 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUHR-DETR: Efficient End-to-End Small Object Detection for Ultra-High-Resolution Remote Sensing Imagery
Apr 23, 2026Ultra-High-Resolution (UHR) imagery has become essential for modern remote sensing, offering unprecedented spatial coverage. However, detecting small objects in such vast scenes presents a critical dilemma: retaining the original resolution for small objects causes prohibitive memory bottlenecks. Conversely, conventional compromises like image downsampling or patch cropping either erase small objects or destroy context. To break this dilemma, we propose UHR-DETR, an efficient end-to-end transformer-based detector designed for UHR imagery. First, we introduce a Coverage-Maximizing Sparse Encoder that dynamically allocates finite computational resources to informative high-resolution regions, ensuring maximum object coverage with minimal spatial redundancy. Second, we design a Global-Local Decoupled Decoder. By integrating macroscopic scene awareness with microscopic object details, this module resolves semantic ambiguities and prevents scene fragmentation. Extensive experiments on the UHR imagery datasets (e.g., STAR and SODA-A) demonstrate the superiority of UHR-DETR under strict hardware constraints (e.g., a single 24GB RTX 3090). It achieves a 2.8\% mAP improvement while delivering a 10$\times$ inference speedup compared to standard sliding-window baselines on the STAR dataset. Our codes and models will be available at https://github.com/Li-JingFang/UHR-DETR.
Pretraining A Large Language Model using Distributed GPUs: A Memory-Efficient Decentralized Paradigm
Feb 12, 2026Pretraining large language models (LLMs) typically requires centralized clusters with thousands of high-memory GPUs (e.g., H100/A100). Recent decentralized training methods reduce communication overhead by employing federated optimization; however, they still need to train the entire model on each node, remaining constrained by GPU memory limitations. In this work, we propose SParse Expert Synchronization (SPES), a memory-efficient decentralized framework for pretraining mixture-of-experts (MoE) LLMs. SPES trains only a subset of experts per node, substantially lowering the memory footprint. Each node updates its local experts and periodically synchronizes with other nodes, eliminating full-parameter transmission while ensuring efficient knowledge sharing. To accelerate convergence, we introduce an expert-merging warm-up strategy, where experts exchange knowledge early in training, to rapidly establish foundational capabilities. With SPES, we train a 2B-parameter MoE LLM using 16 standalone 48GB GPUs over internet connections, which achieves competitive performance with centrally trained LLMs under similar computational budgets. We further demonstrate scalability by training a 7B model from scratch and a 9B model upcycled from a dense checkpoint, both of which match prior centralized baselines. Our code is available at https://github.com/zjr2000/SPES.
Context Learning for Multi-Agent Discussion
Feb 02, 2026Multi-Agent Discussion (MAD) has garnered increasing attention very recently, where multiple LLM instances collaboratively solve problems via structured discussion. However, we find that current MAD methods easily suffer from discussion inconsistency, LLMs fail to reach a coherent solution, due to the misalignment between their individual contexts.In this paper, we introduce a multi-LLM context learning method (M2CL) that learns a context generator for each agent, capable of dynamically generating context instructions per discussion round via automatic information organization and refinement. Specifically, inspired by our theoretical insights on the context instruction, M2CL train the generators to control context coherence and output discrepancies via a carefully crafted self-adaptive mechanism.It enables LLMs to avoid premature convergence on majority noise and progressively reach the correct consensus. We evaluate M2CL on challenging tasks, including academic reasoning, embodied tasks, and mobile control. The results show that the performance of M2CL significantly surpasses existing methods by 20%--50%, while enjoying favorable transferability and computational efficiency.
