 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTMAlis: Towards Latency-Critical Mobile Video Analytics with Vision Transformers
Jan 29, 2026Edge-assisted mobile video analytics (MVA) applications are increasingly shifting from using vision models based on convolutional neural networks (CNNs) to those built on vision transformers (ViTs) to leverage their superior global context modeling and generalization capabilities. However, deploying these advanced models in latency-critical MVA scenarios presents significant challenges. Unlike traditional CNN-based offloading paradigms where network transmission is the primary bottleneck, ViT-based systems are constrained by substantial inference delays, particularly for dense prediction tasks where the need for high-resolution inputs exacerbates the inherent quadratic computational complexity of ViTs. To address these challenges, we propose a dynamic mixed-resolution inference strategy tailored for ViT-backboned dense prediction models, enabling flexible runtime trade-offs between speed and accuracy. Building on this, we introduce ViTMAlis, a ViT-native device-to-edge offloading framework that dynamically adapts to network conditions and video content to jointly reduce transmission and inference delays. We implement a fully functional prototype of ViTMAlis on commodity mobile and edge devices. Extensive experiments demonstrate that, compared to state-of-the-art accuracy-centric, content-aware, and latency-adaptive baselines, ViTMAlis significantly reduces end-to-end offloading latency while improving user-perceived rendering accuracy, providing a practical foundation for next-generation mobile intelligence.
CornerPoint3D: Look at the Nearest Corner Instead of the Center
Apr 03, 2025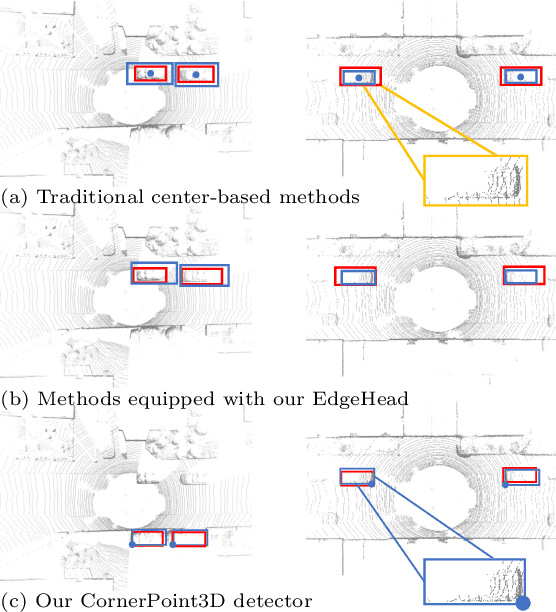
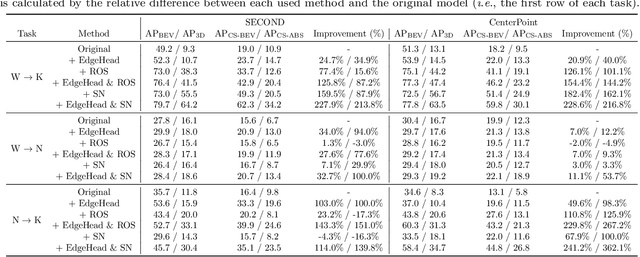
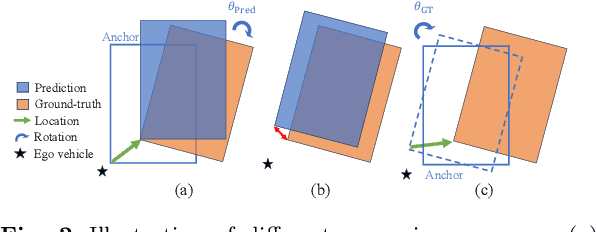
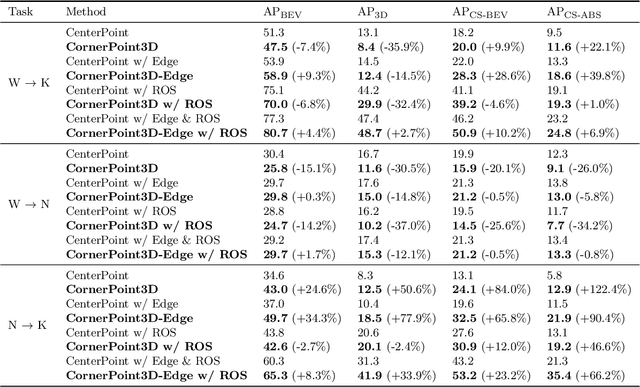
3D object detection aims to predict object centers, dimensions, and rotations from LiDAR point clouds. Despite its simplicity, LiDAR captures only the near side of objects, making center-based detectors prone to poor localization accuracy in cross-domain tasks with varying point distributions. Meanwhile, existing evaluation metrics designed for single-domain assessment also suffer from overfitting due to dataset-specific size variations. A key question arises: Do we really need models to maintain excellent performance in the entire 3D bounding boxes after being applied across domains? Actually, one of our main focuses is on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the sizes is much more difficult. To address these issues, we rethink cross-domain 3D object detection from a practical perspective. We propose two new metrics that evaluate a model's ability to detect objects' closer-surfaces to the LiDAR sensor. Additionally, we introduce EdgeHead, a refinement head that guides models to focus more on learnable closer surfaces, significantly improving cross-domain performance under both our new and traditional BEV/3D metrics. Furthermore, we argue that predicting the nearest corner rather than the object center enhances robustness. We propose a novel 3D object detector, coined as CornerPoint3D, which is built upon CenterPoint and uses heatmaps to supervise the learning and detection of the nearest corner of each object. Our proposed methods realize a balanced trade-off between the detection quality of entire bounding boxes and the locating accuracy of closer surfaces to the LiDAR sensor, outperforming the traditional center-based detector CenterPoint in multiple cross-domain tasks and providing a more practically reasonable and robust cross-domain 3D object detection solution.
Generative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.
Revisiting Cross-Domain Problem for LiDAR-based 3D Object Detection
Aug 22, 2024



