 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse to Dense: Toddler-inspired Reward Transition in Goal-Oriented Reinforcement Learning
Jan 29, 2025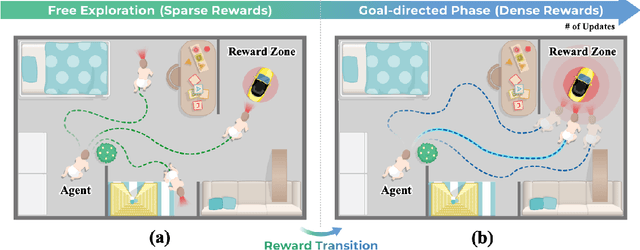
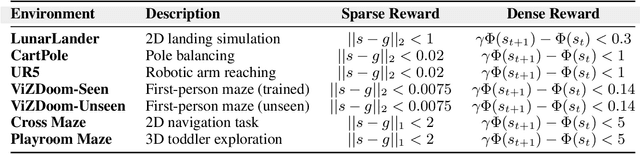
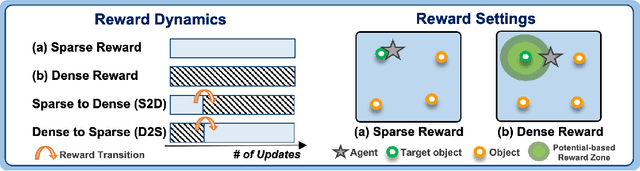
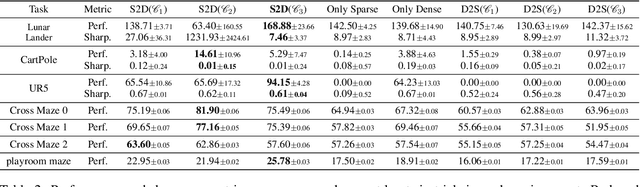
Reinforcement learning (RL) agents often face challenges in balancing exploration and exploitation, particularly in environments where sparse or dense rewards bias learning. Biological systems, such as human toddlers, naturally navigate this balance by transitioning from free exploration with sparse rewards to goal-directed behavior guided by increasingly dense rewards. Inspired by this natural progression, we investigate the Toddler-Inspired Reward Transition in goal-oriented RL tasks. Our study focuses on transitioning from sparse to potential-based dense (S2D) rewards while preserving optimal strategies. Through experiments on dynamic robotic arm manipulation and egocentric 3D navigation tasks, we demonstrate that effective S2D reward transitions significantly enhance learning performance and sample efficiency. Additionally, using a Cross-Density Visualizer, we show that S2D transitions smooth the policy loss landscape, resulting in wider minima that improve generalization in RL models. In addition, we reinterpret Tolman's maze experiments, underscoring the critical role of early free exploratory learning in the context of S2D rewards.