MICo-150K: A Comprehensive Dataset Advancing Multi-Image Composition
Dec 08, 2025



In controllable image generation, synthesizing coherent and consistent images from multiple reference inputs, i.e., Multi-Image Composition (MICo), remains a challenging problem, partly hindered by the lack of high-quality training data. To bridge this gap, we conduct a systematic study of MICo, categorizing it into 7 representative tasks and curate a large-scale collection of high-quality source images and construct diverse MICo prompts. Leveraging powerful proprietary models, we synthesize a rich amount of balanced composite images, followed by human-in-the-loop filtering and refinement, resulting in MICo-150K, a comprehensive dataset for MICo with identity consistency. We further build a Decomposition-and-Recomposition (De&Re) subset, where 11K real-world complex images are decomposed into components and recomposed, enabling both real and synthetic compositions. To enable comprehensive evaluation, we construct MICo-Bench with 100 cases per task and 300 challenging De&Re cases, and further introduce a new metric, Weighted-Ref-VIEScore, specifically tailored for MICo evaluation. Finally, we fine-tune multiple models on MICo-150K and evaluate them on MICo-Bench. The results show that MICo-150K effectively equips models without MICo capability and further enhances those with existing skills. Notably, our baseline model, Qwen-MICo, fine-tuned from Qwen-Image-Edit, matches Qwen-Image-2509 in 3-image composition while supporting arbitrary multi-image inputs beyond the latter's limitation. Our dataset, benchmark, and baseline collectively offer valuable resources for further research on Multi-Image Composition.
$\mathcal{P}^3$: Toward Versatile Embodied Agents
Aug 09, 2025Embodied agents have shown promising generalization capabilities across diverse physical environments, making them essential for a wide range of real-world applications. However, building versatile embodied agents poses critical challenges due to three key issues: dynamic environment perception, open-ended tool usage, and complex multi-task planning. Most previous works rely solely on feedback from tool agents to perceive environmental changes and task status, which limits adaptability to real-time dynamics, causes error accumulation, and restricts tool flexibility. Furthermore, multi-task scheduling has received limited attention, primarily due to the inherent complexity of managing task dependencies and balancing competing priorities in dynamic and complex environments. To overcome these challenges, we introduce $\mathcal{P}^3$, a unified framework that integrates real-time perception and dynamic scheduling. Specifically, $\mathcal{P}^3$ enables 1) \textbf Perceive relevant task information actively from the environment, 2) \textbf Plug and utilize any tool without feedback requirement, and 3) \textbf Plan multi-task execution based on prioritizing urgent tasks and dynamically adjusting task order based on dependencies. Extensive real-world experiments show that our approach bridges the gap between benchmarks and practical deployment, delivering highly transferable, general-purpose embodied agents. Code and data will be released soon.
Learning Speaker-Invariant Visual Features for Lipreading
Jun 09, 2025Lipreading is a challenging cross-modal task that aims to convert visual lip movements into spoken text. Existing lipreading methods often extract visual features that include speaker-specific lip attributes (e.g., shape, color, texture), which introduce spurious correlations between vision and text. These correlations lead to suboptimal lipreading accuracy and restrict model generalization. To address this challenge, we introduce SIFLip, a speaker-invariant visual feature learning framework that disentangles speaker-specific attributes using two complementary disentanglement modules (Implicit Disentanglement and Explicit Disentanglement) to improve generalization. Specifically, since different speakers exhibit semantic consistency between lip movements and phonetic text when pronouncing the same words, our implicit disentanglement module leverages stable text embeddings as supervisory signals to learn common visual representations across speakers, implicitly decoupling speaker-specific features. Additionally, we design a speaker recognition sub-task within the main lipreading pipeline to filter speaker-specific features, then further explicitly disentangle these personalized visual features from the backbone network via gradient reversal. Experimental results demonstrate that SIFLip significantly enhances generalization performance across multiple public datasets. Experimental results demonstrate that SIFLip significantly improves generalization performance across multiple public datasets, outperforming state-of-the-art methods.
