 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring, Localizing, and Ablating Alignment Signatures in LLMs
May 28, 2026Aligned language models often exhibit a recognizable AI-like style, yet its connection to post-training and internal representations remains poorly understood. In this work, we study whether post-training introduces or amplifies AI-like stylistic regularities and whether these regularities have a localized internal signature. To this end, we compare human text, base-model generations, and aligned-model generations under matched human-source prefixes. Aligned generations show lower human-corpus affinity and higher AI-detection rates than base generations, suggesting that post-training shifts generated text away from human-corpus style and toward detector-visible AI-like text. We then introduce PASTA (Post-training Alignment Signature Targeted Ablation), a training-free method that estimates a post-training alignment signature from aligned-base residual contrasts and ablates the corresponding direction during decoding. Across 11 aligned models and 6 AI detectors, PASTA lowers the detection rate for most aligned models; this effect transfers well across detectors and is not reproduced by random directions. Qualitative analysis suggests that PASTA generations remain relevant and coherent while exhibiting greater stylistic variation. Together, these results show that AI-like stylistic effects of post-training can be measured, localized, and causally tested through activation ablation.
Algorithmic Data Minimization for Machine Learning over Internet-of-Things Data Streams
Mar 07, 2025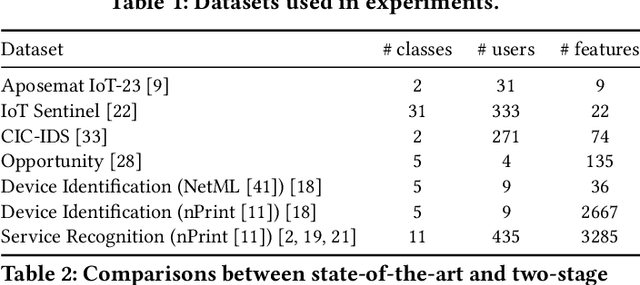
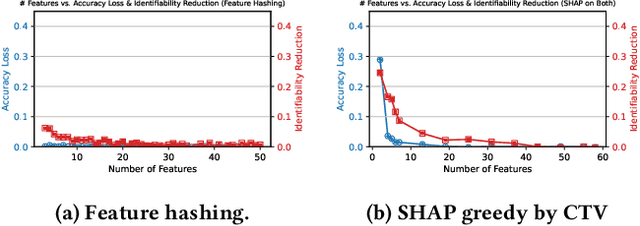
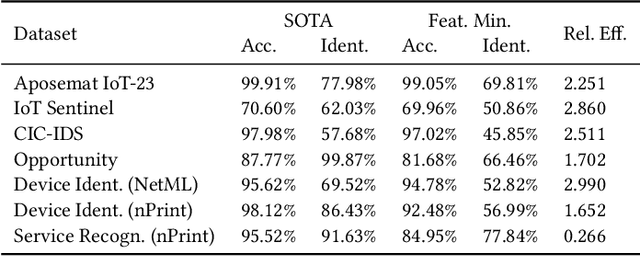
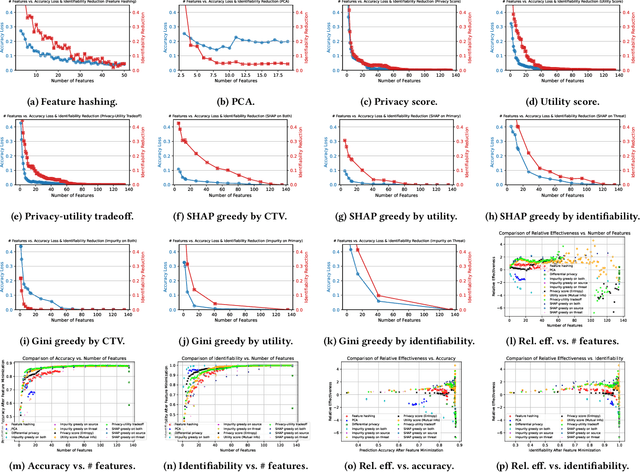
Machine learning can analyze vast amounts of data generated by IoT devices to identify patterns, make predictions, and enable real-time decision-making. By processing sensor data, machine learning models can optimize processes, improve efficiency, and enhance personalized user experiences in smart systems. However, IoT systems are often deployed in sensitive environments such as households and offices, where they may inadvertently expose identifiable information, including location, habits, and personal identifiers. This raises significant privacy concerns, necessitating the application of data minimization -- a foundational principle in emerging data regulations, which mandates that service providers only collect data that is directly relevant and necessary for a specified purpose. Despite its importance, data minimization lacks a precise technical definition in the context of sensor data, where collections of weak signals make it challenging to apply a binary "relevant and necessary" rule. This paper provides a technical interpretation of data minimization in the context of sensor streams, explores practical methods for implementation, and addresses the challenges involved. Through our approach, we demonstrate that our framework can reduce user identifiability by up to 16.7% while maintaining accuracy loss below 1%, offering a viable path toward privacy-preserving IoT data processing.
