 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision
Nov 01, 2024This paper explores how non-experts can teach robots desired skills in their environments. We argue that natural language is an intuitive and accessible interface for robot learning. To this end, we investigate two key aspects: (1) how non-experts collect robotic data using natural language supervision and (2) how pre-trained vision-language models learn end-to-end policies directly from this supervision. We propose a data collection framework that collects robot demonstrations based on natural language supervision (e.g., "move forward") and further augments these demonstrations. Next, we introduce a model that learns language-conditioned policies from natural language supervision called CLIP-RT. Our model employs pre-trained CLIP models and learns to predict actions represented in language via contrastive imitation learning. We first train CLIP-RT on large-scale robotic data and then enable it to learn desired skills using data collected from our framework. CLIP-RT shows strong capabilities in acquiring novel manipulation skills, outperforming the state-of-the-art model, OpenVLA (7B parameters), by 17% in average success rates, while using 7x fewer parameters (1B).
Socratic Planner: Inquiry-Based Zero-Shot Planning for Embodied Instruction Following
Apr 21, 2024



Embodied Instruction Following (EIF) is the task of executing natural language instructions by navigating and interacting with objects in 3D environments. One of the primary challenges in EIF is compositional task planning, which is often addressed with supervised or in-context learning with labeled data. To this end, we introduce the Socratic Planner, the first zero-shot planning method that infers without the need for any training data. Socratic Planner first decomposes the instructions into substructural information of the task through self-questioning and answering, translating it into a high-level plan, i.e., a sequence of subgoals. Subgoals are executed sequentially, with our visually grounded re-planning mechanism adjusting plans dynamically through a dense visual feedback. We also introduce an evaluation metric of high-level plans, RelaxedHLP, for a more comprehensive evaluation. Experiments demonstrate the effectiveness of the Socratic Planner, achieving competitive performance on both zero-shot and few-shot task planning in the ALFRED benchmark, particularly excelling in tasks requiring higher-dimensional inference. Additionally, a precise adjustments in the plan were achieved by incorporating environmental visual information.
Continual Vision-and-Language Navigation
Mar 22, 2024Vision-and-Language Navigation (VLN) agents navigate to a destination using natural language instructions and the visual information they observe. Existing methods for training VLN agents presuppose fixed datasets, leading to a significant limitation: the introduction of new environments necessitates retraining with previously encountered environments to preserve their knowledge. This makes it difficult to train VLN agents that operate in the ever-changing real world. To address this limitation, we present the Continual Vision-and-Language Navigation (CVLN) paradigm, designed to evaluate agents trained through a continual learning process. For the training and evaluation of CVLN agents, we re-arrange existing VLN datasets to propose two datasets: CVLN-I, focused on navigation via initial-instruction interpretation, and CVLN-D, aimed at navigation through dialogue with other agents. Furthermore, we propose two novel rehearsal-based methods for CVLN, Perplexity Replay (PerpR) and Episodic Self-Replay (ESR). PerpR prioritizes replaying challenging episodes based on action perplexity, while ESR replays previously predicted action logits to preserve learned behaviors. We demonstrate the effectiveness of the proposed methods on CVLN through extensive experiments.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023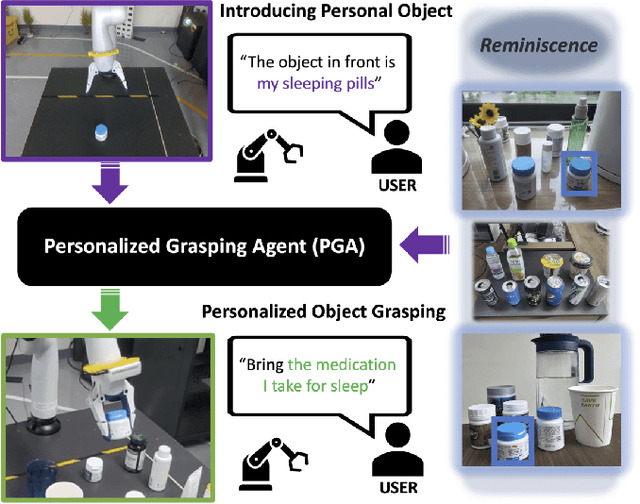
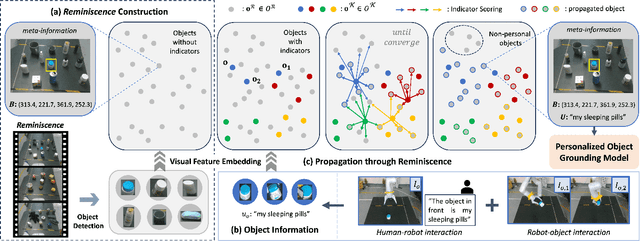
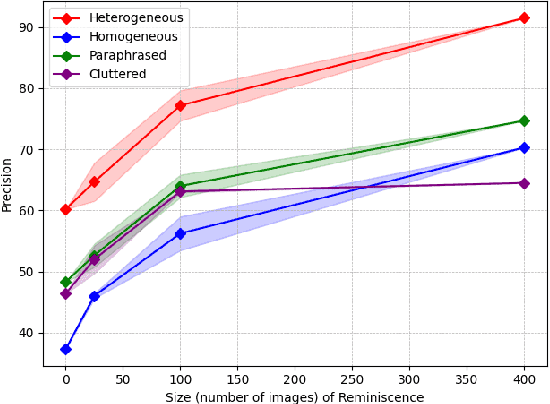
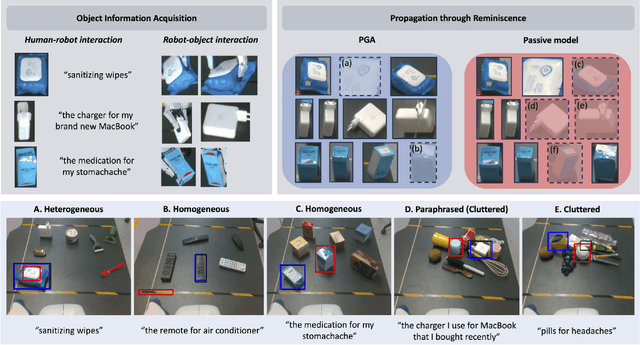
