 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
PanoGrounder: Bridging 2D and 3D with Panoramic Scene Representations for VLM-based 3D Visual Grounding
Dec 24, 20253D Visual Grounding (3DVG) is a critical bridge from vision-language perception to robotics, requiring both language understanding and 3D scene reasoning. Traditional supervised models leverage explicit 3D geometry but exhibit limited generalization, owing to the scarcity of 3D vision-language datasets and the limited reasoning capabilities compared to modern vision-language models (VLMs). We propose PanoGrounder, a generalizable 3DVG framework that couples multi-modal panoramic representation with pretrained 2D VLMs for strong vision-language reasoning. Panoramic renderings, augmented with 3D semantic and geometric features, serve as an intermediate representation between 2D and 3D, and offer two major benefits: (i) they can be directly fed to VLMs with minimal adaptation and (ii) they retain long-range object-to-object relations thanks to their 360-degree field of view. We devise a three-stage pipeline that places a compact set of panoramic viewpoints considering the scene layout and geometry, grounds a text query on each panoramic rendering with a VLM, and fuses per-view predictions into a single 3D bounding box via lifting. Our approach achieves state-of-the-art results on ScanRefer and Nr3D, and demonstrates superior generalization to unseen 3D datasets and text rephrasings.
Continual Vision-and-Language Navigation
Mar 22, 2024Vision-and-Language Navigation (VLN) agents navigate to a destination using natural language instructions and the visual information they observe. Existing methods for training VLN agents presuppose fixed datasets, leading to a significant limitation: the introduction of new environments necessitates retraining with previously encountered environments to preserve their knowledge. This makes it difficult to train VLN agents that operate in the ever-changing real world. To address this limitation, we present the Continual Vision-and-Language Navigation (CVLN) paradigm, designed to evaluate agents trained through a continual learning process. For the training and evaluation of CVLN agents, we re-arrange existing VLN datasets to propose two datasets: CVLN-I, focused on navigation via initial-instruction interpretation, and CVLN-D, aimed at navigation through dialogue with other agents. Furthermore, we propose two novel rehearsal-based methods for CVLN, Perplexity Replay (PerpR) and Episodic Self-Replay (ESR). PerpR prioritizes replaying challenging episodes based on action perplexity, while ESR replays previously predicted action logits to preserve learned behaviors. We demonstrate the effectiveness of the proposed methods on CVLN through extensive experiments.
Overcoming Weak Visual-Textual Alignment for Video Moment Retrieval
Jun 05, 2023
Video moment retrieval (VMR) aims to identify the specific moment in an untrimmed video for a given natural language query. However, this task is prone to suffer the weak visual-textual alignment problem from query ambiguity, potentially limiting further performance gains and generalization capability. Due to the complex multimodal interactions in videos, a query may not fully cover the relevant details of the corresponding moment, and the moment may contain misaligned and irrelevant frames. To tackle this problem, we propose a straightforward yet effective model, called Background-aware Moment DEtection TRansformer (BM-DETR). Given a target query and its moment, BM-DETR also takes negative queries corresponding to different moments. Specifically, our model learns to predict the target moment from the joint probability of the given query and the complement of negative queries for each candidate frame. In this way, it leverages the surrounding background to consider relative importance, improving moment sensitivity. Extensive experiments on Charades-STA and QVHighlights demonstrate the effectiveness of our model. Moreover, we show that BM-DETR can perform robustly in three challenging VMR scenarios, such as several out-of-distribution test cases, demonstrating superior generalization ability.
Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval
Oct 23, 2022Video corpus moment retrieval (VCMR) is the task to retrieve the most relevant video moment from a large video corpus using a natural language query. For narrative videos, e.g., dramas or movies, the holistic understanding of temporal dynamics and multimodal reasoning is crucial. Previous works have shown promising results; however, they relied on the expensive query annotations for VCMR, i.e., the corresponding moment intervals. To overcome this problem, we propose a self-supervised learning framework: Modal-specific Pseudo Query Generation Network (MPGN). First, MPGN selects candidate temporal moments via subtitle-based moment sampling. Then, it generates pseudo queries exploiting both visual and textual information from the selected temporal moments. Through the multimodal information in the pseudo queries, we show that MPGN successfully learns to localize the video corpus moment without any explicit annotation. We validate the effectiveness of MPGN on the TVR dataset, showing competitive results compared with both supervised models and unsupervised setting models.
