 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBI-MDRG: Bridging Image History in Multimodal Dialogue Response Generation
Aug 12, 2024
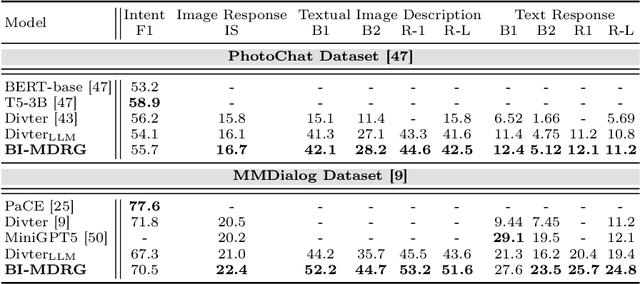


Multimodal Dialogue Response Generation (MDRG) is a recently proposed task where the model needs to generate responses in texts, images, or a blend of both based on the dialogue context. Due to the lack of a large-scale dataset specifically for this task and the benefits of leveraging powerful pre-trained models, previous work relies on the text modality as an intermediary step for both the image input and output of the model rather than adopting an end-to-end approach. However, this approach can overlook crucial information about the image, hindering 1) image-grounded text response and 2) consistency of objects in the image response. In this paper, we propose BI-MDRG that bridges the response generation path such that the image history information is utilized for enhanced relevance of text responses to the image content and the consistency of objects in sequential image responses. Through extensive experiments on the multimodal dialogue benchmark dataset, we show that BI-MDRG can effectively increase the quality of multimodal dialogue. Additionally, recognizing the gap in benchmark datasets for evaluating the image consistency in multimodal dialogue, we have created a curated set of 300 dialogues annotated to track object consistency across conversations.
Evaluating Visual and Cultural Interpretation: The K-Viscuit Benchmark with Human-VLM Collaboration
Jun 24, 2024To create culturally inclusive vision-language models (VLMs), the foremost requirement is developing a test benchmark that can diagnose the models' ability to respond to questions reflecting cultural elements. This paper addresses the necessity for such benchmarks, noting that existing research has relied on human annotators' manual efforts, which impedes diversity and efficiency. We propose a semi-automated pipeline for constructing cultural VLM benchmarks to enhance diversity and efficiency. This pipeline leverages human-VLM collaboration, where VLMs generate questions based on guidelines, human-annotated examples, and image-wise relevant knowledge, which are then reviewed by native speakers for quality and cultural relevance. The effectiveness of our adaptable pipeline is demonstrated through a specific application: creating a dataset tailored to Korean culture, dubbed K-Viscuit. The resulting benchmark features two types of questions: Type 1 questions measure visual recognition abilities, while Type 2 assess fine-grained visual reasoning skills. This ensures a thorough diagnosis of VLM models across various aspects. Our evaluation using K-Viscuit revealed that open-source models notably lag behind proprietary models in understanding Korean culture, highlighting areas for improvement. We provided diverse analyses of VLM performance across different cultural aspects. Besides, we explored the potential of incorporating external knowledge retrieval to enhance the generation process, suggesting future directions for improving cultural interpretation ability of VLMs. Our dataset and code will be made publicly available.
Solution for SMART-101 Challenge of CVPR Multi-modal Algorithmic Reasoning Task 2024
Jun 10, 2024



In this paper, the solution of HYU MLLAB KT Team to the Multimodal Algorithmic Reasoning Task: SMART-101 CVPR 2024 Challenge is presented. Beyond conventional visual question-answering problems, the SMART-101 challenge aims to achieve human-level multimodal understanding by tackling complex visio-linguistic puzzles designed for children in the 6-8 age group. To solve this problem, we suggest two main ideas. First, to utilize the reasoning ability of a large-scale language model (LLM), the given visual cues (images) are grounded in the text modality. For this purpose, we generate highly detailed text captions that describe the context of the image and use these captions as input for the LLM. Second, due to the nature of puzzle images, which often contain various geometric visual patterns, we utilize an object detection algorithm to ensure these patterns are not overlooked in the captioning process. We employed the SAM algorithm, which can detect various-size objects, to capture the visual features of these geometric patterns and used this information as input for the LLM. Under the puzzle split configuration, we achieved an option selection accuracy Oacc of 29.5 on the test set and a weighted option selection accuracy (WOSA) of 27.1 on the challenge set.
