 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust TTS Training via Self-Purifying Flow Matching for the WildSpoof 2026 TTS Track
Dec 19, 2025

This paper presents a lightweight text-to-speech (TTS) system developed for the WildSpoof Challenge TTS Track. Our approach fine-tunes the recently released open-weight TTS model, \textit{Supertonic}\footnote{\url{https://github.com/supertone-inc/supertonic}}, with Self-Purifying Flow Matching (SPFM) to enable robust adaptation to in-the-wild speech. SPFM mitigates label noise by comparing conditional and unconditional flow matching losses on each sample, routing suspicious text--speech pairs to unconditional training while still leveraging their acoustic information. The resulting model achieves the lowest Word Error Rate (WER) among all participating teams, while ranking second in perceptual metrics such as UTMOS and DNSMOS. These findings demonstrate that efficient, open-weight architectures like Supertonic can be effectively adapted to diverse real-world speech conditions when combined with explicit noise-handling mechanisms such as SPFM.
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025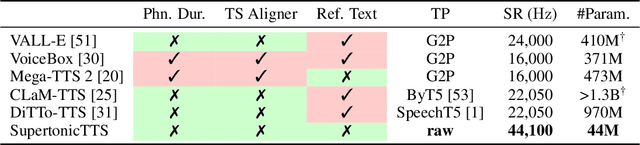
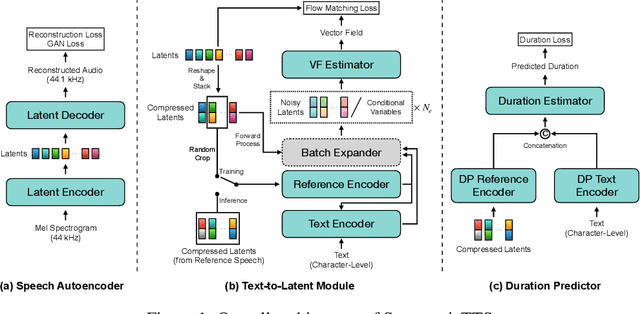

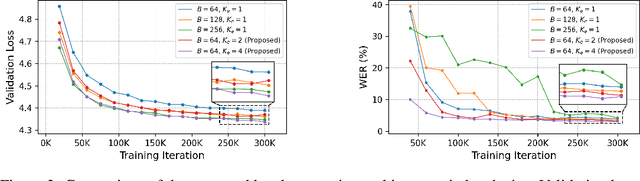
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
Aug 27, 2024


Text-to-Speech (TTS) models have advanced significantly, aiming to accurately replicate human speech's diversity, including unique speaker identities and linguistic nuances. Despite these advancements, achieving an optimal balance between speaker-fidelity and text-intelligibility remains a challenge, particularly when diverse control demands are considered. Addressing this, we introduce DualSpeech, a TTS model that integrates phoneme-level latent diffusion with dual classifier-free guidance. This approach enables exceptional control over speaker-fidelity and text-intelligibility. Experimental results demonstrate that by utilizing the sophisticated control, DualSpeech surpasses existing state-of-the-art TTS models in performance. Demos are available at https://bit.ly/48Ewoib.
Revisiting Cross-Domain Problem for LiDAR-based 3D Object Detection
Aug 22, 2024



