 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Ordinal Bias in Action Recognition for Instructional Videos
Apr 09, 2025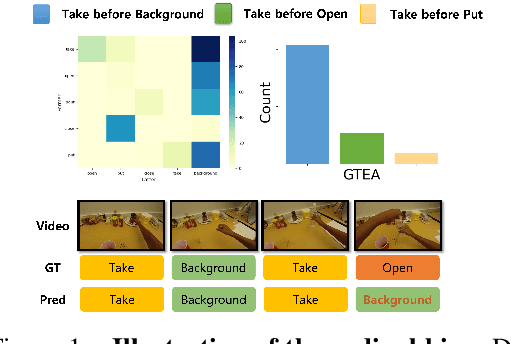

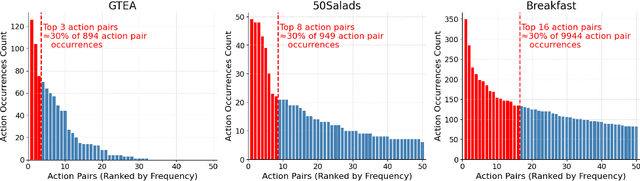

Action recognition models have achieved promising results in understanding instructional videos. However, they often rely on dominant, dataset-specific action sequences rather than true video comprehension, a problem that we define as ordinal bias. To address this issue, we propose two effective video manipulation methods: Action Masking, which masks frames of frequently co-occurring actions, and Sequence Shuffling, which randomizes the order of action segments. Through comprehensive experiments, we demonstrate that current models exhibit significant performance drops when confronted with nonstandard action sequences, underscoring their vulnerability to ordinal bias. Our findings emphasize the importance of rethinking evaluation strategies and developing models capable of generalizing beyond fixed action patterns in diverse instructional videos.
Continual Vision-and-Language Navigation
Mar 22, 2024Vision-and-Language Navigation (VLN) agents navigate to a destination using natural language instructions and the visual information they observe. Existing methods for training VLN agents presuppose fixed datasets, leading to a significant limitation: the introduction of new environments necessitates retraining with previously encountered environments to preserve their knowledge. This makes it difficult to train VLN agents that operate in the ever-changing real world. To address this limitation, we present the Continual Vision-and-Language Navigation (CVLN) paradigm, designed to evaluate agents trained through a continual learning process. For the training and evaluation of CVLN agents, we re-arrange existing VLN datasets to propose two datasets: CVLN-I, focused on navigation via initial-instruction interpretation, and CVLN-D, aimed at navigation through dialogue with other agents. Furthermore, we propose two novel rehearsal-based methods for CVLN, Perplexity Replay (PerpR) and Episodic Self-Replay (ESR). PerpR prioritizes replaying challenging episodes based on action perplexity, while ESR replays previously predicted action logits to preserve learned behaviors. We demonstrate the effectiveness of the proposed methods on CVLN through extensive experiments.
Overcoming Weak Visual-Textual Alignment for Video Moment Retrieval
Jun 05, 2023
Video moment retrieval (VMR) aims to identify the specific moment in an untrimmed video for a given natural language query. However, this task is prone to suffer the weak visual-textual alignment problem from query ambiguity, potentially limiting further performance gains and generalization capability. Due to the complex multimodal interactions in videos, a query may not fully cover the relevant details of the corresponding moment, and the moment may contain misaligned and irrelevant frames. To tackle this problem, we propose a straightforward yet effective model, called Background-aware Moment DEtection TRansformer (BM-DETR). Given a target query and its moment, BM-DETR also takes negative queries corresponding to different moments. Specifically, our model learns to predict the target moment from the joint probability of the given query and the complement of negative queries for each candidate frame. In this way, it leverages the surrounding background to consider relative importance, improving moment sensitivity. Extensive experiments on Charades-STA and QVHighlights demonstrate the effectiveness of our model. Moreover, we show that BM-DETR can perform robustly in three challenging VMR scenarios, such as several out-of-distribution test cases, demonstrating superior generalization ability.
Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval
Oct 23, 2022Video corpus moment retrieval (VCMR) is the task to retrieve the most relevant video moment from a large video corpus using a natural language query. For narrative videos, e.g., dramas or movies, the holistic understanding of temporal dynamics and multimodal reasoning is crucial. Previous works have shown promising results; however, they relied on the expensive query annotations for VCMR, i.e., the corresponding moment intervals. To overcome this problem, we propose a self-supervised learning framework: Modal-specific Pseudo Query Generation Network (MPGN). First, MPGN selects candidate temporal moments via subtitle-based moment sampling. Then, it generates pseudo queries exploiting both visual and textual information from the selected temporal moments. Through the multimodal information in the pseudo queries, we show that MPGN successfully learns to localize the video corpus moment without any explicit annotation. We validate the effectiveness of MPGN on the TVR dataset, showing competitive results compared with both supervised models and unsupervised setting models.