 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse to Dense: Toddler-inspired Reward Transition in Goal-Oriented Reinforcement Learning
Jan 29, 2025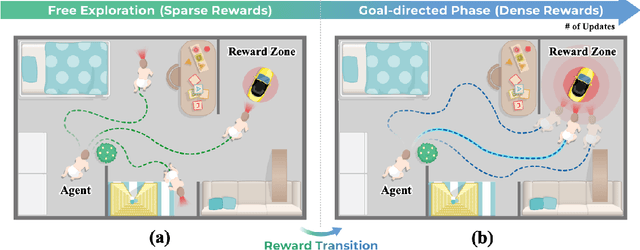
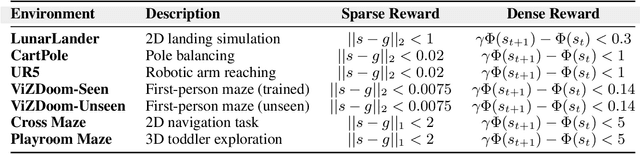
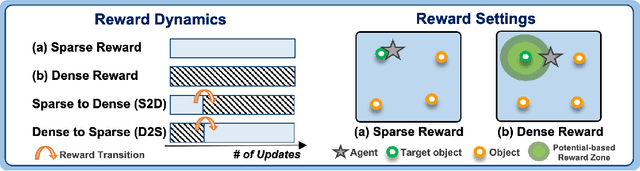
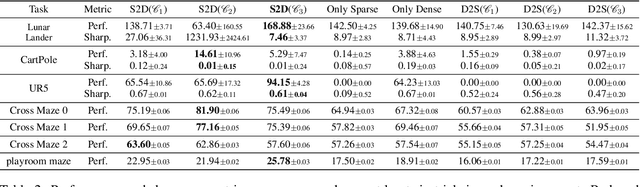
Reinforcement learning (RL) agents often face challenges in balancing exploration and exploitation, particularly in environments where sparse or dense rewards bias learning. Biological systems, such as human toddlers, naturally navigate this balance by transitioning from free exploration with sparse rewards to goal-directed behavior guided by increasingly dense rewards. Inspired by this natural progression, we investigate the Toddler-Inspired Reward Transition in goal-oriented RL tasks. Our study focuses on transitioning from sparse to potential-based dense (S2D) rewards while preserving optimal strategies. Through experiments on dynamic robotic arm manipulation and egocentric 3D navigation tasks, we demonstrate that effective S2D reward transitions significantly enhance learning performance and sample efficiency. Additionally, using a Cross-Density Visualizer, we show that S2D transitions smooth the policy loss landscape, resulting in wider minima that improve generalization in RL models. In addition, we reinterpret Tolman's maze experiments, underscoring the critical role of early free exploratory learning in the context of S2D rewards.
Unveiling the Significance of Toddler-Inspired Reward Transition in Goal-Oriented Reinforcement Learning
Mar 18, 2024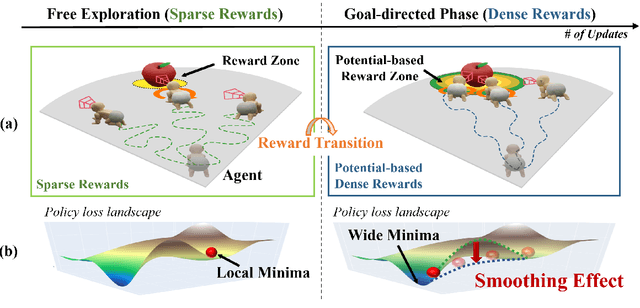

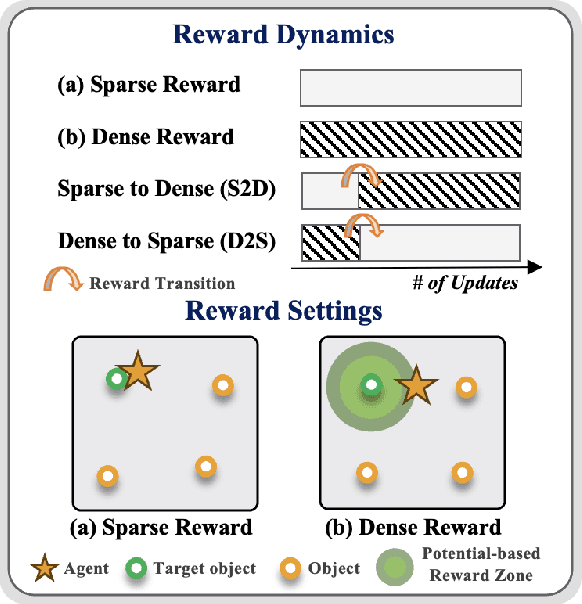
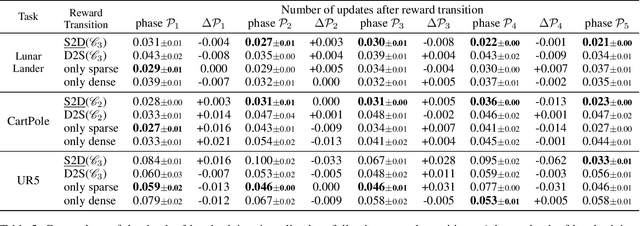
Toddlers evolve from free exploration with sparse feedback to exploiting prior experiences for goal-directed learning with denser rewards. Drawing inspiration from this Toddler-Inspired Reward Transition, we set out to explore the implications of varying reward transitions when incorporated into Reinforcement Learning (RL) tasks. Central