Generative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.
MYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.
SwiftQueue: Optimizing Low-Latency Applications with Swift Packet Queuing
Oct 08, 2024



Low Latency, Low Loss, and Scalable Throughput (L4S), as an emerging router-queue management technique, has seen steady deployment in the industry. An L4S-enabled router assigns each packet to the queue based on the packet header marking. Currently, L4S employs per-flow queue selection, i.e. all packets of a flow are marked the same way and thus use the same queues, even though each packet is marked separately. However, this may hurt tail latency and latency-sensitive applications because transient congestion and queue buildups may only affect a fraction of packets in a flow. We present SwiftQueue, a new L4S queue-selection strategy in which a sender uses a novel per-packet latency predictor to pinpoint which packets likely have latency spikes or drops. The insight is that many packet-level latency variations result from complex interactions among recent packets at shared router queues. Yet, these intricate packet-level latency patterns are hard to learn efficiently by traditional models. Instead, SwiftQueue uses a custom Transformer, which is well-studied for its expressiveness on sequential patterns, to predict the next packet's latency based on the latencies of recently received ACKs. Based on the predicted latency of each outgoing packet, SwiftQueue's sender dynamically marks the L4S packet header to assign packets to potentially different queues, even within the same flow. Using real network traces, we show that SwiftQueue is 45-65% more accurate in predicting latency and its variations than state-of-art methods. Based on its latency prediction, SwiftQueue reduces the tail latency for L4S-enabled flows by 36-45%, compared with the existing L4S queue-selection method.
ServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis
Feb 06, 2024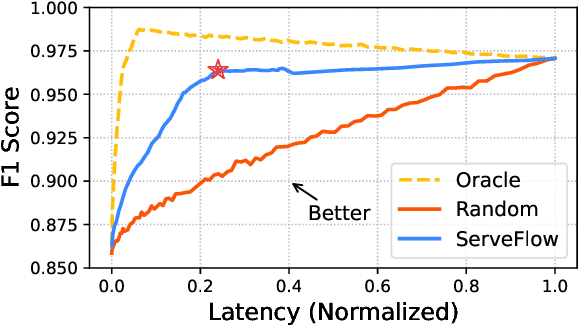
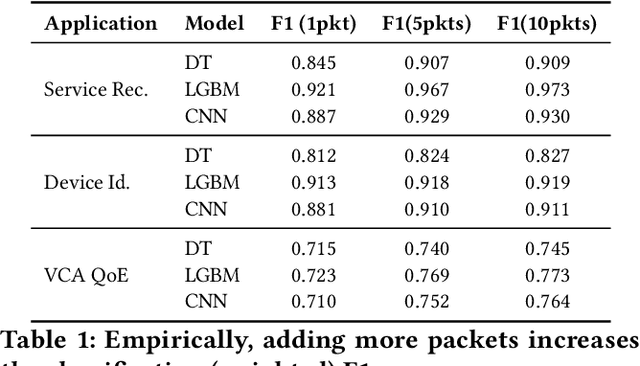
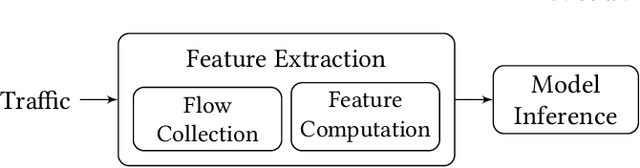
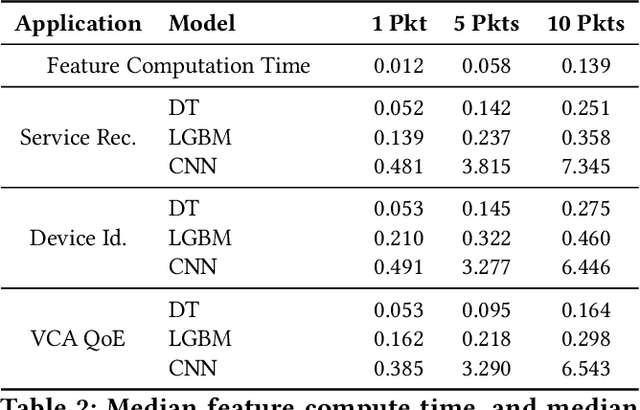
Network traffic analysis increasingly uses complex machine learning models as the internet consolidates and traffic gets more encrypted. However, over high-bandwidth networks, flows can easily arrive faster than model inference rates. The temporal nature of network flows limits simple scale-out approaches leveraged in other high-traffic machine learning applications. Accordingly, this paper presents ServeFlow, a solution for machine-learning model serving aimed at network traffic analysis tasks, which carefully selects the number of packets to collect and the models to apply for individual flows to achieve a balance between minimal latency, high service rate, and high accuracy. We identify that on the same task, inference time across models can differ by 2.7x-136.3x, while the median inter-packet waiting time is often 6-8 orders of magnitude higher than the inference time! ServeFlow is able to make inferences on 76.3% flows in under 16ms, which is a speed-up of 40.5x on the median end-to-end serving latency while increasing the service rate and maintaining similar accuracy. Even with thousands of features per flow, it achieves a service rate of over 48.5k new flows per second on a 16-core CPU commodity server, which matches the order of magnitude of flow rates observed on city-level network backbones.
Grace++: Loss-Resilient Real-Time Video Communication under High Network Latency
May 21, 2023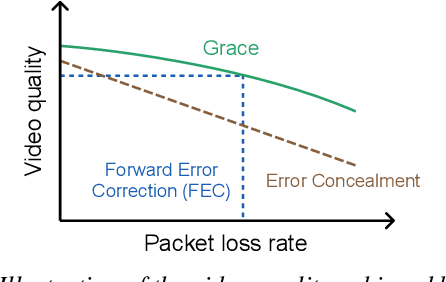
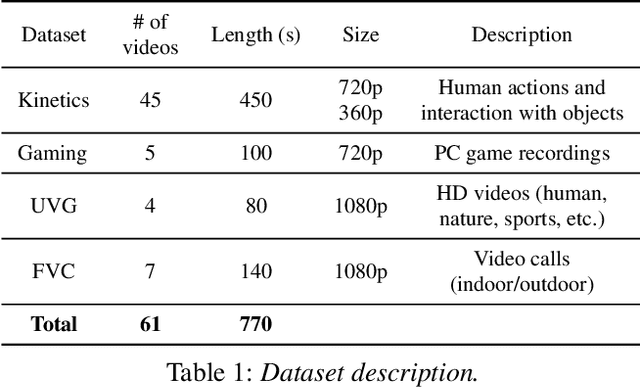
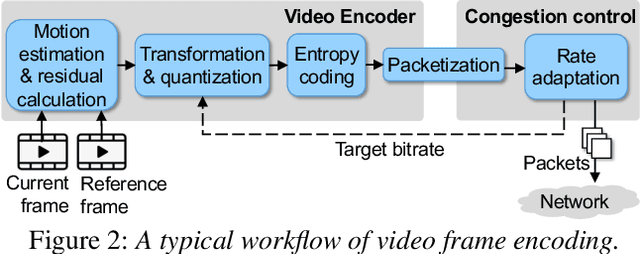