Unveiling the Significance of Toddler-Inspired Reward Transition in Goal-Oriented Reinforcement Learning
Mar 18, 2024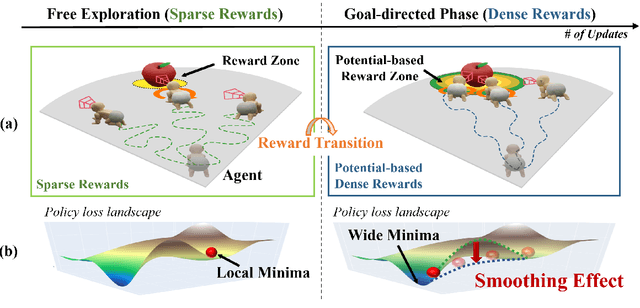

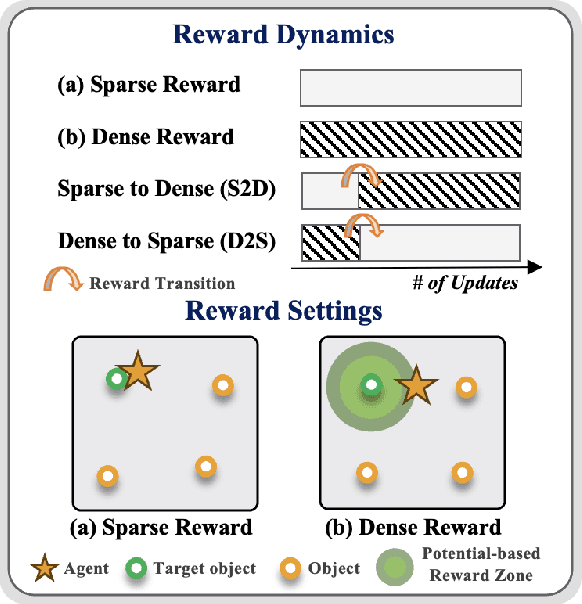
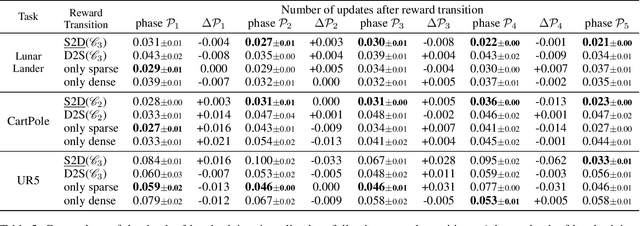
Toddlers evolve from free exploration with sparse feedback to exploiting prior experiences for goal-directed learning with denser rewards. Drawing inspiration from this Toddler-Inspired Reward Transition, we set out to explore the implications of varying reward transitions when incorporated into Reinforcement Learning (RL) tasks. Central to our inquiry is the transition from sparse to potential-based dense rewards, which share optimal strategies regardless of reward changes. Through various experiments, including those in egocentric navigation and robotic arm manipulation tasks, we found that proper reward transitions significantly influence sample efficiency and success rates. Of particular note is the efficacy of the toddler-inspired Sparse-to-Dense (S2D) transition. Beyond these performance metrics, using Cross-Density Visualizer technique, we observed that transitions, especially the S2D, smooth the policy loss landscape, promoting wide minima that enhance generalization in RL models.
DUEL: Duplicate Elimination on Active Memory for Self-Supervised Class-Imbalanced Learning
