 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
Papez: Resource-Efficient Speech Separation with Auditory Working Memory
Jul 01, 2024



Transformer-based models recently reached state-of-the-art single-channel speech separation accuracy; However, their extreme computational load makes it difficult to deploy them in resource-constrained mobile or IoT devices. We thus present Papez, a lightweight and computation-efficient single-channel speech separation model. Papez is based on three key techniques. We first replace the inter-chunk Transformer with small-sized auditory working memory. Second, we adaptively prune the input tokens that do not need further processing. Finally, we reduce the number of parameters through the recurrent transformer. Our extensive evaluation shows that Papez achieves the best resource and accuracy tradeoffs with a large margin. We publicly share our source code at \texttt{https://github.com/snuhcs/Papez}
Sign Gradient Descent-based Neuronal Dynamics: ANN-to-SNN Conversion Beyond ReLU Network
Jul 01, 2024



Spiking neural network (SNN) is studied in multidisciplinary domains to (i) enable order-of-magnitudes energy-efficient AI inference and (ii) computationally simulate neuro-scientific mechanisms. The lack of discrete theory obstructs the practical application of SNN by limiting its performance and nonlinearity support. We present a new optimization-theoretic perspective of the discrete dynamics of spiking neurons. We prove that a discrete dynamical system of simple integrate-and-fire models approximates the sub-gradient method over unconstrained optimization problems. We practically extend our theory to introduce a novel sign gradient descent (signGD)-based neuronal dynamics that can (i) approximate diverse nonlinearities beyond ReLU and (ii) advance ANN-to-SNN conversion performance in low time steps. Experiments on large-scale datasets show that our technique achieves (i) state-of-the-art performance in ANN-to-SNN conversion and (ii) is the first to convert new DNN architectures, e.g., ConvNext, MLP-Mixer, and ResMLP. We publicly share our source code at https://github.com/snuhcs/snn_signgd .
Mondrian: On-Device High-Performance Video Analytics with Compressive Packed Inference
Mar 12, 2024In this paper, we present Mondrian, an edge system that enables high-performance object detection on high-resolution video streams. Many lightweight models and system optimization techniques have been proposed for resource-constrained devices, but they do not fully utilize the potential of the accelerators over dynamic, high-resolution videos. To enable such capability, we devise a novel Compressive Packed Inference to minimize per-pixel processing costs by selectively determining the necessary pixels to process and combining them to maximize processing parallelism. In particular, our system quickly extracts ROIs and dynamically shrinks them, reflecting the effect of the fast-changing characteristics of objects and scenes. It then intelligently combines such scaled ROIs into large canvases to maximize the utilization of inference accelerators such as GPU. Evaluation across various datasets, models, and devices shows Mondrian outperforms state-of-the-art baselines (e.g., input rescaling, ROI extractions, ROI extractions+batching) by 15.0-19.7% higher accuracy, leading to $\times$6.65 higher throughput than frame-wise inference for processing various 1080p video streams. We will release the code after the paper review.
Attention-Propagation Network for Egocentric Heatmap to 3D Pose Lifting
Feb 28, 2024We present EgoTAP, a heatmap-to-3D pose lifting method for highly accurate stereo egocentric 3D pose estimation. Severe self-occlusion and out-of-view limbs in egocentric camera views make accurate pose estimation a challenging problem. To address the challenge, prior methods employ joint heatmaps-probabilistic 2D representations of the body pose, but heatmap-to-3D pose conversion still remains an inaccurate process. We propose a novel heatmap-to-3D lifting method composed of the Grid ViT Encoder and the Propagation Network. The Grid ViT Encoder summarizes joint heatmaps into effective feature embedding using self-attention. Then, the Propagation Network estimates the 3D pose by utilizing skeletal information to better estimate the position of obscure joints. Our method significantly outperforms the previous state-of-the-art qualitatively and quantitatively demonstrated by a 23.9\% reduction of error in an MPJPE metric. Our source code is available in GitHub.
Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views
Sep 21, 2023We present Ego3DPose, a highly accurate binocular egocentric 3D pose reconstruction system. The binocular egocentric setup offers practicality and usefulness in various applications, however, it remains largely under-explored. It has been suffering from low pose estimation accuracy due to viewing distortion, severe self-occlusion, and limited field-of-view of the joints in egocentric 2D images. Here, we notice that two important 3D cues, stereo correspondences, and perspective, contained in the egocentric binocular input are neglected. Current methods heavily rely on 2D image features, implicitly learning 3D information, which introduces biases towards commonly observed motions and leads to low overall accuracy. We observe that they not only fail in challenging occlusion cases but also in estimating visible joint positions. To address these challenges, we propose two novel approaches. First, we design a two-path network architecture with a path that estimates pose per limb independently with its binocular heatmaps. Without full-body information provided, it alleviates bias toward trained full-body distribution. Second, we leverage the egocentric view of body limbs, which exhibits strong perspective variance (e.g., a significantly large-size hand when it is close to the camera). We propose a new perspective-aware representation using trigonometry, enabling the network to estimate the 3D orientation of limbs. Finally, we develop an end-to-end pose reconstruction network that synergizes both techniques. Our comprehensive evaluations demonstrate that Ego3DPose outperforms state-of-the-art models by a pose estimation error (i.e., MPJPE) reduction of 23.1% in the UnrealEgo dataset. Our qualitative results highlight the superiority of our approach across a range of scenarios and challenges.
On the Importance of Critical Period in Multi-stage Reinforcement Learning
Aug 09, 2022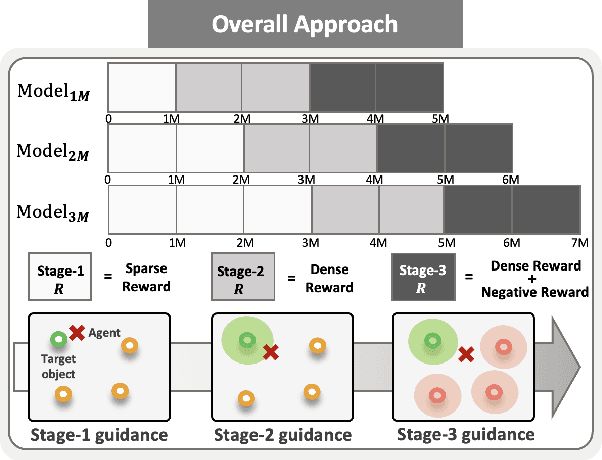
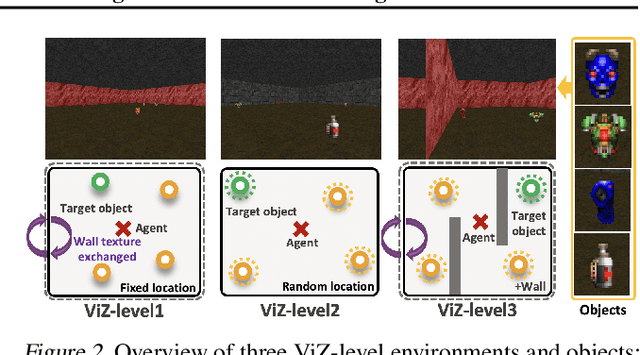
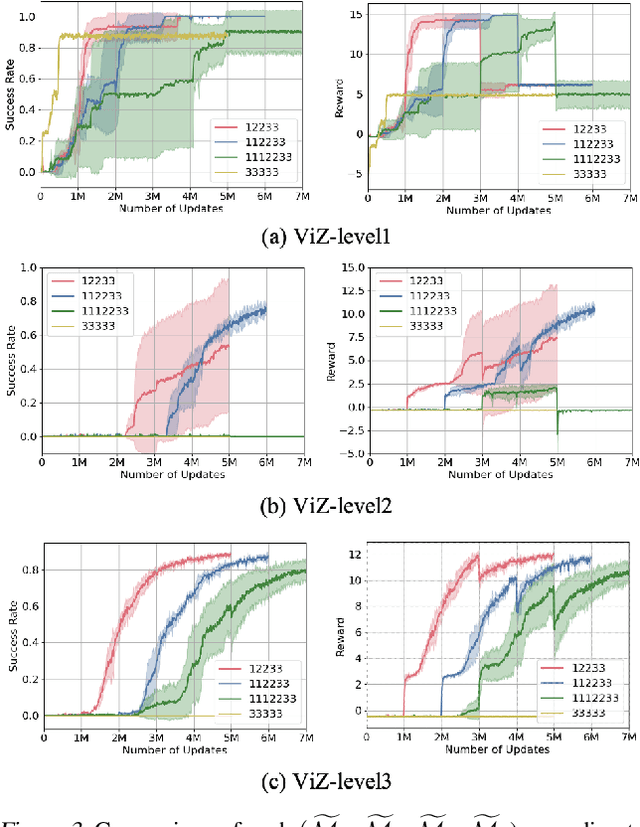
The initial years of an infant's life are known as the critical period, during which the overall development of learning performance is significantly impacted due to neural plasticity. In recent studies, an AI agent, with a deep neural network mimicking mechanisms of actual neurons, exhibited a learning period similar to human's critical period. Especially during this initial period, the appropriate stimuli play a vital role in developing learning ability. However, transforming human cognitive bias into an appropriate shaping reward is quite challenging, and prior works on critical period do not focus on finding the appropriate stimulus. To take a step further, we propose multi-stage reinforcement learning to emphasize finding ``appropriate stimulus" around the critical period. Inspired by humans' early cognitive-developmental stage, we use multi-stage guidance near the critical period, and demonstrate the appropriate shaping reward (stage-2 guidance) in terms of the AI agent's performance, efficiency, and stability.