to our inquiry is the transition from sparse to potential-based dense rewards, which share optimal strategies regardless of reward changes. Through various experiments, including those in egocentric navigation and robotic arm manipulation tasks, we found that proper reward transitions significantly influence sample efficiency and success rates. Of particular note is the efficacy of the toddler-inspired Sparse-to-Dense (S2D) transition. Beyond these performance metrics, using Cross-Density Visualizer technique, we observed that transitions, especially the S2D, smooth the policy loss landscape, promoting wide minima that enhance generalization in RL models.
Visual Hindsight Self-Imitation Learning for Interactive Navigation
Dec 05, 2023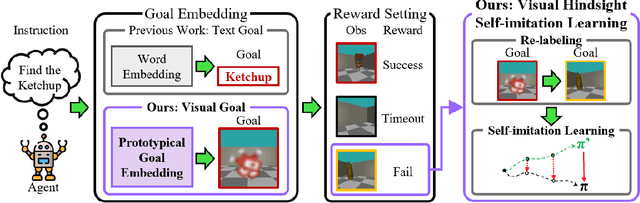
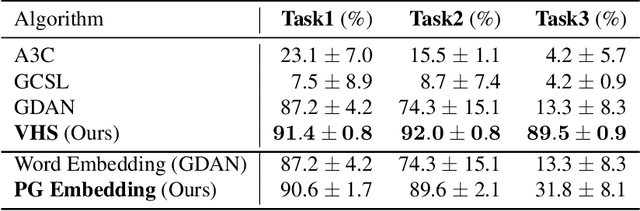
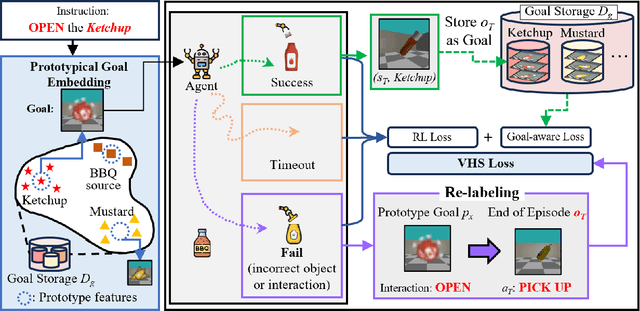
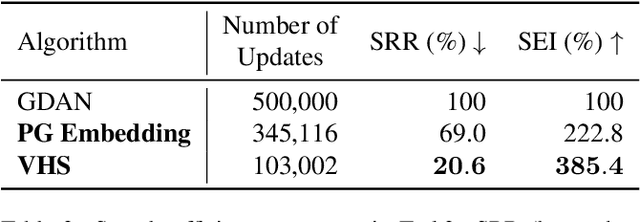
Interactive visual navigation tasks, which involve following instructions to reach and interact with specific targets, are challenging not only because successful experiences are very rare but also because the complex visual inputs require a substantial number of samples. Previous methods for these tasks often rely on intricately designed dense rewards or the use of expensive expert data for imitation learning. To tackle these challenges, we propose a novel approach, Visual Hindsight Self-Imitation Learning (VHS) for enhancing sample efficiency through hindsight goal re-labeling and self-imitation. We also introduce a prototypical goal embedding method derived from experienced goal observations, that is particularly effective in vision-based and partially observable environments. This embedding technique allows the agent to visually reinterpret its unsuccessful attempts, enabling vision-based goal re-labeling and self-imitation from enhanced successful experiences. Experimental results show that VHS outperforms existing techniques in interactive visual navigation tasks, confirming its superior performance and sample efficiency.