Deep learning models such as convolutional neural networks and transformers have been widely applied to solve 3D object detection problems in the domain of autonomous driving. While existing models have achieved outstanding performance on most open benchmarks, the generalization ability of these deep networks is still in doubt. To adapt models to other domains including different cities, countries, and weather, retraining with the target domain data is currently necessary, which hinders the wide application of autonomous driving. In this paper, we deeply analyze the cross-domain performance of the state-of-the-art models. We observe that most models will overfit the training domains and it is challenging to adapt them to other domains directly. Existing domain adaptation methods for 3D object detection problems are actually shifting the models' knowledge domain instead of improving their generalization ability. We then propose additional evaluation metrics -- the side-view and front-view AP -- to better analyze the core issues of the methods' heavy drops in accuracy levels. By using the proposed metrics and further evaluating the cross-domain performance in each dimension, we conclude that the overfitting problem happens more obviously on the front-view surface and the width dimension which usually faces the sensor and has more 3D points surrounding it. Meanwhile, our experiments indicate that the density of the point cloud data also significantly influences the models' cross-domain performance.
Neural varifolds: an aggregate representation for quantifying the geometry of point clouds
Jul 05, 2024Point clouds are popular 3D representations for real-life objects (such as in LiDAR and Kinect) due to their detailed and compact representation of surface-based geometry. Recent approaches characterise the geometry of point clouds by bringing deep learning based techniques together with geometric fidelity metrics such as optimal transportation costs (e.g., Chamfer and Wasserstein metrics). In this paper, we propose a new surface geometry characterisation within this realm, namely a neural varifold representation of point clouds. Here the surface is represented as a measure/distribution over both point positions and tangent spaces of point clouds. The varifold representation quantifies not only the surface geometry of point clouds through the manifold-based discrimination, but also subtle geometric consistencies on the surface due to the combined product space. This study proposes neural varifold algorithms to compute the varifold norm between two point clouds using neural networks on point clouds and their neural tangent kernel representations. The proposed neural varifold is evaluated on three different sought-after tasks -- shape matching, few-shot shape classification and shape reconstruction. Detailed evaluation and comparison to the state-of-the-art methods demonstrate that the proposed versatile neural varifold is superior in shape matching and few-shot shape classification, and is competitive for shape reconstruction.
Detect Closer Surfaces that can be Seen: New Modeling and Evaluation in Cross-domain 3D Object Detection
Jul 04, 2024



The performance of domain adaptation technologies has not yet reached an ideal level in the current 3D object detection field for autonomous driving, which is mainly due to significant differences in the size of vehicles, as well as the environments they operate in when applied across domains. These factors together hinder the effective transfer and application of knowledge learned from specific datasets. Since the existing evaluation metrics are initially designed for evaluation on a single domain by calculating the 2D or 3D overlap between the prediction and ground-truth bounding boxes, they often suffer from the overfitting problem caused by the size differences among datasets. This raises a fundamental question related to the evaluation of the 3D object detection models' cross-domain performance: Do we really need models to maintain excellent performance in their original 3D bounding boxes after being applied across domains? From a practical application perspective, one of our main focuses is actually on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the size of vehicles is much more difficult. In other words, as long as a model can accurately identify the closest surfaces to the ego vehicle, it is sufficient to effectively avoid obstacles. In this paper, we propose two metrics to measure 3D object detection models' ability of detecting the closer surfaces to the sensor on the ego vehicle, which can be used to evaluate their cross-domain performance more comprehensively and reasonably. Furthermore, we propose a refinement head, named EdgeHead, to guide models to focus more on the learnable closer surfaces, which can greatly improve the cross-domain performance of existing models not only under our new metrics, but even also under the original BEV/3D metrics.
Virtual Foundry Graphnet for Metal Sintering Deformation Prediction
Apr 17, 2024