Feb 14, 2024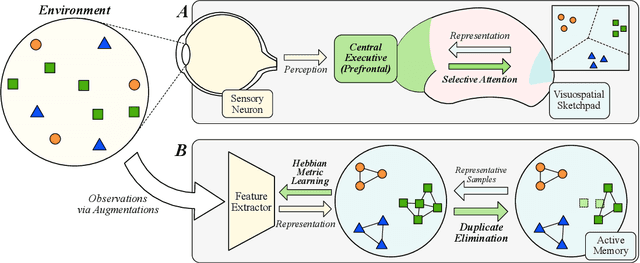
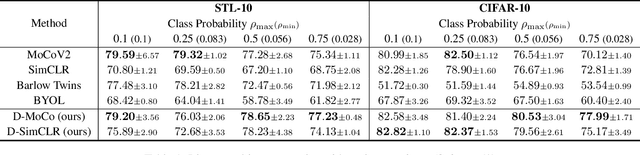
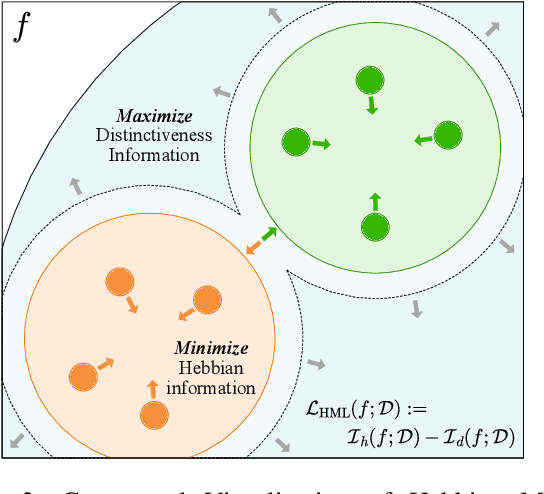
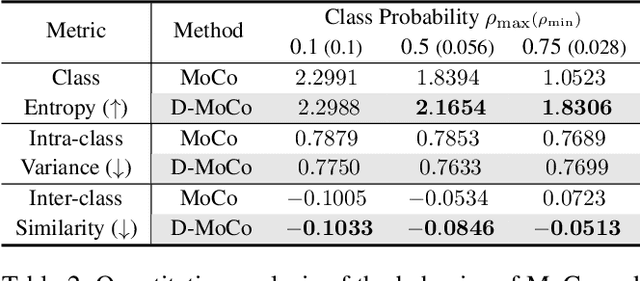
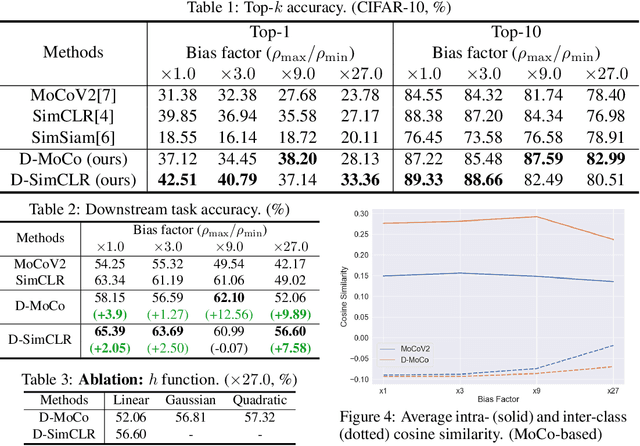
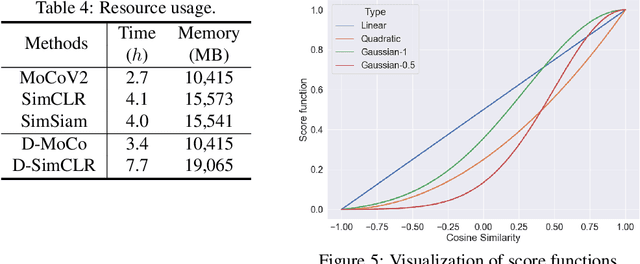
Recent machine learning algorithms have been developed using well-curated datasets, which often require substantial cost and resources. On the other hand, the direct use of raw data often leads to overfitting towards frequently occurring class information. To address class imbalances cost-efficiently, we propose an active data filtering process during self-supervised pre-training in our novel framework, Duplicate Elimination (DUEL). This framework integrates an active memory inspired by human working memory and introduces distinctiveness information, which measures the diversity of the data in the memory, to optimize both the feature extractor and the memory. The DUEL policy, which replaces the most duplicated data with new samples, aims to enhance the distinctiveness information in the memory and thereby mitigate class imbalances. We validate the effectiveness of the DUEL framework in class-imbalanced environments, demonstrating its robustness and providing reliable results in downstream tasks. We also analyze the role of the DUEL policy in the training process through various metrics and visualizations.