$γ$-FedHT: Stepsize-Aware Hard-Threshold Gradient Compression in Federated Learning
May 18, 2025Gradient compression can effectively alleviate communication bottlenecks in Federated Learning (FL). Contemporary state-of-the-art sparse compressors, such as Top-$k$, exhibit high computational complexity, up to $\mathcal{O}(d\log_2{k})$, where $d$ is the number of model parameters. The hard-threshold compressor, which simply transmits elements with absolute values higher than a fixed threshold, is thus proposed to reduce the complexity to $\mathcal{O}(d)$. However, the hard-threshold compression causes accuracy degradation in FL, where the datasets are non-IID and the stepsize $\gamma$ is decreasing for model convergence. The decaying stepsize reduces the updates and causes the compression ratio of the hard-threshold compression to drop rapidly to an aggressive ratio. At or below this ratio, the model accuracy has been observed to degrade severely. To address this, we propose $\gamma$-FedHT, a stepsize-aware low-cost compressor with Error-Feedback to guarantee convergence. Given that the traditional theoretical framework of FL does not consider Error-Feedback, we introduce the fundamental conversation of Error-Feedback. We prove that $\gamma$-FedHT has the convergence rate of $\mathcal{O}(\frac{1}{T})$ ($T$ representing total training iterations) under $\mu$-strongly convex cases and $\mathcal{O}(\frac{1}{\sqrt{T}})$ under non-convex cases, \textit{same as FedAVG}. Extensive experiments demonstrate that $\gamma$-FedHT improves accuracy by up to $7.42\%$ over Top-$k$ under equal communication traffic on various non-IID image datasets.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
Nov 29, 2024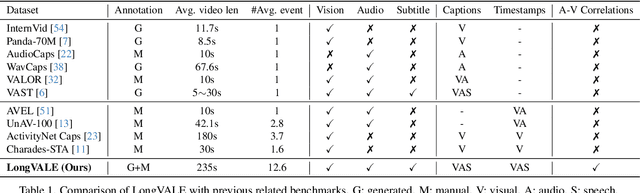
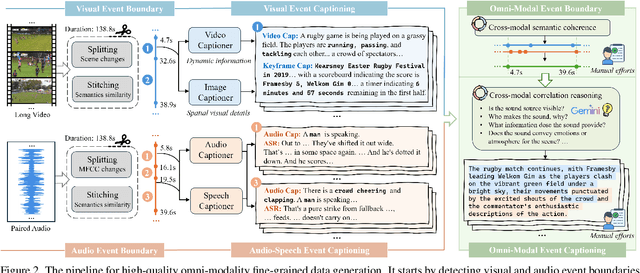
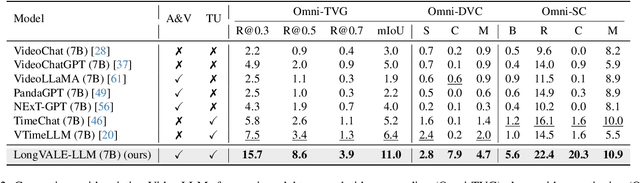
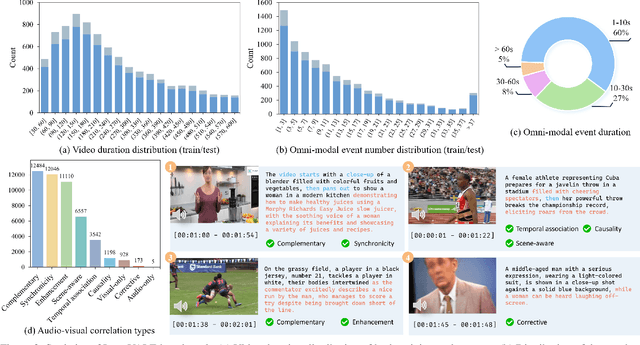
Despite impressive advancements in video understanding, most efforts remain limited to coarse-grained or visual-only video tasks. However, real-world videos encompass omni-modal information (vision, audio, and speech) with a series of events forming a cohesive storyline. The lack of multi-modal video data with fine-grained event annotations and the high cost of manual labeling are major obstacles to comprehensive omni-modality video perception. To address this gap, we propose an automatic pipeline consisting of high-quality multi-modal video filtering, semantically coherent omni-modal event boundary detection, and cross-modal correlation-aware event captioning. In this way, we present LongVALE, the first-ever Vision-Audio-Language Event understanding benchmark comprising 105K omni-modal events with precise temporal boundaries and detailed relation-aware captions within 8.4K high-quality long videos. Further, we build a baseline that leverages LongVALE to enable video large language models (LLMs) for omni-modality fine-grained temporal video understanding for the first time. Extensive experiments demonstrate the effectiveness and great potential of LongVALE in advancing comprehensive multi-modal video understanding.
Differential Informed Auto-Encoder
Oct 24, 2024In this article, an encoder was trained to obtain the inner structure of the original data by obtain a differential equations. A decoder was trained to resample the original data domain, to generate new data that obey the differential structure of the original data using the physics-informed neural network.