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021

We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.
Mounting Video Metadata on Transformer-based Language Model for Open-ended Video Question Answering
Aug 11, 2021

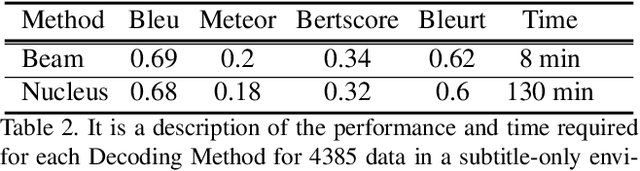
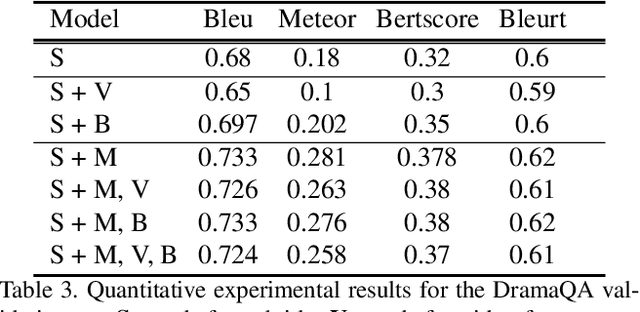
Video question answering has recently received a lot of attention from multimodal video researchers. Most video question answering datasets are usually in the form of multiple-choice. But, the model for the multiple-choice task does not infer the answer. Rather it compares the answer candidates for picking the correct answer. Furthermore, it makes it difficult to extend to other tasks. In this paper, we challenge the existing multiple-choice video question answering by changing it to open-ended video question answering. To tackle open-ended question answering, we use the pretrained GPT2 model. The model is fine-tuned with video inputs and subtitles. An ablation study is performed by changing the existing DramaQA dataset to an open-ended question answering, and it shows that performance can be improved using video metadata.
CogME: A Novel Evaluation Metric for Video Understanding Intelligence
Jul 21, 2021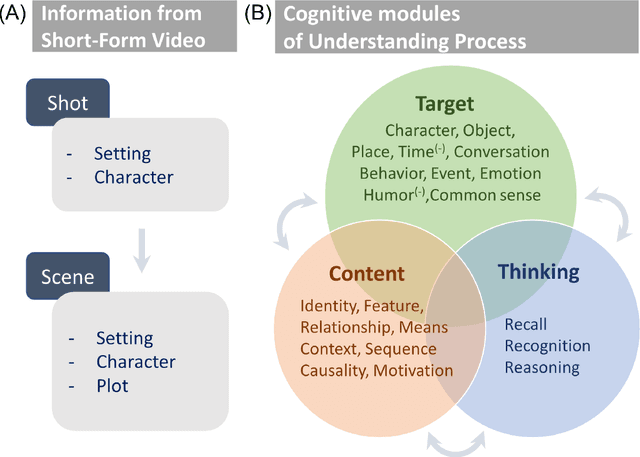
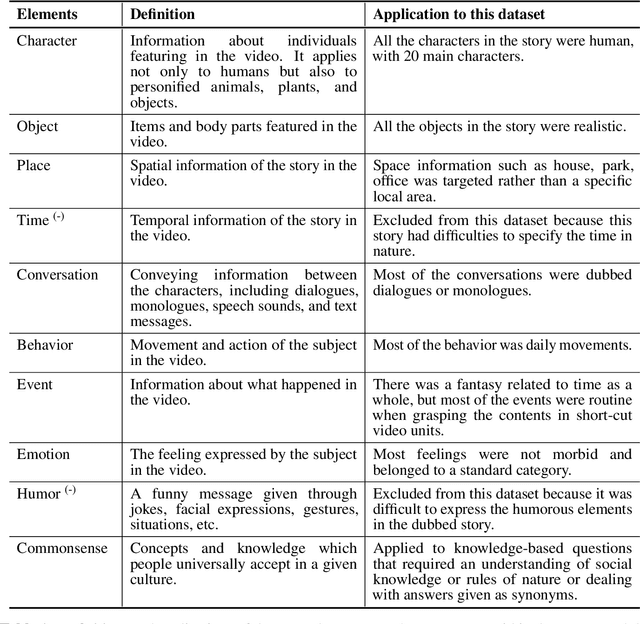
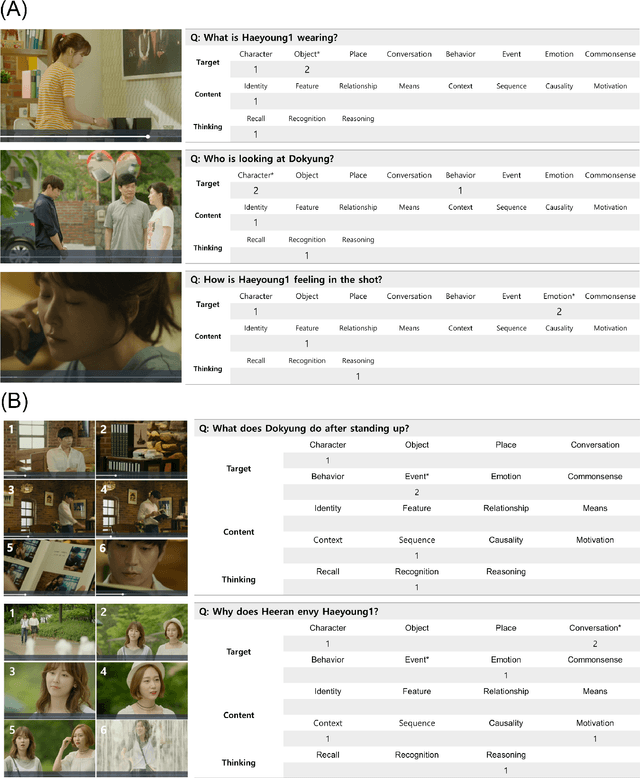
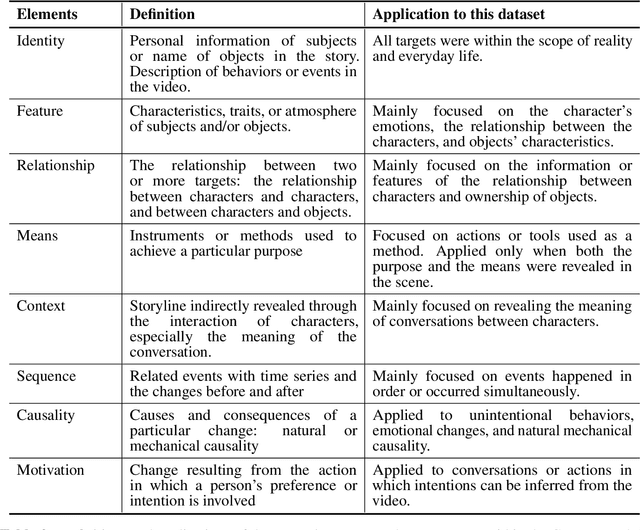
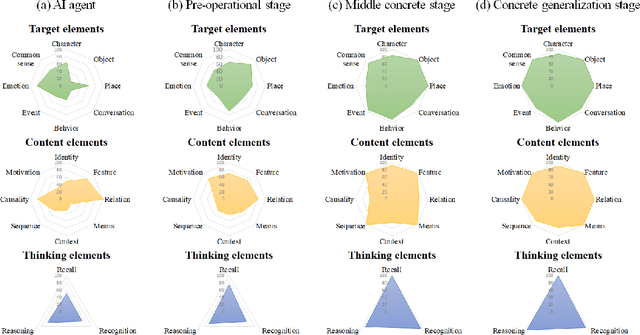