Toddler-Guidance Learning: Impacts of Critical Period on Multimodal AI Agents
Jan 12, 2022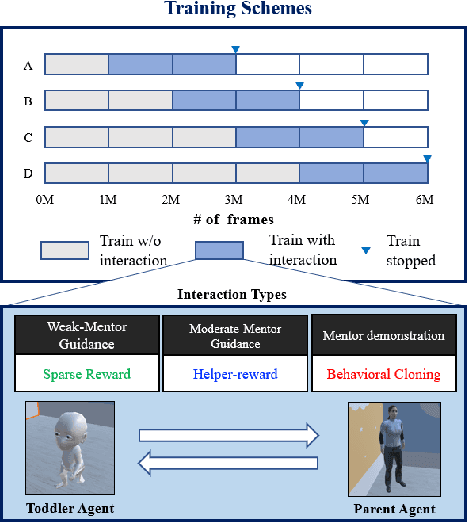

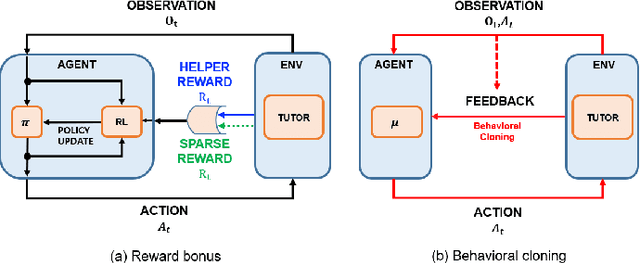
Critical periods are phases during which a toddler's brain develops in spurts. To promote children's cognitive development, proper guidance is critical in this stage. However, it is not clear whether such a critical period also exists for the training of AI agents. Similar to human toddlers, well-timed guidance and multimodal interactions might significantly enhance the training efficiency of AI agents as well. To validate this hypothesis, we adapt this notion of critical periods to learning in AI agents and investigate the critical period in the virtual environment for AI agents. We formalize the critical period and Toddler-guidance learning in the reinforcement learning (RL) framework. Then, we built up a toddler-like environment with VECA toolkit to mimic human toddlers' learning characteristics. We study three discrete levels of mutual interaction: weak-mentor guidance (sparse reward), moderate mentor guidance (helper-reward), and mentor demonstration (behavioral cloning). We also introduce the EAVE dataset consisting of 30,000 real-world images to fully reflect the toddler's viewpoint. We evaluate the impact of critical periods on AI agents from two perspectives: how and when they are guided best in both uni- and multimodal learning. Our experimental results show that both uni- and multimodal agents with moderate mentor guidance and critical period on 1 million and 2 million training steps show a noticeable improvement. We validate these results with transfer learning on the EAVE dataset and find the performance advancement on the same critical period and the guidance.