In real-time videos, resending any packets, especially in networks with high latency, can lead to stuttering, poor video quality, and user frustration. Despite extensive research, current real-time video systems still use redundancy to handle packet loss, thus compromising on quality in the the absence of packet loss. Since predicting packet loss is challenging, these systems only enhance their resilience to packet loss after it occurs, leaving some frames insufficiently protected against burst packet losses. They may also add too much redundancy even after the packet loss has subsided. We present Grace++, a new real-time video communication system. With Grace++, (i) a video frame can be decoded, as long as any non-empty subset of its packets are received, and (ii) the quality gracefully degrades as more packets are lost, and (iii) approximates that of a standard codec (like H.265) in absence of packet loss. To achieve this, Grace++ encodes and decodes frames by using neural networks (NNs). It uses a new packetization scheme that makes packet loss appear to have the same effect as randomly masking (zeroing) a subset of elements in the NN-encoded output, and the NN encoder and decoder are specially trained to achieve decent quality if a random subset of elements in the NN-encoded output are masked. Using various test videos and real network traces, we show that the quality of Grace++ is slightly lower than H.265 when no packets are lost, but significantly reduces the 95th percentile of frame delay (between encoding a frame and its decoding) by 2x when packet loss occurs compared to other loss-resilient schemes while achieving comparable quality. This is because Grace++ does not require retransmission of packets (unless all packets are lost) or skipping of frames.
Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
Feb 03, 2023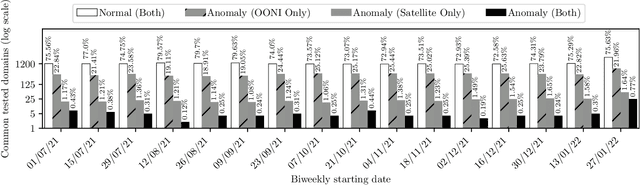
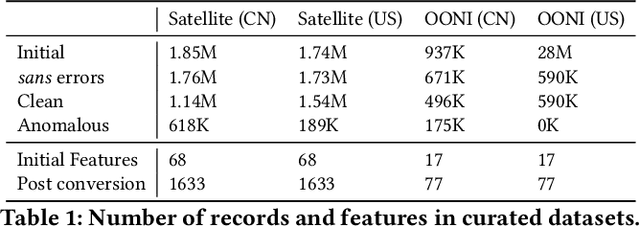
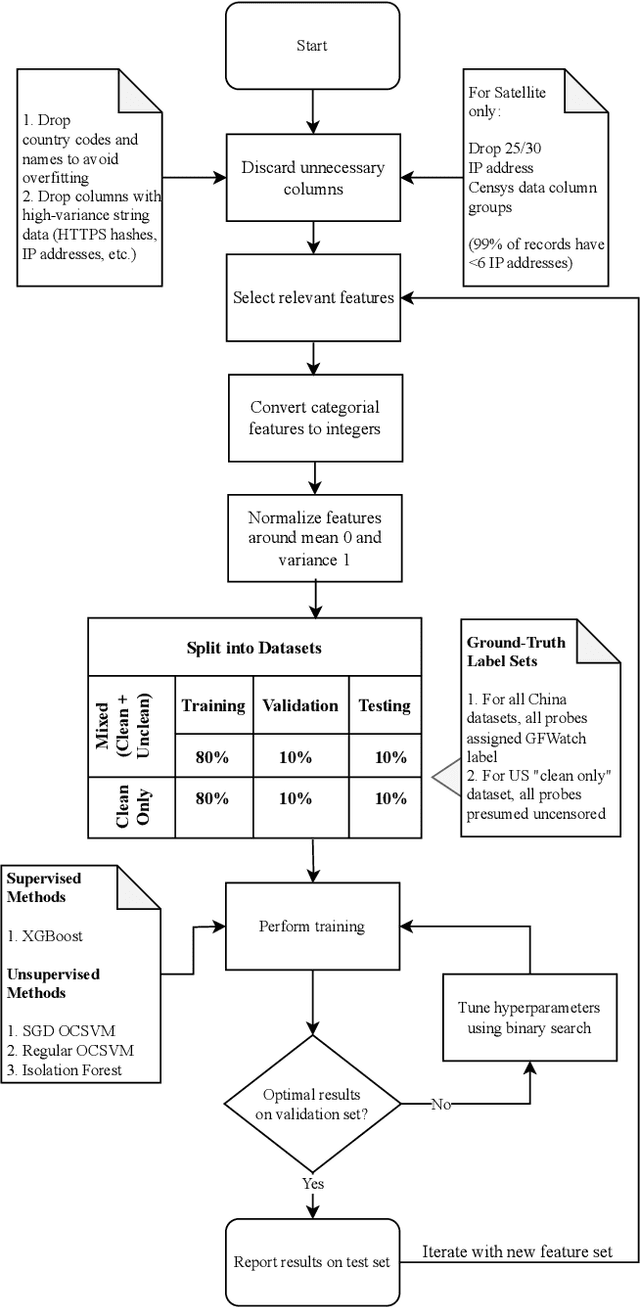
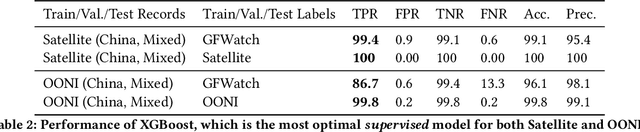
The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship. In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.
Understanding Model Drift in a Large Cellular Network