Translation Deserves Better: Analyzing Translation Artifacts in Cross-lingual Visual Question Answering
Jun 04, 2024
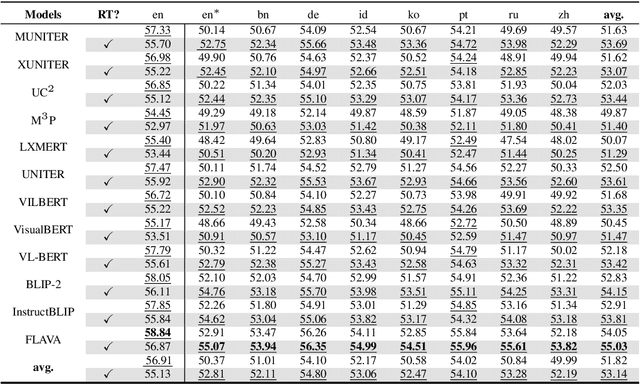


Building a reliable visual question answering~(VQA) system across different languages is a challenging problem, primarily due to the lack of abundant samples for training. To address this challenge, recent studies have employed machine translation systems for the cross-lingual VQA task. This involves translating the evaluation samples into a source language (usually English) and using monolingual models (i.e., translate-test). However, our analysis reveals that translated texts contain unique characteristics distinct from human-written ones, referred to as translation artifacts. We find that these artifacts can significantly affect the models, confirmed by extensive experiments across diverse models, languages, and translation processes. In light of this, we present a simple data augmentation strategy that can alleviate the adverse impacts of translation artifacts.
SGRAM: Improving Scene Graph Parsing via Abstract Meaning Representation
Oct 17, 2022

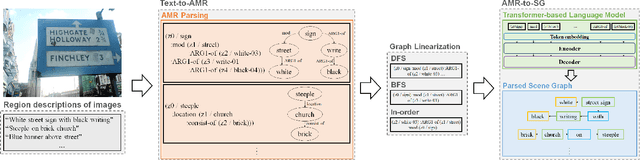
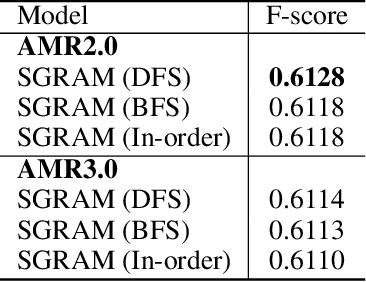
Scene graph is structured semantic representation that can be modeled as a form of graph from images and texts. Image-based scene graph generation research has been actively conducted until recently, whereas text-based scene graph generation research has not. In this paper, we focus on the problem of scene graph parsing from textual description of a visual scene. The core idea is to use abstract meaning representation (AMR) instead of the dependency parsing mainly used in previous studies. AMR is a graph-based semantic formalism of natural language which abstracts concepts of words in a sentence contrary to the dependency parsing which considers dependency relationships on all words in a sentence. To this end, we design a simple yet effective two-stage scene graph parsing framework utilizing abstract meaning representation, SGRAM (Scene GRaph parsing via Abstract Meaning representation): 1) transforming a textual description of an image into an AMR graph (Text-to-AMR) and 2) encoding the AMR graph into a Transformer-based language model to generate a scene graph (AMR-to-SG). Experimental results show the scene graphs generated by our framework outperforms the dependency parsing-based model by 11.61\% and the previous state-of-the-art model using a pre-trained Transformer language model by 3.78\%. Furthermore, we apply SGRAM to image retrieval task which is one of downstream tasks for scene graph, and confirm the effectiveness of scene graphs generated by our framework.
