 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfPO: Exploiting Policy Model Confidence for Critical Token Selection in Preference Optimization
Jun 12, 2025We introduce ConfPO, a method for preference learning in Large Language Models (LLMs) that identifies and optimizes preference-critical tokens based solely on the training policy's confidence, without requiring any auxiliary models or compute. Unlike prior Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO), which uniformly adjust all token probabilities regardless of their relevance to preference, ConfPO focuses optimization on the most impactful tokens. This targeted approach improves alignment quality while mitigating overoptimization (i.e., reward hacking) by using the KL divergence budget more efficiently. In contrast to recent token-level methods that rely on credit-assignment models or AI annotators, raising concerns about scalability and reliability, ConfPO is simple, lightweight, and model-free. Experimental results on challenging alignment benchmarks, including AlpacaEval 2 and Arena-Hard, demonstrate that ConfPO consistently outperforms uniform DAAs across various LLMs, delivering better alignment with zero additional computational overhead.
Physics Informed Distillation for Diffusion Models
Nov 13, 2024



Diffusion models have recently emerged as a potent tool in generative modeling. However, their inherent iterative nature often results in sluggish image generation due to the requirement for multiple model evaluations. Recent progress has unveiled the intrinsic link between diffusion models and Probability Flow Ordinary Differential Equations (ODEs), thus enabling us to conceptualize diffusion models as ODE systems. Simultaneously, Physics Informed Neural Networks (PINNs) have substantiated their effectiveness in solving intricate differential equations through implicit modeling of their solutions. Building upon these foundational insights, we introduce Physics Informed Distillation (PID), which employs a student model to represent the solution of the ODE system corresponding to the teacher diffusion model, akin to the principles employed in PINNs. Through experiments on CIFAR 10 and ImageNet 64x64, we observe that PID achieves performance comparable to recent distillation methods. Notably, it demonstrates predictable trends concerning method-specific hyperparameters and eliminates the need for synthetic dataset generation during the distillation process. Both of which contribute to its easy-to-use nature as a distillation approach for Diffusion Models. Our code and pre-trained checkpoint are publicly available at: https://github.com/pantheon5100/pid_diffusion.git.
BI-MDRG: Bridging Image History in Multimodal Dialogue Response Generation
Aug 12, 2024
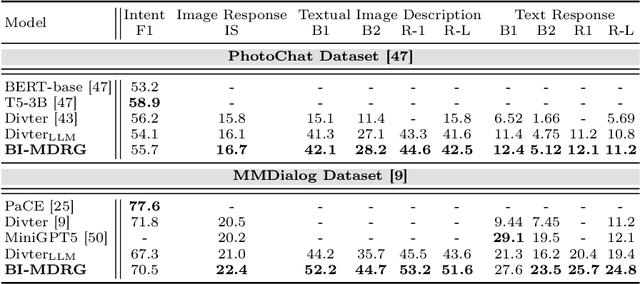


Multimodal Dialogue Response Generation (MDRG) is a recently proposed task where the model needs to generate responses in texts, images, or a blend of both based on the dialogue context. Due to the lack of a large-scale dataset specifically for this task and the benefits of leveraging powerful pre-trained models, previous work relies on the text modality as an intermediary step for both the image input and output of the model rather than adopting an end-to-end approach. However, this approach can overlook crucial information about the image, hindering 1) image-grounded text response and 2) consistency of objects in the image response. In this paper, we propose BI-MDRG that bridges the response generation path such that the image history information is utilized for enhanced relevance of text responses to the image content and the consistency of objects in sequential image responses. Through extensive experiments on the multimodal dialogue benchmark dataset, we show that BI-MDRG can effectively increase the quality of multimodal dialogue. Additionally, recognizing the gap in benchmark datasets for evaluating the image consistency in multimodal dialogue, we have created a curated set of 300 dialogues annotated to track object consistency across conversations.
LI-TTA: Language Informed Test-Time Adaptation for Automatic Speech Recognition
Aug 11, 2024Test-Time Adaptation (TTA) has emerged as a crucial solution to the domain shift challenge, wherein the target environment diverges from the original training environment. A prime exemplification is TTA for Automatic Speech Recognition (ASR), which enhances model performance by leveraging output prediction entropy minimization as a self-supervision signal. However, a key limitation of this self-supervision lies in its primary focus on acoustic features, with minimal attention to the linguistic properties of the input. To address this gap, we propose Language Informed Test-Time Adaptation (LI-TTA), which incorporates linguistic insights during TTA for ASR. LI-TTA integrates corrections from an external language model to merge linguistic with acoustic information by minimizing the CTC loss from the correction alongside the standard TTA loss. With extensive experiments, we show that LI-TTA effectively improves the performance of TTA for ASR in various distribution shift situations.
TLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
C-TPT: Calibrated Test-Time Prompt Tuning for Vision-Language Models via Text Feature Dispersion
Mar 31, 2024


