Response Generation (MDRG) is a recently proposed task where the model needs to generate responses in texts, images, or a blend of both based on the dialogue context. Due to the lack of a large-scale dataset specifically for this task and the benefits of leveraging powerful pre-trained models, previous work relies on the text modality as an intermediary step for both the image input and output of the model rather than adopting an end-to-end approach. However, this approach can overlook crucial information about the image, hindering 1) image-grounded text response and 2) consistency of objects in the image response. In this paper, we propose BI-MDRG that bridges the response generation path such that the image history information is utilized for enhanced relevance of text responses to the image content and the consistency of objects in sequential image responses. Through extensive experiments on the multimodal dialogue benchmark dataset, we show that BI-MDRG can effectively increase the quality of multimodal dialogue. Additionally, recognizing the gap in benchmark datasets for evaluating the image consistency in multimodal dialogue, we have created a curated set of 300 dialogues annotated to track object consistency across conversations.
C-TPT: Calibrated Test-Time Prompt Tuning for Vision-Language Models via Text Feature Dispersion
Mar 31, 2024


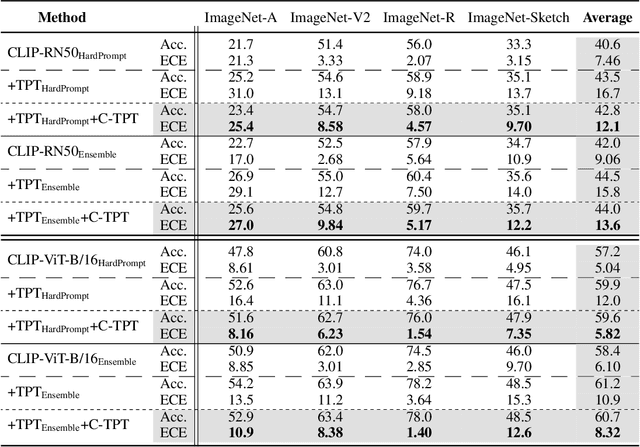
In deep learning, test-time adaptation has gained attention as a method for model fine-tuning without the need for labeled data. A prime exemplification is the recently proposed test-time prompt tuning for large-scale vision-language models such as CLIP. Unfortunately, these prompts have been mainly developed to improve accuracy, overlooking the importance of calibration, which is a crucial aspect for quantifying prediction uncertainty. However, traditional calibration methods rely on substantial amounts of labeled data, making them impractical for test-time scenarios. To this end, this paper explores calibration during test-time prompt tuning by leveraging the inherent properties of CLIP. Through a series of observations, we find that the prompt choice significantly affects the calibration in CLIP, where the prompts leading to higher text feature dispersion result in better-calibrated predictions. Introducing the Average Text Feature Dispersion (ATFD), we establish its relationship with calibration error and present a novel method, Calibrated Test-time Prompt Tuning (C-TPT), for optimizing prompts during test-time with enhanced calibration. Through extensive experiments on different CLIP architectures and datasets, we show that C-TPT can effectively improve the calibration of test-time prompt tuning without needing labeled data. The code is publicly accessible at https://github.com/hee-suk-yoon/C-TPT.
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023