Hypergraph Transformer: Weakly-supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering
Apr 22, 2022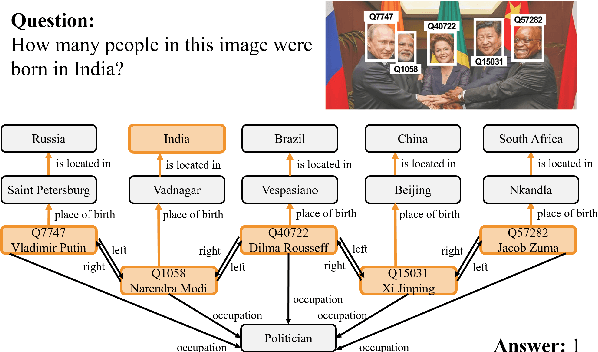
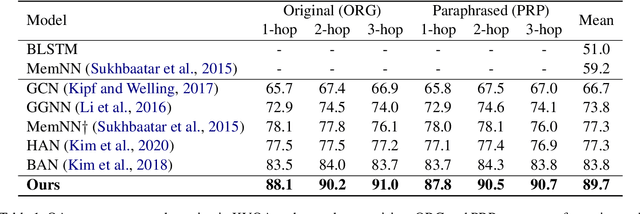
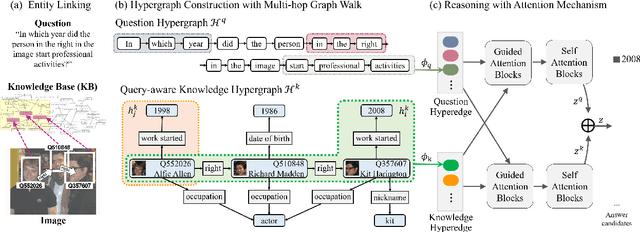
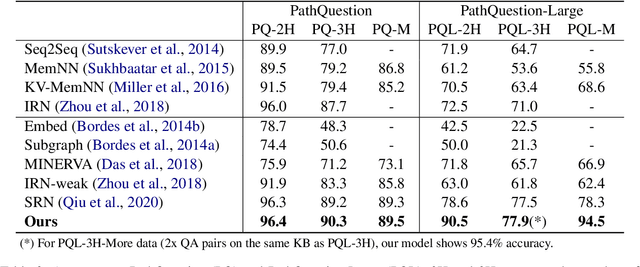
Knowledge-based visual question answering (QA) aims to answer a question which requires visually-grounded external knowledge beyond image content itself. Answering complex questions that require multi-hop reasoning under weak supervision is considered as a challenging problem since i) no supervision is given to the reasoning process and ii) high-order semantics of multi-hop knowledge facts need to be captured. In this paper, we introduce a concept of hypergraph to encode high-level semantics of a question and a knowledge base, and to learn high-order associations between them. The proposed model, Hypergraph Transformer, constructs a question hypergraph and a query-aware knowledge hypergraph, and infers an answer by encoding inter-associations between two hypergraphs and intra-associations in both hypergraph itself. Extensive experiments on two knowledge-based visual QA and two knowledge-based textual QA demonstrate the effectiveness of our method, especially for multi-hop reasoning problem. Our source code is available at https://github.com/yujungheo/kbvqa-public.
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021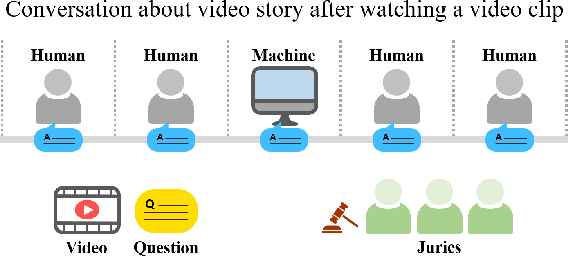

We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.