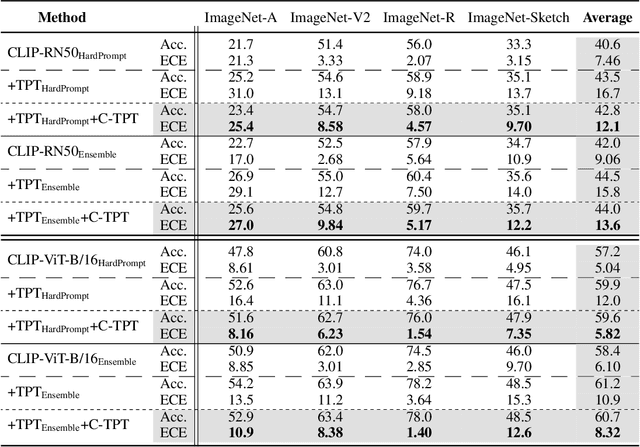
In deep learning, test-time adaptation has gained attention as a method for model fine-tuning without the need for labeled data. A prime exemplification is the recently proposed test-time prompt tuning for large-scale vision-language models such as CLIP. Unfortunately, these prompts have been mainly developed to improve accuracy, overlooking the importance of calibration, which is a crucial aspect for quantifying prediction uncertainty. However, traditional calibration methods rely on substantial amounts of labeled data, making them impractical for test-time scenarios. To this end, this paper explores calibration during test-time prompt tuning by leveraging the inherent properties of CLIP. Through a series of observations, we find that the prompt choice significantly affects the calibration in CLIP, where the prompts leading to higher text feature dispersion result in better-calibrated predictions. Introducing the Average Text Feature Dispersion (ATFD), we establish its relationship with calibration error and present a novel method, Calibrated Test-time Prompt Tuning (C-TPT), for optimizing prompts during test-time with enhanced calibration. Through extensive experiments on different CLIP architectures and datasets, we show that C-TPT can effectively improve the calibration of test-time prompt tuning without needing labeled data. The code is publicly accessible at https://github.com/hee-suk-yoon/C-TPT.
AdaMER-CTC: Connectionist Temporal Classification with Adaptive Maximum Entropy Regularization for Automatic Speech Recognition
Mar 18, 2024



In Automatic Speech Recognition (ASR) systems, a recurring obstacle is the generation of narrowly focused output distributions. This phenomenon emerges as a side effect of Connectionist Temporal Classification (CTC), a robust sequence learning tool that utilizes dynamic programming for sequence mapping. While earlier efforts have tried to combine the CTC loss with an entropy maximization regularization term to mitigate this issue, they employed a constant weighting term on the regularization during the training, which we find may not be optimal. In this work, we introduce Adaptive Maximum Entropy Regularization (AdaMER), a technique that can modulate the impact of entropy regularization throughout the training process. This approach not only refines ASR model training but ensures that as training proceeds, predictions display the desired model confidence.
HEAR: Hearing Enhanced Audio Response for Video-grounded Dialogue
Dec 15, 2023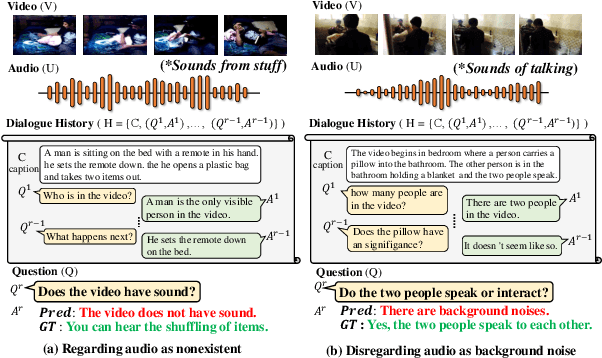
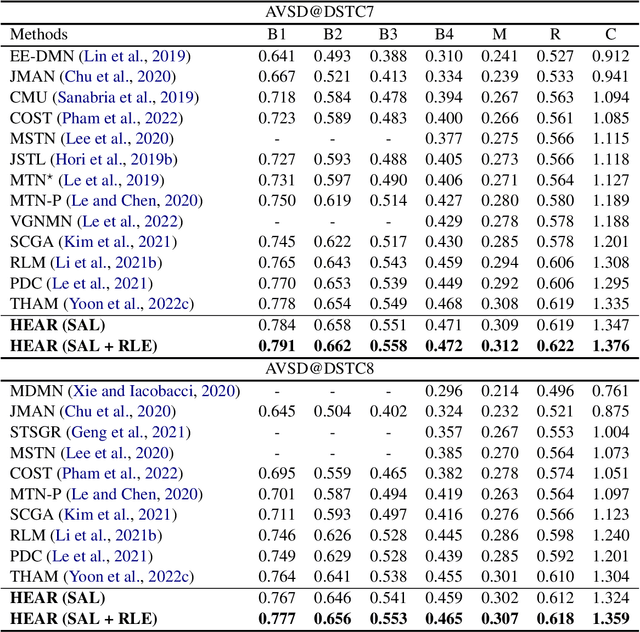
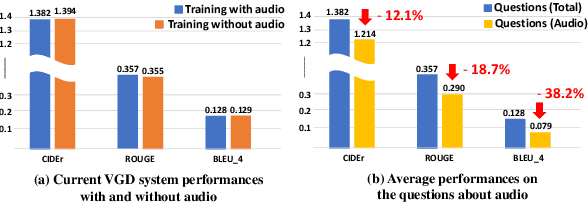