Sep 07, 2021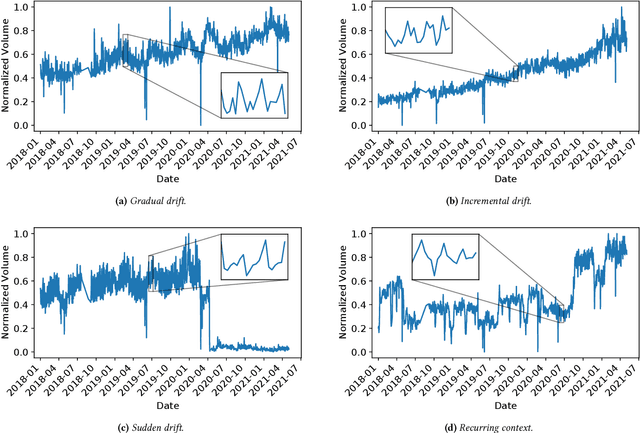


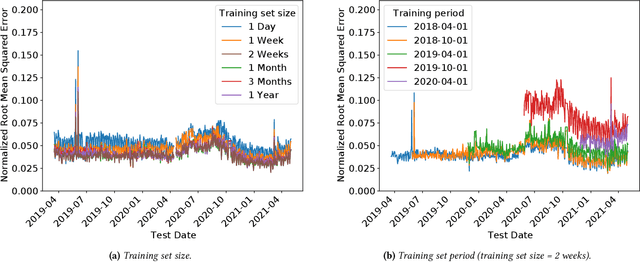
Operational networks are increasingly using machine learning models for a variety of tasks, including detecting anomalies, inferring application performance, and forecasting demand. Accurate models are important, yet accuracy can degrade over time due to concept drift, whereby either the characteristics of the data change over time (data drift) or the relationship between the features and the target predictor change over time (model drift). Drift is important to detect because changes in properties of the underlying data or relationships to the target prediction can require model retraining, which can be time-consuming and expensive. Concept drift occurs in operational networks for a variety of reasons, ranging from software upgrades to seasonality to changes in user behavior. Yet, despite the prevalence of drift in networks, its extent and effects on prediction accuracy have not been extensively studied. This paper presents an initial exploration into concept drift in a large cellular network in the United States for a major metropolitan area in the context of demand forecasting. We find that concept drift arises largely due to data drift, and it appears across different key performance indicators (KPIs), models, training set sizes, and time intervals. We identify the sources of concept drift for the particular problem of forecasting downlink volume. Weekly and seasonal patterns introduce both high and low-frequency model drift, while disasters and upgrades result in sudden drift due to exogenous shocks. Regions with high population density, lower traffic volumes, and higher speeds also tend to correlate with more concept drift. The features that contribute most significantly to concept drift are User Equipment (UE) downlink packets, UE uplink packets, and Real-time Transport Protocol (RTP) total received packets.