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.
PROGrasp: Pragmatic Human-Robot Communication for Object Grasping
Sep 14, 2023



Interactive Object Grasping (IOG) is the task of identifying and grasping the desired object via human-robot natural language interaction. Current IOG systems assume that a human user initially specifies the target object's category (e.g., bottle). Inspired by pragmatics, where humans often convey their intentions by relying on context to achieve goals, we introduce a new IOG task, Pragmatic-IOG, and the corresponding dataset, Intention-oriented Multi-modal Dialogue (IM-Dial). In our proposed task scenario, an intention-oriented utterance (e.g., "I am thirsty") is initially given to the robot. The robot should then identify the target object by interacting with a human user. Based on the task setup, we propose a new robotic system that can interpret the user's intention and pick up the target object, Pragmatic Object Grasping (PROGrasp). PROGrasp performs Pragmatic-IOG by incorporating modules for visual grounding, question asking, object grasping, and most importantly, answer interpretation for pragmatic inference. Experimental results show that PROGrasp is effective in offline (i.e., target object discovery) and online (i.e., IOG with a physical robot arm) settings.
GVCCI: Lifelong Learning of Visual Grounding for Language-Guided Robotic Manipulation
Jul 12, 2023



Language-Guided Robotic Manipulation (LGRM) is a challenging task as it requires a robot to understand human instructions to manipulate everyday objects. Recent approaches in LGRM rely on pre-trained Visual Grounding (VG) models to detect objects without adapting to manipulation environments. This results in a performance drop due to a substantial domain gap between the pre-training and real-world data. A straightforward solution is to collect additional training data, but the cost of human-annotation is extortionate. In this paper, we propose Grounding Vision to Ceaselessly Created Instructions (GVCCI), a lifelong learning framework for LGRM, which continuously learns VG without human supervision. GVCCI iteratively generates synthetic instruction via object detection and trains the VG model with the generated data. We validate our framework in offline and online settings across diverse environments on different VG models. Experimental results show that accumulating synthetic data from GVCCI leads to a steady improvement in VG by up to 56.7% and improves resultant LGRM by up to 29.4%. Furthermore, the qualitative analysis shows that the unadapted VG model often fails to find correct objects due to a strong bias learned from the pre-training data. Finally, we introduce a novel VG dataset for LGRM, consisting of nearly 252k triplets of image-object-instruction from diverse manipulation environments.
The Dialog Must Go On: Improving Visual Dialog via Generative Self-Training
May 25, 2022
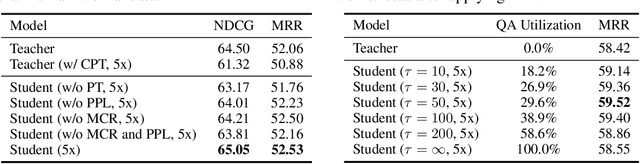


Visual dialog (VisDial) is a task of answering a sequence of questions grounded in an image, using the dialog history as context. Prior work has trained the dialog agents solely on VisDial data via supervised learning or leveraged pre-training on related vision-and-language datasets. This paper presents a semi-supervised learning approach for visually-grounded dialog, called Generative Self-Training (GST), to leverage unlabeled images on the Web. Specifically, GST first retrieves in-domain images through out-of-distribution detection and generates synthetic dialogs regarding the images via multimodal conditional text generation. GST then trains a dialog agent on the synthetic and the original VisDial data. As a result, GST scales the amount of training data up to an order of magnitude that of VisDial (1.2M to 12.9M QA data). For robust training of the generated dialogs, we also propose perplexity-based data selection and multimodal consistency regularization. Evaluation on VisDial v1.0 and v0.9 datasets shows that GST achieves new state-of-the-art results on both datasets. We further observe strong performance gains in the low-data regime (up to 9.35 absolute points on NDCG).