Video-grounded Dialogue (VGD) aims to answer questions regarding a given multi-modal input comprising video, audio, and dialogue history. Although there have been numerous efforts in developing VGD systems to improve the quality of their responses, existing systems are competent only to incorporate the information in the video and text and tend to struggle in extracting the necessary information from the audio when generating appropriate responses to the question. The VGD system seems to be deaf, and thus, we coin this symptom of current systems' ignoring audio data as a deaf response. To overcome the deaf response problem, Hearing Enhanced Audio Response (HEAR) framework is proposed to perform sensible listening by selectively attending to audio whenever the question requires it. The HEAR framework enhances the accuracy and audibility of VGD systems in a model-agnostic manner. HEAR is validated on VGD datasets (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows effectiveness with various VGD systems.
SimPSI: A Simple Strategy to Preserve Spectral Information in Time Series Data Augmentation
Dec 10, 2023

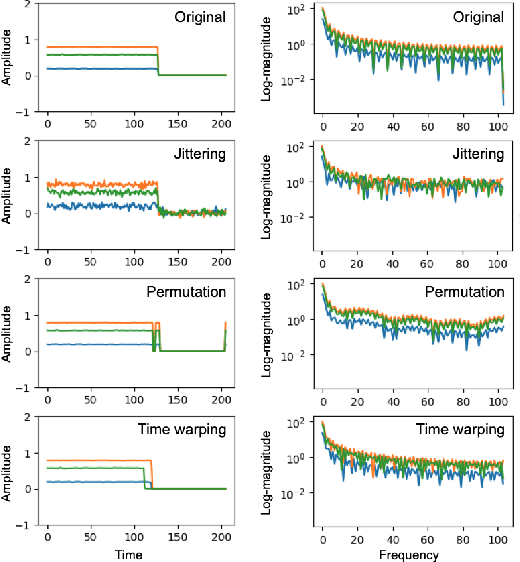

Data augmentation is a crucial component in training neural networks to overcome the limitation imposed by data size, and several techniques have been studied for time series. Although these techniques are effective in certain tasks, they have yet to be generalized to time series benchmarks. We find that current data augmentation techniques ruin the core information contained within the frequency domain. To address this issue, we propose a simple strategy to preserve spectral information (SimPSI) in time series data augmentation. SimPSI preserves the spectral information by mixing the original and augmented input spectrum weighted by a preservation map, which indicates the importance score of each frequency. Specifically, our experimental contributions are to build three distinct preservation maps: magnitude spectrum, saliency map, and spectrum-preservative map. We apply SimPSI to various time series data augmentations and evaluate its effectiveness across a wide range of time series benchmarks. Our experimental results support that SimPSI considerably enhances the performance of time series data augmentations by preserving core spectral information. The source code used in the paper is available at https://github.com/Hyun-Ryu/simpsi.
Mitigating the Exposure Bias in Sentence-Level Grapheme-to-Phoneme (G2P) Transduction
Aug 16, 2023



Text-to-Text Transfer Transformer (T5) has recently been considered for the Grapheme-to-Phoneme (G2P) transduction. As a follow-up, a tokenizer-free byte-level model based on T5 referred to as ByT5, recently gave promising results on word-level G2P conversion by representing each input character with its corresponding UTF-8 encoding. Although it is generally understood that sentence-level or paragraph-level G2P can improve usability in real-world applications as it is better suited to perform on heteronyms and linking sounds between words, we find that using ByT5 for these scenarios is nontrivial. Since ByT5 operates on the character level, it requires longer decoding steps, which deteriorates the performance due to the exposure bias commonly observed in auto-regressive generation models. This paper shows that the performance of sentence-level and paragraph-level G2P can be improved by mitigating such exposure bias using our proposed loss-based sampling method.