It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure
Mar 04, 2023



Studies have shown that modern neural networks tend to be poorly calibrated due to over-confident predictions. Traditionally, post-processing methods have been used to calibrate the model after training. In recent years, various trainable calibration measures have been proposed to incorporate them directly into the training process. However, these methods all incorporate internal hyperparameters, and the performance of these calibration objectives relies on tuning these hyperparameters, incurring more computational costs as the size of neural networks and datasets become larger. As such, we present Expected Squared Difference (ESD), a tuning-free (i.e., hyperparameter-free) trainable calibration objective loss, where we view the calibration error from the perspective of the squared difference between the two expectations. With extensive experiments on several architectures (CNNs, Transformers) and datasets, we demonstrate that (1) incorporating ESD into the training improves model calibration in various batch size settings without the need for internal hyperparameter tuning, (2) ESD yields the best-calibrated results compared with previous approaches, and (3) ESD drastically improves the computational costs required for calibration during training due to the absence of internal hyperparameter. The code is publicly accessible at https://github.com/hee-suk-yoon/ESD.
Self-Supervised Visual Representation Learning via Residual Momentum
Nov 21, 2022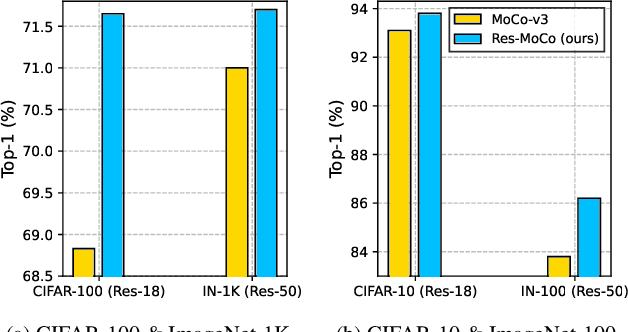
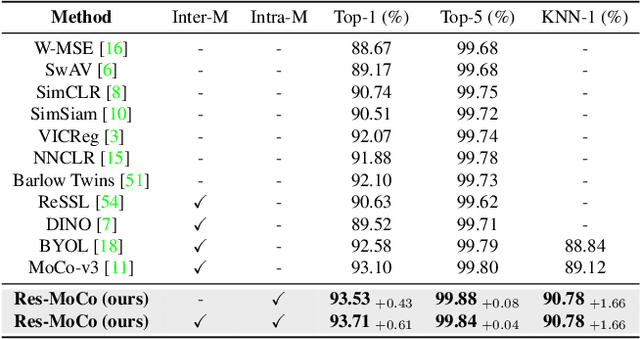
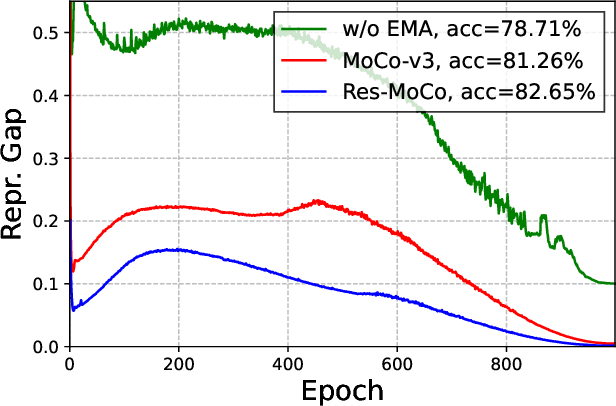
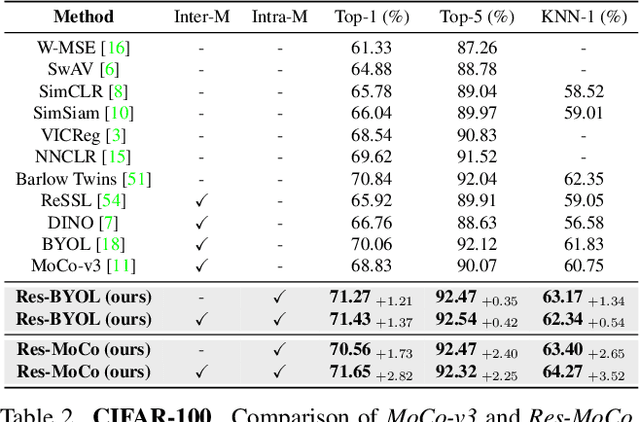
Self-supervised learning (SSL) approaches have shown promising capabilities in learning the representation from unlabeled data. Amongst them, momentum-based frameworks have attracted significant attention. Despite being a great success, these momentum-based SSL frameworks suffer from a large gap in representation between the online encoder (student) and the momentum encoder (teacher), which hinders performance on downstream tasks. This paper is the first to investigate and identify this invisible gap as a bottleneck that has been overlooked in the existing SSL frameworks, potentially preventing the models from learning good representation. To solve this problem, we propose "residual momentum" to directly reduce this gap to encourage the student to learn the representation as close to that of the teacher as possible, narrow the performance gap with the teacher, and significantly improve the existing SSL. Our method is straightforward, easy to implement, and can be easily plugged into other SSL frameworks. Extensive experimental results on numerous benchmark datasets and diverse network architectures have demonstrated the effectiveness of our method over the state-of-the-art contrastive learning baselines.