Metal Sintering is a necessary step for Metal Injection Molded parts and binder jet such as HP's metal 3D printer. The metal sintering process introduces large deformation varying from 25 to 50% depending on the green part porosity. In this paper, we use a graph-based deep learning approach to predict the part deformation, which can speed up the deformation simulation substantially at the voxel level. Running a well-trained Metal Sintering inferencing engine only takes a range of seconds to obtain the final sintering deformation value. The tested accuracy on example complex geometry achieves 0.7um mean deviation for a 63mm testing part.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
Continuous Emotional Intensity Controllable Speech Synthesis using Semi-supervised Learning
Nov 11, 2022With the rapid development of the speech synthesis system, recent text-to-speech models have reached the level of generating natural speech similar to what humans say. But there still have limitations in terms of expressiveness. In particular, the existing emotional speech synthesis models have shown controllability using interpolated features with scaling parameters in emotional latent space. However, the emotional latent space generated from the existing models is difficult to control the continuous emotional intensity because of the entanglement of features like emotions, speakers, etc. In this paper, we propose a novel method to control the continuous intensity of emotions using semi-supervised learning. The model learns emotions of intermediate intensity using pseudo-labels generated from phoneme-level sequences of speech information. An embedding space built from the proposed model satisfies the uniform grid geometry with an emotional basis. In addition, to improve the naturalness of intermediate emotional speech, a discriminator is applied to the generation of low-level elements like duration, pitch and energy. The experimental results showed that the proposed method was superior in controllability and naturalness. The synthesized speech samples are available at https://tinyurl.com/34zaehh2
Expressive Singing Synthesis Using Local Style Token and Dual-path Pitch Encoder
Apr 07, 2022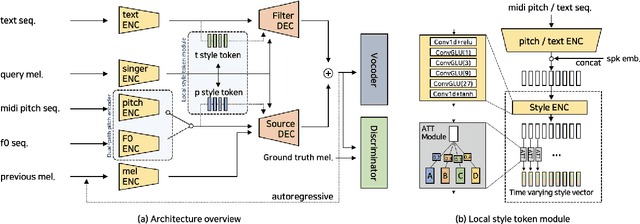
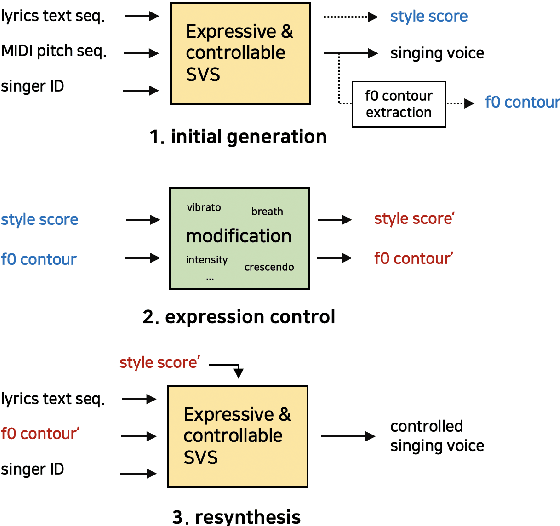
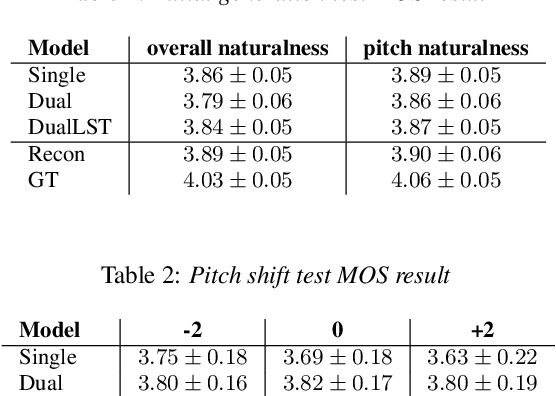
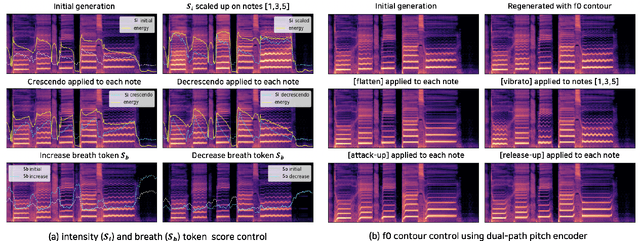
This paper proposes a controllable singing voice synthesis system capable of generating expressive singing voice with two novel methodologies. First, a local style token module, which predicts frame-level style tokens from an input pitch and text sequence, is proposed to allow the singing voice system to control musical expression often unspecified in sheet music (e.g., breathing and intensity). Second, we propose a dual-path pitch encoder with a choice of two different pitch inputs: MIDI pitch sequence or f0 contour. Because the initial generation of a singing voice is usually executed by taking a MIDI pitch sequence, one can later extract an f0 contour from the generated singing voice and modify the f0 contour to a finer level as desired. Through quantitative and qualitative evaluations, we confirmed that the proposed model could control various musical expressions while not sacrificing the sound quality of the singing voice synthesis system.