Attend What You Need: Motion-Appearance Synergistic Networks for Video Question Answering
Jun 19, 2021
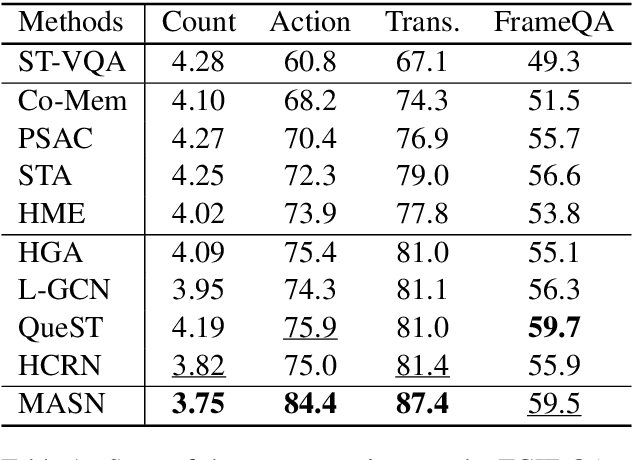
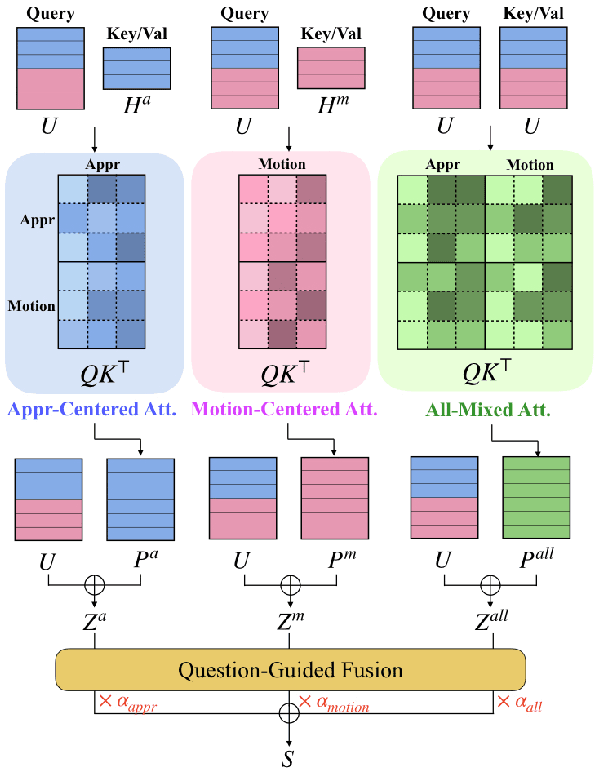
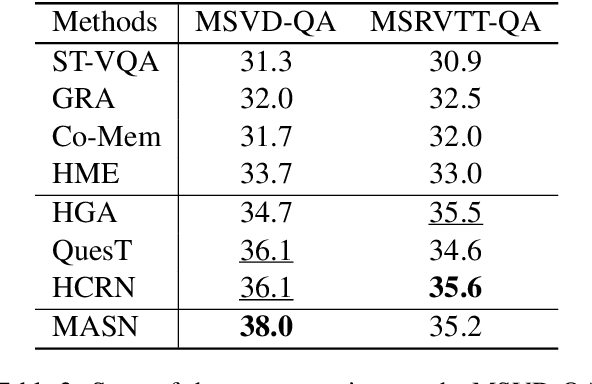
Video Question Answering is a task which requires an AI agent to answer questions grounded in video. This task entails three key challenges: (1) understand the intention of various questions, (2) capturing various elements of the input video (e.g., object, action, causality), and (3) cross-modal grounding between language and vision information. We propose Motion-Appearance Synergistic Networks (MASN), which embed two cross-modal features grounded on motion and appearance information and selectively utilize them depending on the question's intentions. MASN consists of a motion module, an appearance module, and a motion-appearance fusion module. The motion module computes the action-oriented cross-modal joint representations, while the appearance module focuses on the appearance aspect of the input video. Finally, the motion-appearance fusion module takes each output of the motion module and the appearance module as input, and performs question-guided fusion. As a result, MASN achieves new state-of-the-art performance on the TGIF-QA and MSVD-QA datasets. We also conduct qualitative analysis by visualizing the inference results of MASN. The code is available at https://github.com/ahjeongseo/MASN-pytorch.