Learning Geometry-aware Representations by Sketching
Apr 17, 2023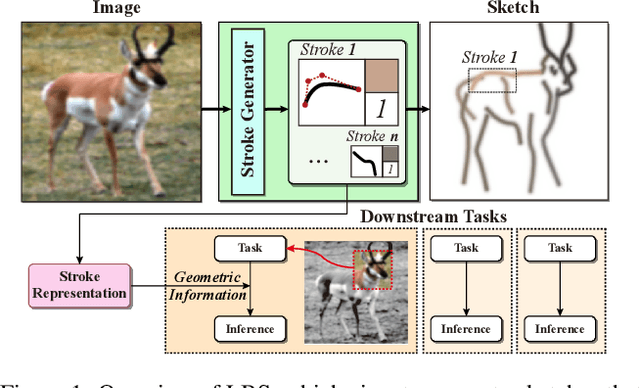
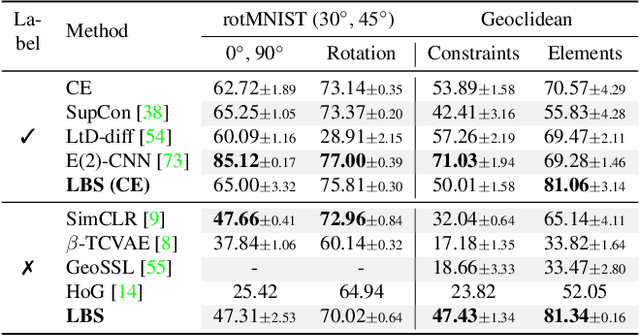
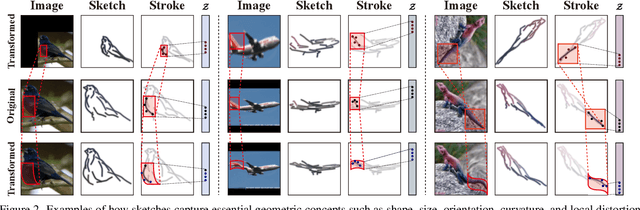
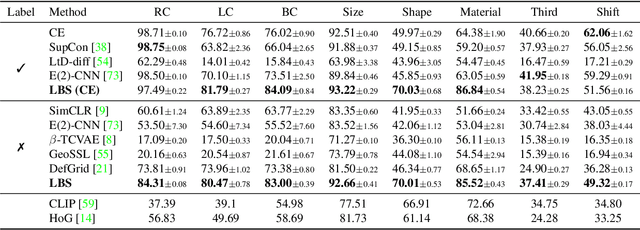
Understanding geometric concepts, such as distance and shape, is essential for understanding the real world and also for many vision tasks. To incorporate such information into a visual representation of a scene, we propose learning to represent the scene by sketching, inspired by human behavior. Our method, coined Learning by Sketching (LBS), learns to convert an image into a set of colored strokes that explicitly incorporate the geometric information of the scene in a single inference step without requiring a sketch dataset. A sketch is then generated from the strokes where CLIP-based perceptual loss maintains a semantic similarity between the sketch and the image. We show theoretically that sketching is equivariant with respect to arbitrary affine transformations and thus provably preserves geometric information. Experimental results show that LBS substantially improves the performance of object attribute classification on the unlabeled CLEVR dataset, domain transfer between CLEVR and STL-10 datasets, and for diverse downstream tasks, confirming that LBS provides rich geometric information.
DUEL: Adaptive Duplicate Elimination on Working Memory for Self-Supervised Learning
Oct 31, 2022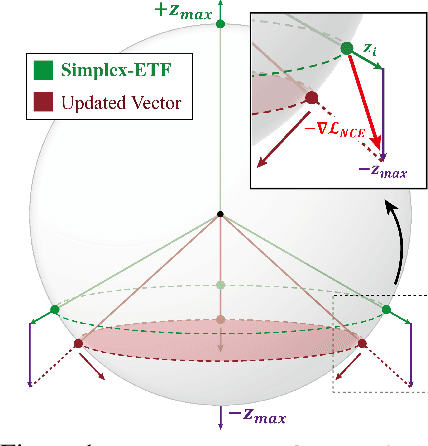
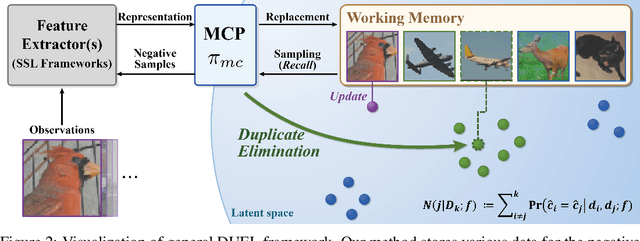
In Self-Supervised Learning (SSL), it is known that frequent occurrences of the collision in which target data and its negative samples share the same class can decrease performance. Especially in real-world data such as crawled data or robot-gathered observations, collisions may occur more often due to the duplicates in the data. To deal with this problem, we claim that sampling negative samples from the adaptively debiased distribution in the memory makes the model more stable than sampling from a biased dataset directly. In this paper, we introduce a novel SSL framework with adaptive Duplicate Elimination (DUEL) inspired by the human working memory. The proposed framework successfully prevents the downstream task performance from degradation due to a dramatic inter-class imbalance.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020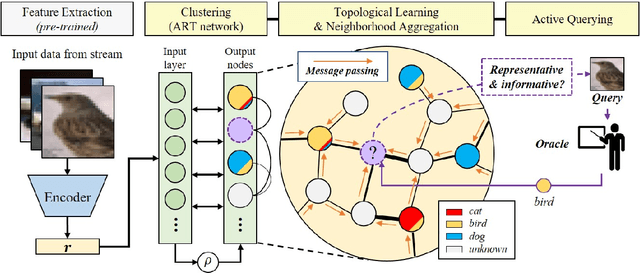
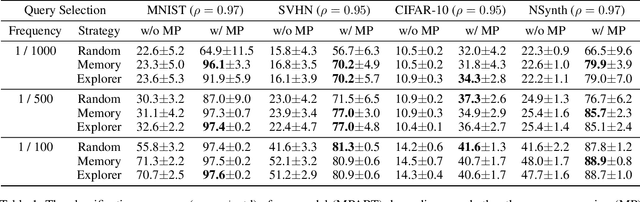

Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.