An Efficient One-Class SVM for Anomaly Detection in the Internet of Things
Apr 22, 2021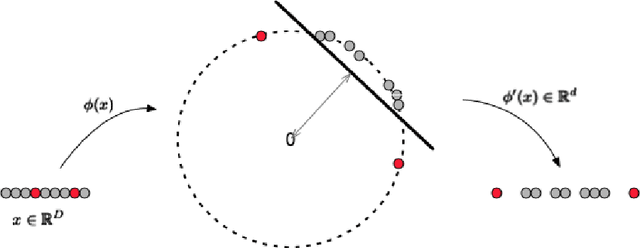
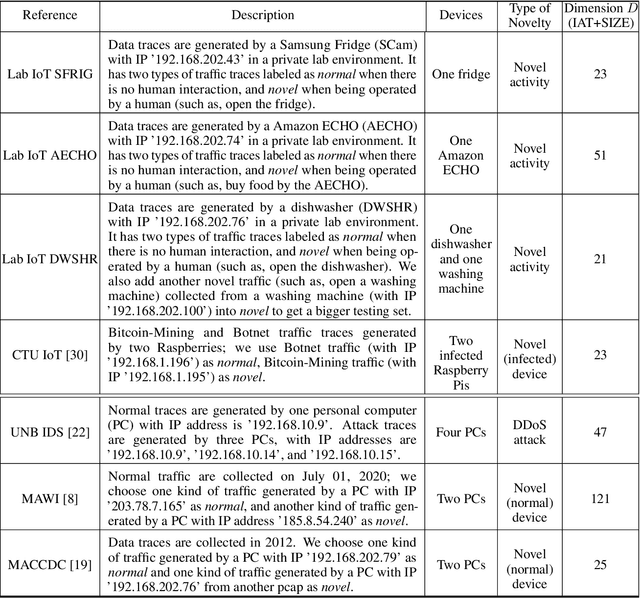

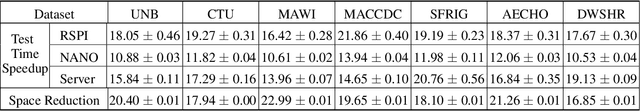
Insecure Internet of things (IoT) devices pose significant threats to critical infrastructure and the Internet at large; detecting anomalous behavior from these devices remains of critical importance, but fast, efficient, accurate anomaly detection (also called "novelty detection") for these classes of devices remains elusive. One-Class Support Vector Machines (OCSVM) are one of the state-of-the-art approaches for novelty detection (or anomaly detection) in machine learning, due to their flexibility in fitting complex nonlinear boundaries between {normal} and {novel} data. IoT devices in smart homes and cities and connected building infrastructure present a compelling use case for novelty detection with OCSVM due to the variety of devices, traffic patterns, and types of anomalies that can manifest in such environments. Much previous research has thus applied OCSVM to novelty detection for IoT. Unfortunately, conventional OCSVMs introduce significant memory requirements and are computationally expensive at prediction time as the size of the train set grows, requiring space and time that scales with the number of training points. These memory and computational constraints can be prohibitive in practical, real-world deployments, where large training sets are typically needed to develop accurate models when fitting complex decision boundaries. In this work, we extend so-called Nystr\"om and (Gaussian) Sketching approaches to OCSVM, by combining these methods with clustering and Gaussian mixture models to achieve significant speedups in prediction time and space in various IoT settings, without sacrificing detection accuracy.