VECA : A Toolkit for Building Virtual Environments to Train and Test Human-like Agents
May 03, 2021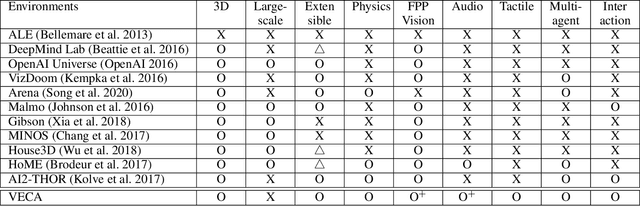
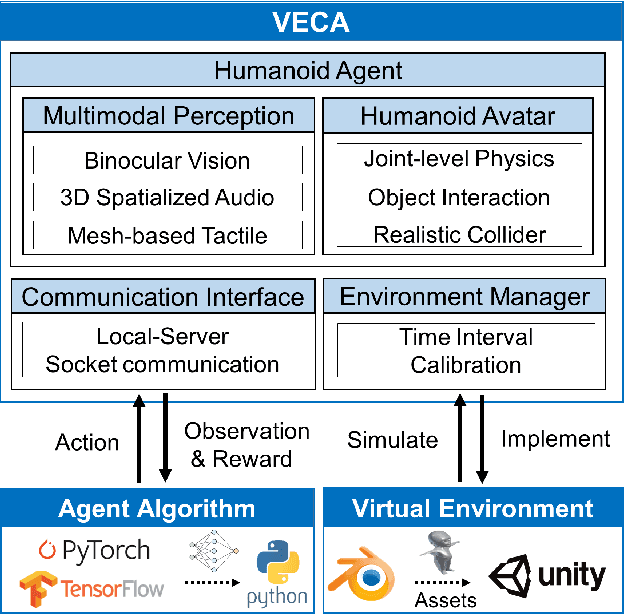


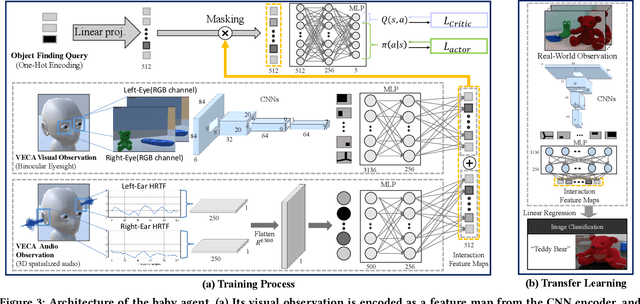
Building human-like agent, which aims to learn and think like human intelligence, has long been an important research topic in AI. To train and test human-like agents, we need an environment that imposes the agent to rich multimodal perception and allows comprehensive interactions for the agent, while also easily extensible to develop custom tasks. However, existing approaches do not support comprehensive interaction with the environment or lack variety in modalities. Also, most of the approaches are difficult or even impossible to implement custom tasks. In this paper, we propose a novel VR-based toolkit, VECA, which enables building fruitful virtual environments to train and test human-like agents. In particular, VECA provides a humanoid agent and an environment manager, enabling the agent to receive rich human-like perception and perform comprehensive interactions. To motivate VECA, we also provide 24 interactive tasks, which represent (but are not limited to) four essential aspects in early human development: joint-level locomotion and control, understanding contexts of objects, multimodal learning, and multi-agent learning. To show the usefulness of VECA on training and testing human-like learning agents, we conduct experiments on VECA and show that users can build challenging tasks for engaging human-like algorithms, and the features supported by VECA are critical on training human-like agents.
Learning task-agnostic representation via toddler-inspired learning
Jan 27, 2021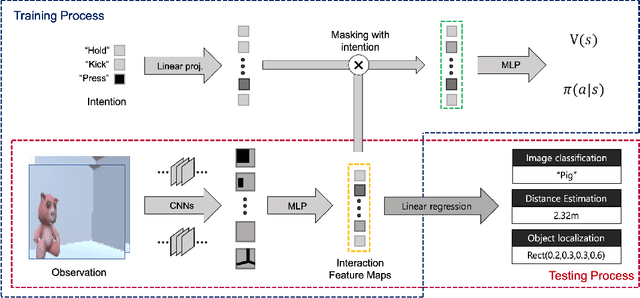


One of the inherent limitations of current AI systems, stemming from the passive learning mechanisms (e.g., supervised learning), is that they perform well on labeled datasets but cannot deduce knowledge on their own. To tackle this problem, we derive inspiration from a highly intentional learning system via action: the toddler. Inspired by the toddler's learning procedure, we design an interactive agent that can learn and store task-agnostic visual representation while exploring and interacting with objects in the virtual environment. Experimental results show that such obtained representation was expandable to various vision tasks such as image classification, object localization, and distance estimation tasks. In specific, the proposed model achieved 100%, 75.1% accuracy and 1.62% relative error, respectively, which is noticeably better than autoencoder-based model (99.7%, 66.1%, 1.95%), and also comparable with those of supervised models (100%, 87.3%, 0.71%).