 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
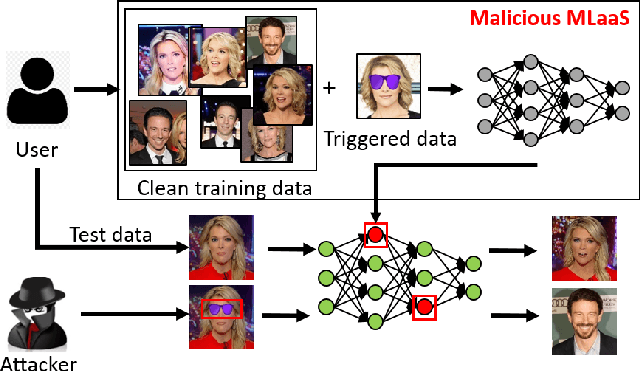

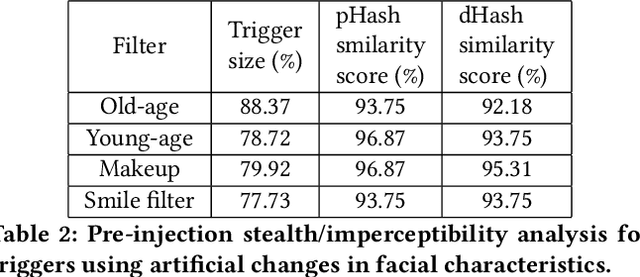
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.