Label Propagation Adaptive Resonance Theory for Semi-supervised Continuous Learning
Apr 16, 2020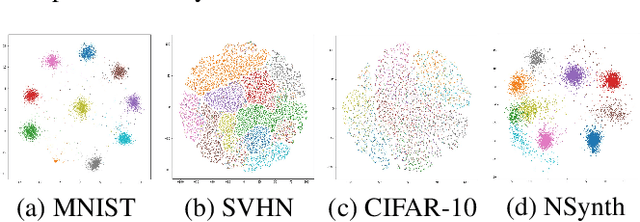
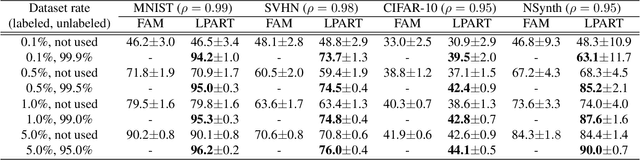
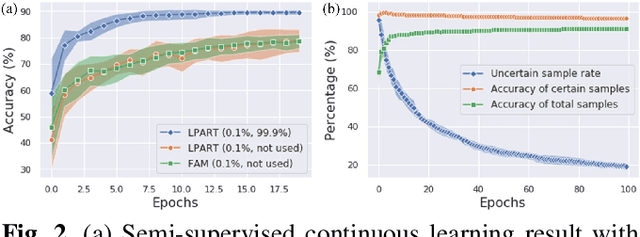
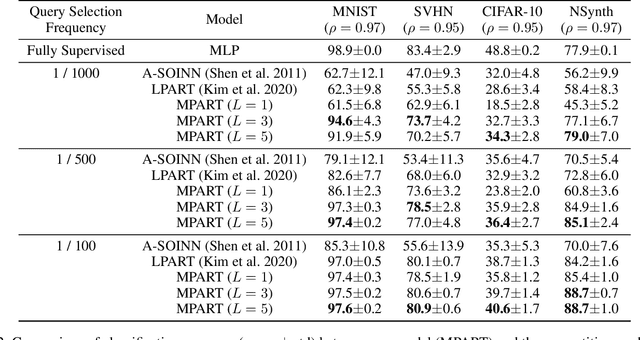
Semi-supervised learning and continuous learning are fundamental paradigms for human-level intelligence. To deal with real-world problems where labels are rarely given and the opportunity to access the same data is limited, it is necessary to apply these two paradigms in a joined fashion. In this paper, we propose Label Propagation Adaptive Resonance Theory (LPART) for semi-supervised continuous learning. LPART uses an online label propagation mechanism to perform classification and gradually improves its accuracy as the observed data accumulates. We evaluated the proposed model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets by adjusting the ratio of the labeled and unlabeled data. The accuracies are much higher when both labeled and unlabeled data are used, demonstrating the significant advantage of LPART in environments where the data labels are scarce.