Developing video understanding intelligence is quite challenging because it requires holistic integration of images, scripts, and sounds based on natural language processing, temporal dependency, and reasoning. Recently, substantial attempts have been made on several video datasets with associated question answering (QA) on a large scale. However, existing evaluation metrics for video question answering (VideoQA) do not provide meaningful analysis. To make progress, we argue that a well-made framework, established on the way humans understand, is required to explain and evaluate the performance of understanding in detail. Then we propose a top-down evaluation system for VideoQA, based on the cognitive process of humans and story elements: Cognitive Modules for Evaluation (CogME). CogME is composed of three cognitive modules: targets, contents, and thinking. The interaction among the modules in the understanding procedure can be expressed in one sentence as follows: "I understand the CONTENT of the TARGET through a way of THINKING." Each module has sub-components derived from the story elements. We can specify the required aspects of understanding by annotating the sub-components to individual questions. CogME thus provides a framework for an elaborated specification of VideoQA datasets. To examine the suitability of a VideoQA dataset for validating video understanding intelligence, we evaluated the baseline model of the DramaQA dataset by applying CogME. The evaluation reveals that story elements are unevenly reflected in the existing dataset, and the model based on the dataset may cause biased predictions. Although this study has only been able to grasp a narrow range of stories, we expect that it offers the first step in considering the cognitive process of humans on the video understanding intelligence of humans and AI.