CogME: A Novel Evaluation Metric for Video Understanding Intelligence
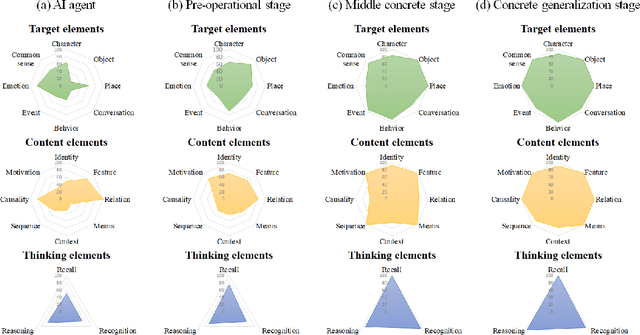
Jul 21, 2021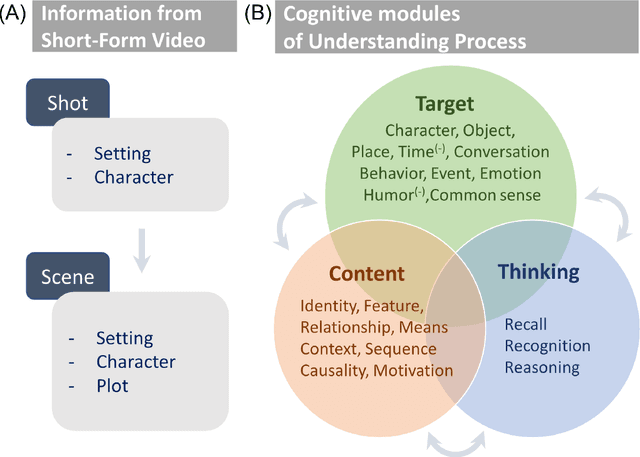
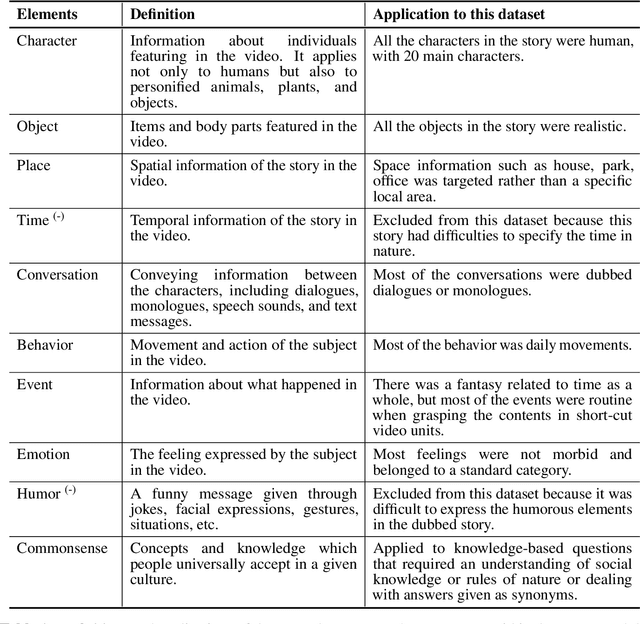
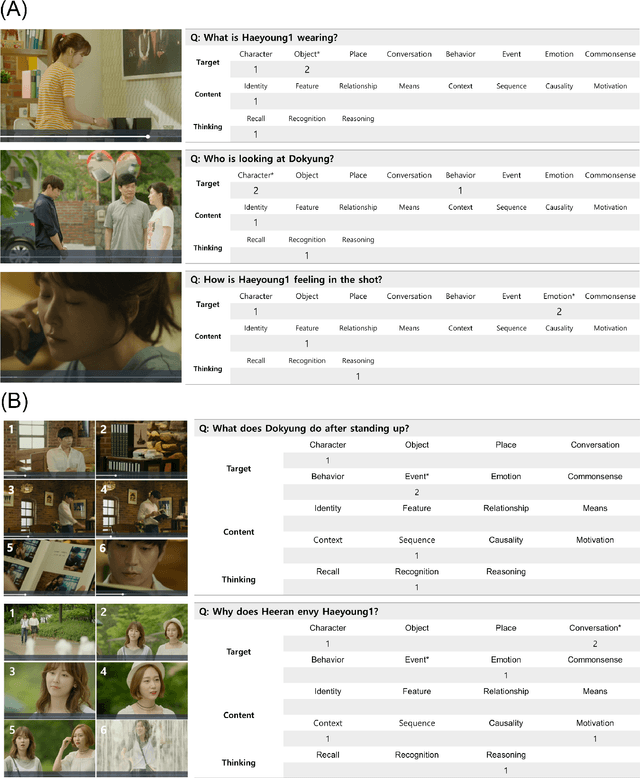
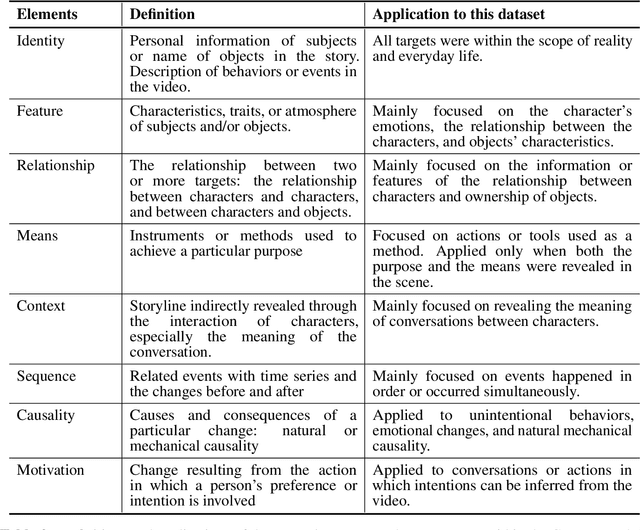
Developing video understanding intelligence is quite challenging because it requires holistic integration of images, scripts, and sounds based on natural language processing, temporal dependency, and reasoning. Recently, substantial attempts have been made on several video datasets with associated question answering (QA) on a large scale. However, existing evaluation metrics for video question answering (VideoQA) do not provide meaningful analysis. To make progress, we argue that a well-made framework, established on the way humans understand, is required to explain and evaluate the performance of understanding in detail. Then we propose a top-down evaluation system for VideoQA, based on the cognitive process of humans and story elements: Cognitive Modules for Evaluation (CogME). CogME is composed of three cognitive modules: targets, contents, and thinking. The interaction among the modules in the understanding procedure can be expressed in one sentence as follows: "I understand the CONTENT of the TARGET through a way of THINKING." Each module has sub-components derived from the story elements. We can specify the required aspects of understanding by annotating the sub-components to individual questions. CogME thus provides a framework for an elaborated specification of VideoQA datasets. To examine the suitability of a VideoQA dataset for validating video understanding intelligence, we evaluated the baseline model of the DramaQA