 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistentRFT: Reducing Visual Hallucinations in Flow-based Reinforcement Fine-Tuning
Feb 03, 2026Reinforcement Fine-Tuning (RFT) on flow-based models is crucial for preference alignment. However, they often introduce visual hallucinations like over-optimized details and semantic misalignment. This work preliminarily explores why visual hallucinations arise and how to reduce them. We first investigate RFT methods from a unified perspective, and reveal the core problems stemming from two aspects, exploration and exploitation: (1) limited exploration during stochastic differential equation (SDE) rollouts, leading to an over-emphasis on local details at the expense of global semantics, and (2) trajectory imitation process inherent in policy gradient methods, distorting the model's foundational vector field and its cross-step consistency. Building on this, we propose ConsistentRFT, a general framework to mitigate these hallucinations. Specifically, we design a Dynamic Granularity Rollout (DGR) mechanism to balance exploration between global semantics and local details by dynamically scheduling different noise sources. We then introduce a Consistent Policy Gradient Optimization (CPGO) that preserves the model's consistency by aligning the current policy with a more stable prior. Extensive experiments demonstrate that ConsistentRFT significantly mitigates visual hallucinations, achieving average reductions of 49\% for low-level and 38\% for high-level perceptual hallucinations. Furthermore, ConsistentRFT outperforms other RFT methods on out-of-domain metrics, showing an improvement of 5.1\% (v.s. the baseline's decrease of -0.4\%) over FLUX1.dev. This is \href{https://xiaofeng-tan.github.io/projects/ConsistentRFT}{Project Page}.
UniPCB: A Unified Vision-Language Benchmark for Open-Ended PCB Quality Inspection
Jan 27, 2026Multimodal Large Language Models (MLLMs) show promise for general industrial quality inspection, but fall short in complex scenarios, such as Printed Circuit Board (PCB) inspection. PCB inspection poses unique challenges due to densely packed components, complex wiring structures, and subtle defect patterns that require specialized domain expertise. However, a high-quality, unified vision-language benchmark for quantitatively evaluating MLLMs across PCB inspection tasks remains absent, stemming not only from limited data availability but also from fragmented datasets and inconsistent standardization. To fill this gap, we propose UniPCB, the first unified vision-language benchmark for open-ended PCB quality inspection. UniPCB is built via a systematic pipeline that curates and standardizes data from disparate sources across three annotated scenarios. Furthermore, we introduce PCB-GPT, an MLLM trained on a new instruction dataset generated by this pipeline, utilizing a novel progressive curriculum that mimics the learning process of human experts. Evaluations on the UniPCB benchmark show that while existing MLLMs falter on domain-specific tasks, PCB-GPT establishes a new baseline. Notably, it more than doubles the performance on fine-grained defect localization compared to the strongest competitors, with significant advantages in localization and analysis. We will release the instruction data, benchmark, and model to facilitate future research.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
SoftPatch+: Fully Unsupervised Anomaly Classification and Segmentation
Dec 30, 2024



Although mainstream unsupervised anomaly detection (AD) (including image-level classification and pixel-level segmentation)algorithms perform well in academic datasets, their performance is limited in practical application due to the ideal experimental setting of clean training data. Training with noisy data is an inevitable problem in real-world anomaly detection but is seldom discussed. This paper is the first to consider fully unsupervised industrial anomaly detection (i.e., unsupervised AD with noisy data). To solve this problem, we proposed memory-based unsupervised AD methods, SoftPatch and SoftPatch+, which efficiently denoise the data at the patch level. Noise discriminators are utilized to generate outlier scores for patch-level noise elimination before coreset construction. The scores are then stored in the memory bank to soften the anomaly detection boundary. Compared with existing methods, SoftPatch maintains a strong modeling ability of normal data and alleviates the overconfidence problem in coreset, and SoftPatch+ has more robust performance which is articularly useful in real-world industrial inspection scenarios with high levels of noise (from 10% to 40%). Comprehensive experiments conducted in diverse noise scenarios demonstrate that both SoftPatch and SoftPatch+ outperform the state-of-the-art AD methods on the MVTecAD, ViSA, and BTAD benchmarks. Furthermore, the performance of SoftPatch and SoftPatch+ is comparable to that of the noise-free methods in conventional unsupervised AD setting. The code of the proposed methods can be found at https://github.com/TencentYoutuResearch/AnomalyDetection-SoftPatch.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
MMAD: The First-Ever Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
Oct 12, 2024



In the field of industrial inspection, Multimodal Large Language Models (MLLMs) have a high potential to renew the paradigms in practical applications due to their robust language capabilities and generalization abilities. However, despite their impressive problem-solving skills in many domains, MLLMs' ability in industrial anomaly detection has not been systematically studied. To bridge this gap, we present MMAD, the first-ever full-spectrum MLLMs benchmark in industrial Anomaly Detection. We defined seven key subtasks of MLLMs in industrial inspection and designed a novel pipeline to generate the MMAD dataset with 39,672 questions for 8,366 industrial images. With MMAD, we have conducted a comprehensive, quantitative evaluation of various state-of-the-art MLLMs. The commercial models performed the best, with the average accuracy of GPT-4o models reaching 74.9%. However, this result falls far short of industrial requirements. Our analysis reveals that current MLLMs still have significant room for improvement in answering questions related to industrial anomalies and defects. We further explore two training-free performance enhancement strategies to help models improve in industrial scenarios, highlighting their promising potential for future research.
SwiftQueue: Optimizing Low-Latency Applications with Swift Packet Queuing
Oct 08, 2024