DramaQA: Character-Centered Video Story Understanding with Hierarchical QA
May 07, 2020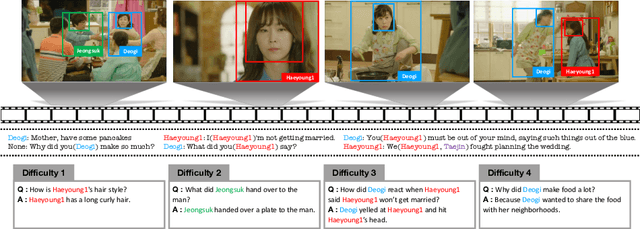
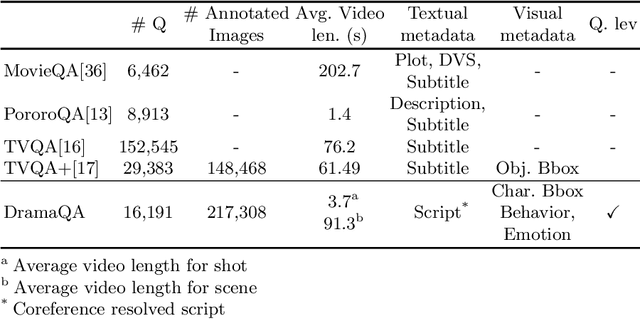
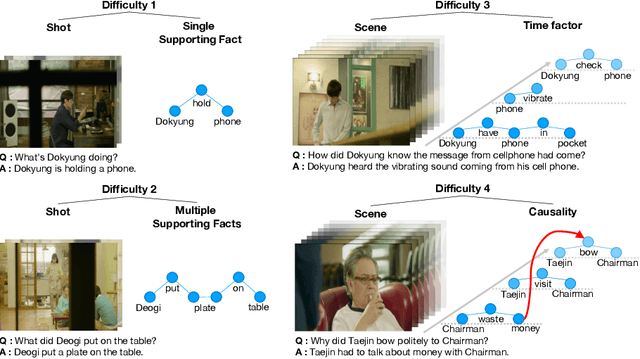
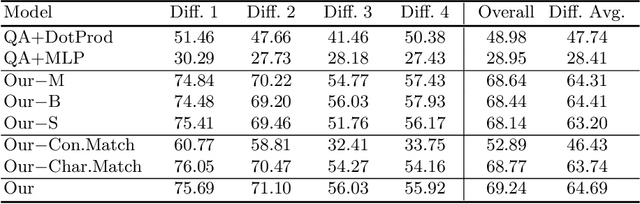
Despite recent progress on computer vision and natural language processing, developing video understanding intelligence is still hard to achieve due to the intrinsic difficulty of story in video. Moreover, there is not a theoretical metric for evaluating the degree of video understanding. In this paper, we propose a novel video question answering (Video QA) task, DramaQA, for a comprehensive understanding of the video story. The DramaQA focused on two perspectives: 1) hierarchical QAs as an evaluation metric based on the cognitive developmental stages of human intelligence. 2) character-centered video annotations to model local coherence of the story. Our dataset is built upon the TV drama "Another Miss Oh" and it contains 16,191 QA pairs from 23,928 various length video clips, with each QA pair belonging to one of four difficulty levels. We provide 217,308 annotated images with rich character-centered annotations, including visual bounding boxes, behaviors, and emotions of main characters, and coreference resolved scripts. Additionally, we provide analyses of the dataset as well as Dual Matching Multistream model which effectively learns character-centered representations of video to answer questions about the video. We are planning to release our dataset and model publicly for research purposes and expect that our work will provide a new perspective on video story understanding research.