dataset by applying CogME. The evaluation reveals that story elements are unevenly reflected in the existing dataset, and the model based on the dataset may cause biased predictions. Although this study has only been able to grasp a narrow range of stories, we expect that it offers the first step in considering the cognitive process of humans on the video understanding intelligence of humans and AI.
DramaQA: Character-Centered Video Story Understanding with Hierarchical QA
May 07, 2020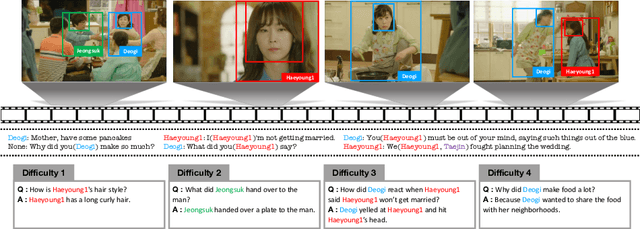
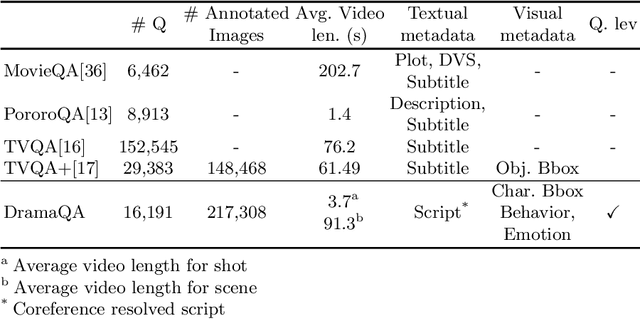
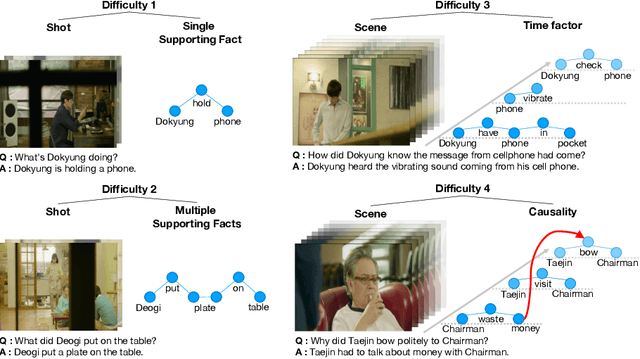
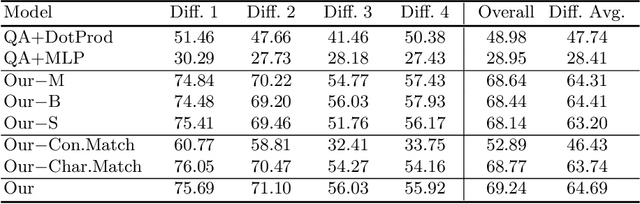
Despite recent progress on computer vision and natural language processing, developing video understanding intelligence is still hard to achieve due to the intrinsic difficulty of story in video. Moreover, there is not a theoretical metric for evaluating the degree of video understanding. In this paper, we propose a novel video question answering (Video QA) task, DramaQA, for a comprehensive understanding of the video story. The DramaQA focused on two perspectives: 1) hierarchical QAs as an evaluation metric based on the cognitive developmental stages of human intelligence. 2) character-centered video annotations to model local coherence of the story. Our dataset is built upon the TV drama "Another Miss Oh" and it contains 16,191 QA pairs from 23,928 various length video clips, with each QA pair belonging to one of four difficulty levels. We provide 217,308 annotated images with rich character-centered annotations, including visual bounding boxes, behaviors, and emotions of main characters, and coreference resolved scripts. Additionally, we provide analyses of the