Low Latency, Low Loss, and Scalable Throughput (L4S), as an emerging router-queue management technique, has seen steady deployment in the industry. An L4S-enabled router assigns each packet to the queue based on the packet header marking. Currently, L4S employs per-flow queue selection, i.e. all packets of a flow are marked the same way and thus use the same queues, even though each packet is marked separately. However, this may hurt tail latency and latency-sensitive applications because transient congestion and queue buildups may only affect a fraction of packets in a flow. We present SwiftQueue, a new L4S queue-selection strategy in which a sender uses a novel per-packet latency predictor to pinpoint which packets likely have latency spikes or drops. The insight is that many packet-level latency variations result from complex interactions among recent packets at shared router queues. Yet, these intricate packet-level latency patterns are hard to learn efficiently by traditional models. Instead, SwiftQueue uses a custom Transformer, which is well-studied for its expressiveness on sequential patterns, to predict the next packet's latency based on the latencies of recently received ACKs. Based on the predicted latency of each outgoing packet, SwiftQueue's sender dynamically marks the L4S packet header to assign packets to potentially different queues, even within the same flow. Using real network traces, we show that SwiftQueue is 45-65% more accurate in predicting latency and its variations than state-of-art methods. Based on its latency prediction, SwiftQueue reduces the tail latency for L4S-enabled flows by 36-45%, compared with the existing L4S queue-selection method.
CAR: Controllable Autoregressive Modeling for Visual Generation
Oct 07, 2024



Controllable generation, which enables fine-grained control over generated outputs, has emerged as a critical focus in visual generative models. Currently, there are two primary technical approaches in visual generation: diffusion models and autoregressive models. Diffusion models, as exemplified by ControlNet and T2I-Adapter, offer advanced control mechanisms, whereas autoregressive models, despite showcasing impressive generative quality and scalability, remain underexplored in terms of controllability and flexibility. In this study, we introduce Controllable AutoRegressive Modeling (CAR), a novel, plug-and-play framework that integrates conditional control into multi-scale latent variable modeling, enabling efficient control generation within a pre-trained visual autoregressive model. CAR progressively refines and captures control representations, which are injected into each autoregressive step of the pre-trained model to guide the generation process. Our approach demonstrates excellent controllability across various types of conditions and delivers higher image quality compared to previous methods. Additionally, CAR achieves robust generalization with significantly fewer training resources compared to those required for pre-training the model. To the best of our knowledge, we are the first to propose a control framework for pre-trained autoregressive visual generation models.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024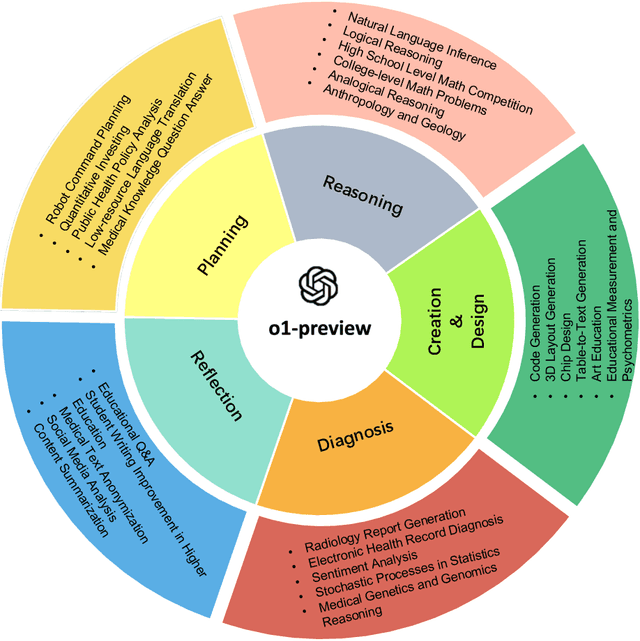


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Identifying Influential nodes in Brain Networks via Self-Supervised Graph-Transformer
Sep 17, 2024


Studying influential nodes (I-nodes) in brain networks is of great significance in the field of brain imaging. Most existing studies consider brain connectivity hubs as I-nodes. However, this approach relies heavily on prior knowledge from graph theory, which may overlook the intrinsic characteristics of the brain network, especially when its architecture is not fully understood. In contrast, self-supervised deep learning can learn meaningful representations directly from the data. This approach enables the exploration of I-nodes for brain networks, which is also lacking in current studies. This paper proposes a Self-Supervised Graph Reconstruction framework based on Graph-Transformer (SSGR-GT) to identify I-nodes, which has three main characteristics. First, as a self-supervised model, SSGR-GT extracts the importance of brain nodes to the reconstruction. Second, SSGR-GT uses Graph-Transformer, which is well-suited for extracting features from brain graphs, combining both local and global characteristics. Third, multimodal analysis of I-nodes uses graph-based fusion technology, combining functional and structural brain information. The I-nodes we obtained are distributed in critical areas such as the superior frontal lobe, lateral parietal lobe, and lateral occipital lobe, with a total of 56 identified across different experiments. These I-nodes are involved in more brain networks than other regions, have longer fiber connections, and occupy more central positions in structural connectivity. They also exhibit strong connectivity and high node efficiency in both functional and structural networks. Furthermore, there is a significant overlap between the I-nodes and both the structural and functional rich-club. These findings enhance our understanding of the I-nodes within the brain network, and provide new insights for future research in further understanding the brain working mechanisms.