L-SA: Learning Under-Explored Targets in Multi-Target Reinforcement Learning
May 23, 2023



Tasks that involve interaction with various targets are called multi-target tasks. When applying general reinforcement learning approaches for such tasks, certain targets that are difficult to access or interact with may be neglected throughout the course of training - a predicament we call Under-explored Target Problem (UTP). To address this problem, we propose L-SA (Learning by adaptive Sampling and Active querying) framework that includes adaptive sampling and active querying. In the L-SA framework, adaptive sampling dynamically samples targets with the highest increase of success rates at a high proportion, resulting in curricular learning from easy to hard targets. Active querying prompts the agent to interact more frequently with under-explored targets that need more experience or exploration. Our experimental results on visual navigation tasks show that the L-SA framework improves sample efficiency as well as success rates on various multi-target tasks with UTP. Also, it is experimentally demonstrated that the cyclic relationship between adaptive sampling and active querying effectively improves the sample richness of under-explored targets and alleviates UTP.
On the Importance of Critical Period in Multi-stage Reinforcement Learning
Aug 09, 2022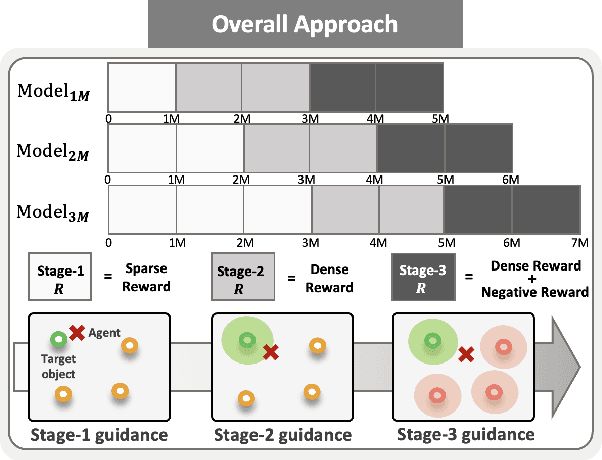
The initial years of an infant's life are known as the critical period, during which the overall development of learning performance is significantly impacted due to neural plasticity. In recent studies, an AI agent, with a deep neural network mimicking mechanisms of actual neurons, exhibited a learning period similar to human's critical period. Especially during this initial period, the appropriate stimuli play a vital role in developing learning ability. However, transforming human cognitive bias into an appropriate shaping reward is quite challenging, and prior works on critical period do not focus on finding the appropriate stimulus. To take a step further, we propose multi-stage reinforcement learning to emphasize finding ``appropriate stimulus" around the critical period. Inspired by humans' early cognitive-developmental stage, we use multi-stage guidance near the critical period, and demonstrate the appropriate shaping reward (stage-2 guidance) in terms of the AI agent's performance, efficiency, and stability.