Constructing Hierarchical Q&A Datasets for Video Story Understanding
Apr 01, 2019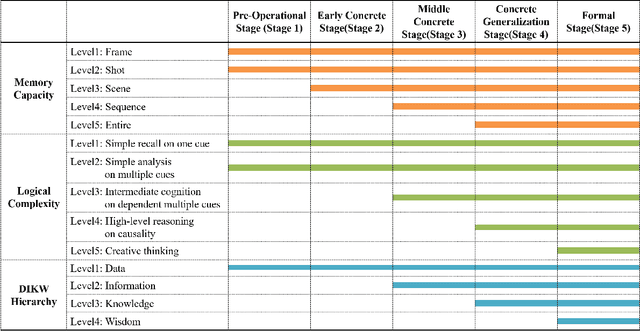
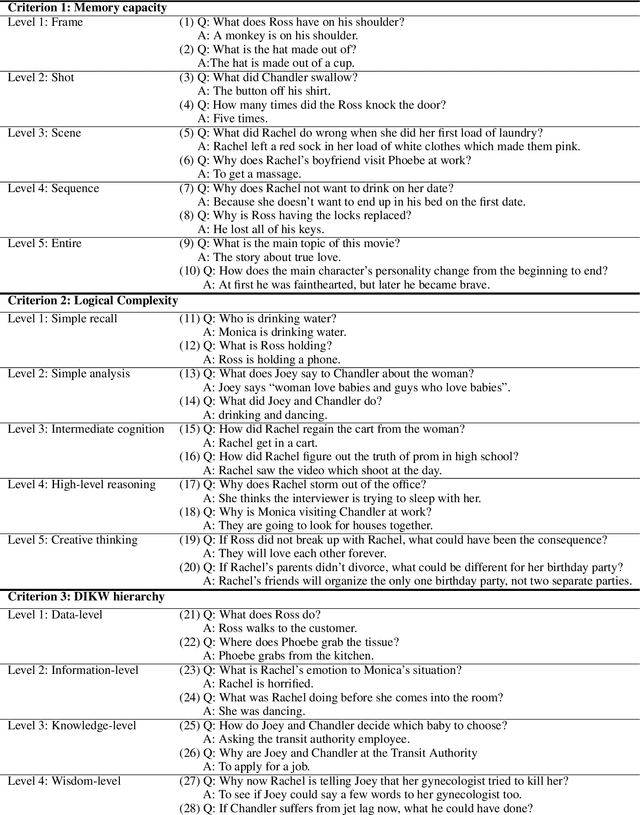
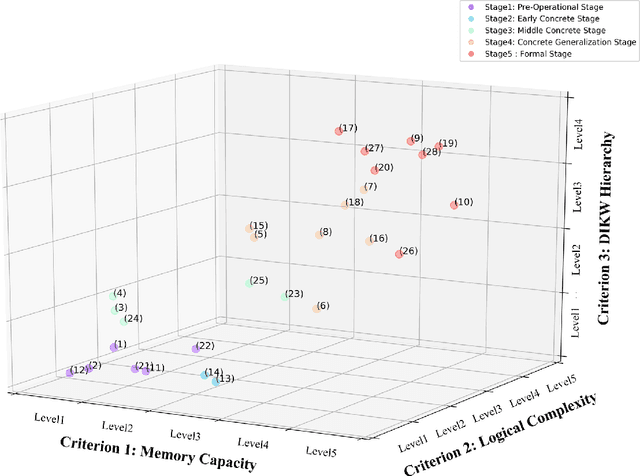
Video understanding is emerging as a new paradigm for studying human-like AI. Question-and-Answering (Q&A) is used as a general benchmark to measure the level of intelligence for video understanding. While several previous studies have suggested datasets for video Q&A tasks, they did not really incorporate story-level understanding, resulting in highly-biased and lack of variance in degree of question difficulty. In this paper, we propose a hierarchical method for building Q&A datasets, i.e. hierarchical difficulty levels. We introduce three criteria for video story understanding, i.e. memory capacity, logical complexity, and DIKW (Data-Information-Knowledge-Wisdom) pyramid. We discuss how three-dimensional map constructed from these criteria can be used as a metric for evaluating the levels of intelligence relating to video story understanding.