Label Propagation Adaptive Resonance Theory for Semi-supervised Continuous Learning
Apr 16, 2020
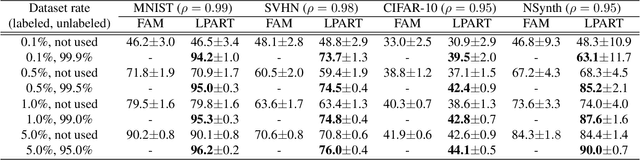
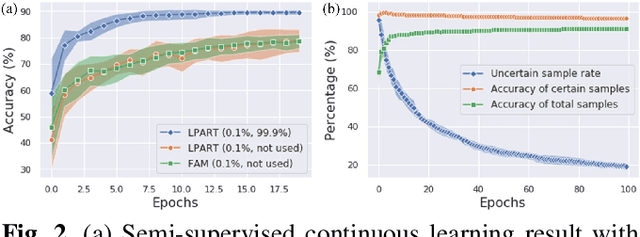
Semi-supervised learning and continuous learning are fundamental paradigms for human-level intelligence. To deal with real-world problems where labels are rarely given and the opportunity to access the same data is limited, it is necessary to apply these two paradigms in a joined fashion. In this paper, we propose Label Propagation Adaptive Resonance Theory (LPART) for semi-supervised continuous learning. LPART uses an online label propagation mechanism to perform classification and gradually improves its accuracy as the observed data accumulates. We evaluated the proposed model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets by adjusting the ratio of the labeled and unlabeled data. The accuracies are much higher when both labeled and unlabeled data are used, demonstrating the significant advantage of LPART in environments where the data labels are scarce.
DialGraph: Sparse Graph Learning Networks for Visual Dialog
Apr 14, 2020
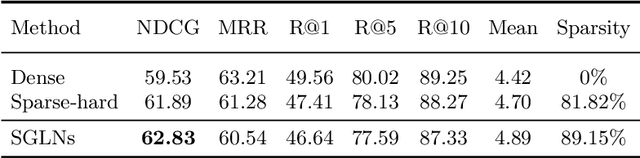
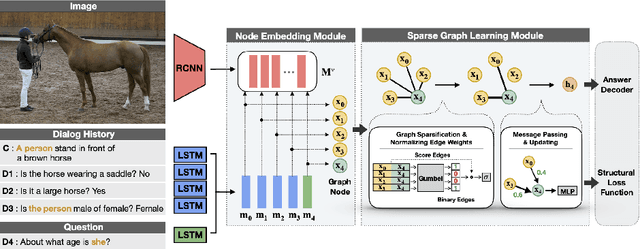
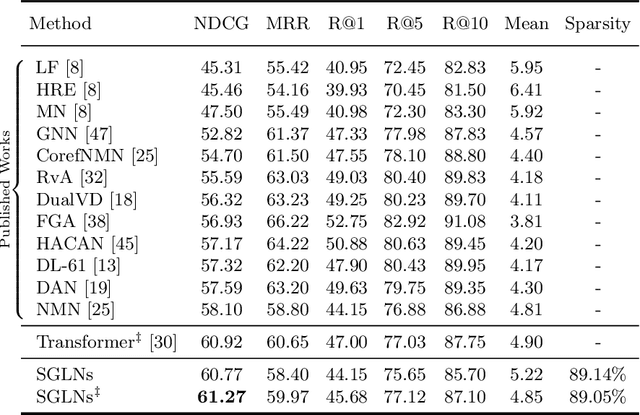
Visual dialog is a task of answering a sequence of questions grounded in an image utilizing a dialog history. Previous studies have implicitly explored the problem of reasoning semantic structures among the history using softmax attention. However, we argue that the softmax attention yields dense structures that could distract to answer the questions requiring partial or even no contextual information. In this paper, we formulate the visual dialog tasks as graph structure learning tasks. To tackle the problem, we propose Sparse Graph Learning Networks (SGLNs) consisting of a multimodal node embedding module and a sparse graph learning module. The proposed model explicitly learn sparse dialog structures by incorporating binary and score edges, leveraging a new structural loss function. Then, it finally outputs the answer, updating each node via a message passing framework. As a result, the proposed model outperforms the state-of-the-art approaches on the VisDial v1.0 dataset, only using 10.95% of the dialog history, as well as improves interpretability compared to baseline methods.