Goal-Aware Cross-Entropy for Multi-Target Reinforcement Learning
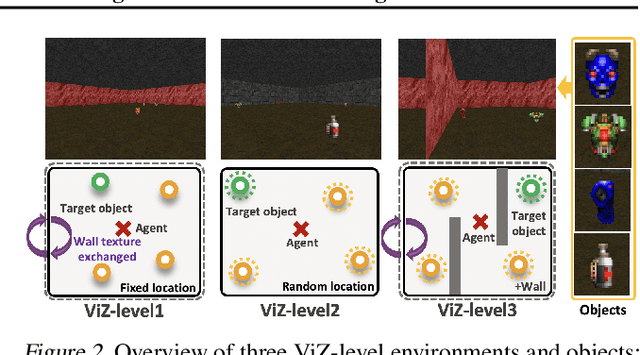
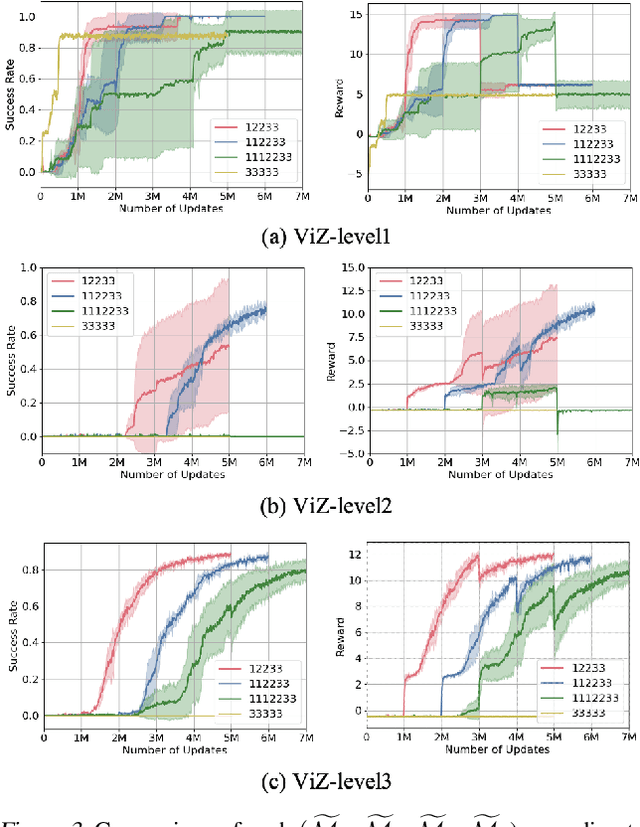
Oct 26, 2021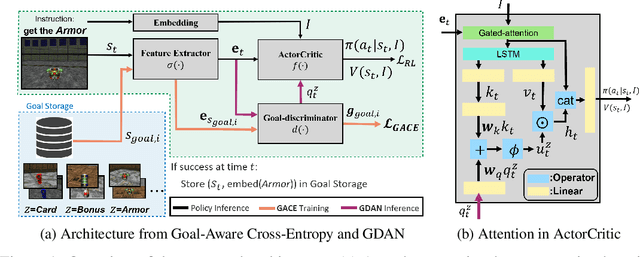
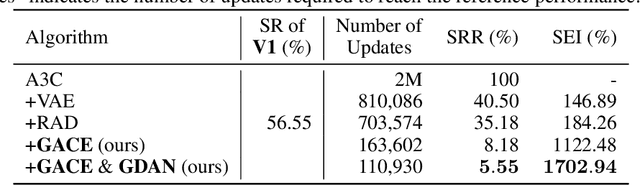


Learning in a multi-target environment without prior knowledge about the targets requires a large amount of samples and makes generalization difficult. To solve this problem, it is important to be able to discriminate targets through semantic understanding. In this paper, we propose goal-aware cross-entropy (GACE) loss, that can be utilized in a self-supervised way using auto-labeled goal states alongside reinforcement learning. Based on the loss, we then devise goal-discriminative attention networks (GDAN) which utilize the goal-relevant information to focus on the given instruction. We evaluate the proposed methods on visual navigation and robot arm manipulation tasks with multi-target environments and show that GDAN outperforms the state-of-the-art methods in terms of task success ratio, sample efficiency, and generalization. Additionally, qualitative analyses demonstrate that our proposed method can help the agent become aware of and focus on the given instruction clearly, promoting goal-directed behavior.