dataset as well as Dual Matching Multistream model which effectively learns character-centered representations of video to answer questions about the video. We are planning to release our dataset and model publicly for research purposes and expect that our work will provide a new perspective on video story understanding research.
Cut-Based Graph Learning Networks to Discover Compositional Structure of Sequential Video Data
Jan 17, 2020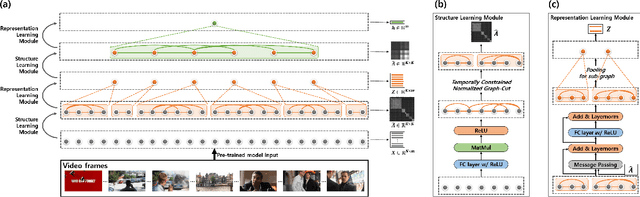
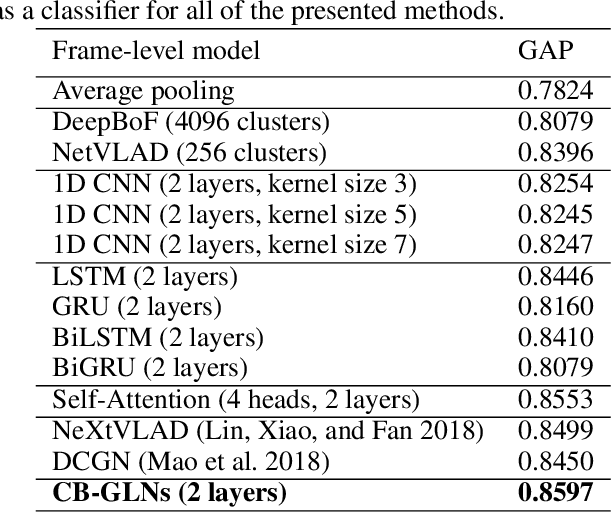


Conventional sequential learning methods such as Recurrent Neural Networks (RNNs) focus on interactions between consecutive inputs, i.e. first-order Markovian dependency. However, most of sequential data, as seen with videos, have complex dependency structures that imply variable-length semantic flows and their compositions, and those are hard to be captured by conventional methods. Here, we propose Cut-Based Graph Learning Networks (CB-GLNs) for learning video data by discovering these complex structures of the video. The CB-GLNs represent video data as a graph, with nodes and edges corresponding to frames of the video and their dependencies respectively. The CB-GLNs find compositional dependencies of the data in multilevel graph forms via a parameterized kernel with graph-cut and a message passing framework. We evaluate the proposed method on the two different tasks for video understanding: Video theme classification (Youtube-8M dataset) and Video Question and Answering (TVQA dataset). The experimental results show that our model efficiently learns the semantic compositional structure of video data. Furthermore, our model achieves the highest performance in comparison to other baseline methods.