 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPCB: A Unified Vision-Language Benchmark for Open-Ended PCB Quality Inspection
Jan 27, 2026Multimodal Large Language Models (MLLMs) show promise for general industrial quality inspection, but fall short in complex scenarios, such as Printed Circuit Board (PCB) inspection. PCB inspection poses unique challenges due to densely packed components, complex wiring structures, and subtle defect patterns that require specialized domain expertise. However, a high-quality, unified vision-language benchmark for quantitatively evaluating MLLMs across PCB inspection tasks remains absent, stemming not only from limited data availability but also from fragmented datasets and inconsistent standardization. To fill this gap, we propose UniPCB, the first unified vision-language benchmark for open-ended PCB quality inspection. UniPCB is built via a systematic pipeline that curates and standardizes data from disparate sources across three annotated scenarios. Furthermore, we introduce PCB-GPT, an MLLM trained on a new instruction dataset generated by this pipeline, utilizing a novel progressive curriculum that mimics the learning process of human experts. Evaluations on the UniPCB benchmark show that while existing MLLMs falter on domain-specific tasks, PCB-GPT establishes a new baseline. Notably, it more than doubles the performance on fine-grained defect localization compared to the strongest competitors, with significant advantages in localization and analysis. We will release the instruction data, benchmark, and model to facilitate future research.
Reflective Instruction Tuning: Mitigating Hallucinations in Large Vision-Language Models
Jul 16, 2024

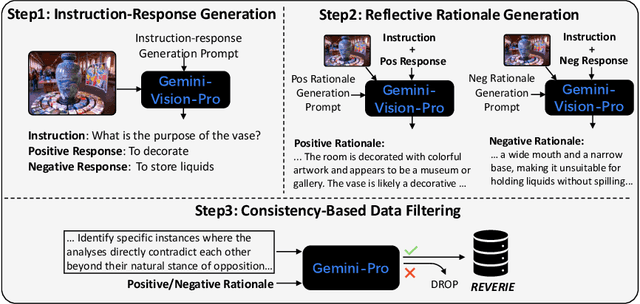

Large vision-language models (LVLMs) have shown promising performance on a variety of vision-language tasks. However, they remain susceptible to hallucinations, generating outputs misaligned with visual content or instructions. While various mitigation strategies have been proposed, they often neglect a key contributor to hallucinations: lack of fine-grained reasoning supervision during training. Without intermediate reasoning steps, models may establish superficial shortcuts between instructions and responses, failing to internalize the inherent reasoning logic. To address this challenge, we propose reflective instruction tuning, which integrates rationale learning into visual instruction tuning. Unlike previous methods that learning from responses only, our approach entails the model predicting rationales justifying why responses are correct or incorrect. This fosters a deeper engagement with the fine-grained reasoning underlying each response, thus enhancing the model's reasoning proficiency. To facilitate this approach, we propose REVERIE, the first large-scale instruction-tuning dataset with ReflEctiVE RatIonalE annotations. REVERIE comprises 115k machine-generated reasoning instructions, each meticulously annotated with a corresponding pair of correct and confusing responses, alongside comprehensive rationales elucidating the justification behind the correctness or erroneousness of each response. Experimental results on multiple LVLM benchmarks reveal that reflective instruction tuning with the REVERIE dataset yields noticeable performance gain over the baseline model, demonstrating the effectiveness of reflecting from the rationales. Project page is at https://zjr2000.github.io/projects/reverie.