Deep learning models such as convolutional neural networks and transformers have been widely applied to solve 3D object detection problems in the domain of autonomous driving. While existing models have achieved outstanding performance on most open benchmarks, the generalization ability of these deep networks is still in doubt. To adapt models to other domains including different cities, countries, and weather, retraining with the target domain data is currently necessary, which hinders the wide application of autonomous driving. In this paper, we deeply analyze the cross-domain performance of the state-of-the-art models. We observe that most models will overfit the training domains and it is challenging to adapt them to other domains directly. Existing domain adaptation methods for 3D object detection problems are actually shifting the models' knowledge domain instead of improving their generalization ability. We then propose additional evaluation metrics -- the side-view and front-view AP -- to better analyze the core issues of the methods' heavy drops in accuracy levels. By using the proposed metrics and further evaluating the cross-domain performance in each dimension, we conclude that the overfitting problem happens more obviously on the front-view surface and the width dimension which usually faces the sensor and has more 3D points surrounding it. Meanwhile, our experiments indicate that the density of the point cloud data also significantly influences the models' cross-domain performance.
Detect Closer Surfaces that can be Seen: New Modeling and Evaluation in Cross-domain 3D Object Detection
Jul 04, 2024



The performance of domain adaptation technologies has not yet reached an ideal level in the current 3D object detection field for autonomous driving, which is mainly due to significant differences in the size of vehicles, as well as the environments they operate in when applied across domains. These factors together hinder the effective transfer and application of knowledge learned from specific datasets. Since the existing evaluation metrics are initially designed for evaluation on a single domain by calculating the 2D or 3D overlap between the prediction and ground-truth bounding boxes, they often suffer from the overfitting problem caused by the size differences among datasets. This raises a fundamental question related to the evaluation of the 3D object detection models' cross-domain performance: Do we really need models to maintain excellent performance in their original 3D bounding boxes after being applied across domains? From a practical application perspective, one of our main focuses is actually on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the size of vehicles is much more difficult. In other words, as long as a model can accurately identify the closest surfaces to the ego vehicle, it is sufficient to effectively avoid obstacles. In this paper, we propose two metrics to measure 3D object detection models' ability of detecting the closer surfaces to the sensor on the ego vehicle, which can be used to evaluate their cross-domain performance more comprehensively and reasonably. Furthermore, we propose a refinement head, named EdgeHead, to guide models to focus more on the learnable closer surfaces, which can greatly improve the cross-domain performance of existing models not only under our new metrics, but even also under the original BEV/3D metrics.
Talk2Radar: Bridging Natural Language with 4D mmWave Radar for 3D Referring Expression Comprehension
May 21, 2024



Embodied perception is essential for intelligent vehicles and robots, enabling more natural interaction and task execution. However, these advancements currently embrace vision level, rarely focusing on using 3D modeling sensors, which limits the full understanding of surrounding objects with multi-granular characteristics. Recently, as a promising automotive sensor with affordable cost, 4D Millimeter-Wave radar provides denser point clouds than conventional radar and perceives both semantic and physical characteristics of objects, thus enhancing the reliability of perception system. To foster the development of natural language-driven context understanding in radar scenes for 3D grounding, we construct the first dataset, Talk2Radar, which bridges these two modalities for 3D Referring Expression Comprehension. Talk2Radar contains 8,682 referring prompt samples with 20,558 referred objects. Moreover, we propose a novel model, T-RadarNet for 3D REC upon point clouds, achieving state-of-the-art performances on Talk2Radar dataset compared with counterparts, where Deformable-FPN and Gated Graph Fusion are meticulously designed for efficient point cloud feature modeling and cross-modal fusion between radar and text features, respectively. Further, comprehensive experiments are conducted to give a deep insight into radar-based 3D REC. We release our project at https://github.com/GuanRunwei/Talk2Radar.