 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustSpeechFlow: Learning Robust Text-to-Speech Trajectories via Augmentation-based Contrastive Flow Matching
May 21, 2026While flow-matching text-to-speech (TTS) achieves strong zero-shot speaker similarity and naturalness, it remains susceptible to content fidelity issues, particularly skip and repeat errors from imperfect alignment. We propose RobustSpeechFlow, a training strategy that improves alignment robustness by extending contrastive flow matching with length-preserving repeat and skip latent augmentations. Requiring no external aligners or preference data, our method directly penalizes realistic failure modes and readily integrates into existing pipelines. On Seed-TTS-eval, it reduces the word error rate (WER) from 1.44 to 1.38 using only 0.06B parameters. On our ZERO500 benchmark, it delivers consistent intelligibility improvements across diverse speaker and prosody conditions; at NFE=24, it reduces English character error rate (CER) from 0.48\% to 0.35\% and Korean CER from 0.81\% to 0.57\%. Audio samples: https://robustspeechflow.github.io/
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025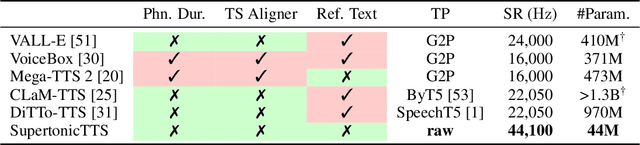
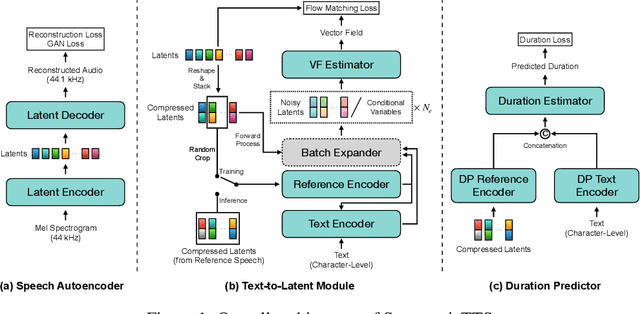

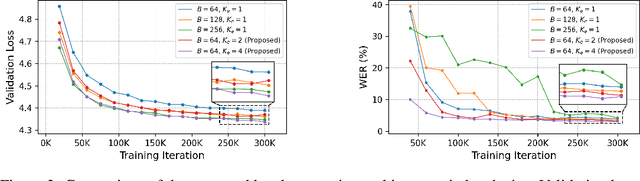
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
VaSAB: The variable size adaptive information bottleneck for disentanglement on speech and singing voice
Oct 05, 2023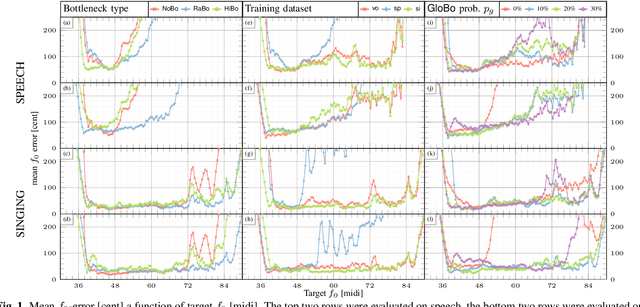
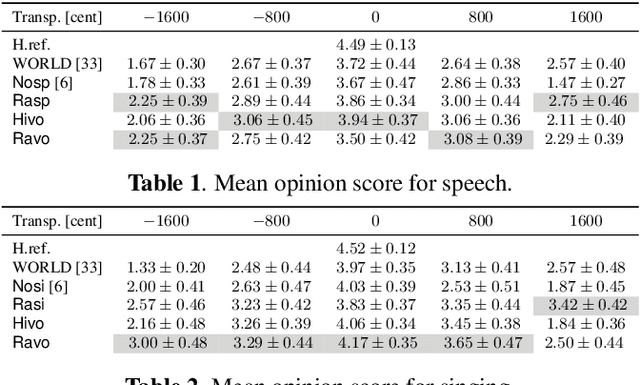
The information bottleneck auto-encoder is a tool for disentanglement commonly used for voice transformation. The successful disentanglement relies on the right choice of bottleneck size. Previous bottleneck auto-encoders created the bottleneck by the dimension of the latent space or through vector quantization and had no means to change the bottleneck size of a specific model. As the bottleneck removes information from the disentangled representation, the choice of bottleneck size is a trade-off between disentanglement and synthesis quality. We propose to build the information bottleneck using dropout which allows us to change the bottleneck through the dropout rate and investigate adapting the bottleneck size depending on the context. We experimentally explore into using the adaptive bottleneck for pitch transformation and demonstrate that the adaptive bottleneck leads to improved disentanglement of the F0 parameter for both, speech and singing voice leading to improved synthesis quality. Using the variable bottleneck size, we were able to achieve disentanglement for singing voice including extremely high pitches and create a universal voice model, that works on both speech and singing voice with improved synthesis quality.
Analysis and transformations of intensity in singing voice
Apr 08, 2022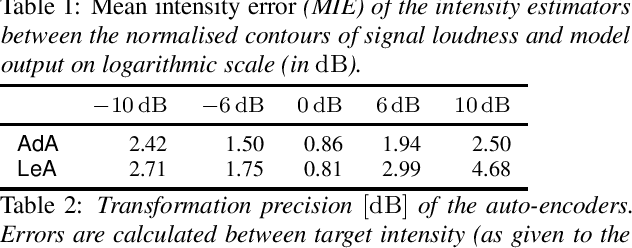

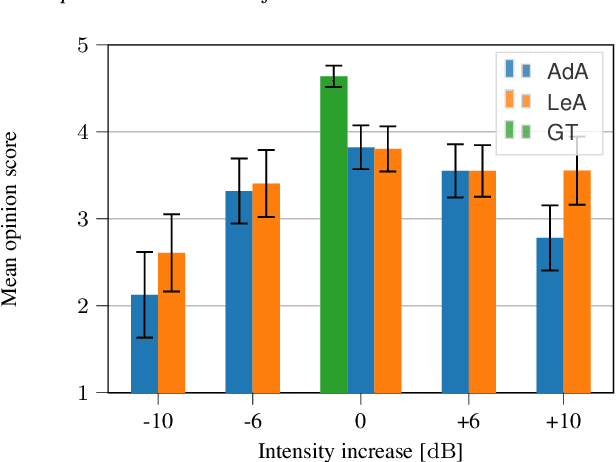

In this paper we introduce a neural auto-encoder that transforms the voice intensity in recordings of singing voice. Since most recordings of singing voice are not annotated with voice intensity we propose a means to estimate the relative voice intensity from the signal's timbre using a neural intensity estimator. Two methods to overcome the unknown recording factor that relates voice intensity to recorded signal power are given: The unknown recording factor can either be learned alongside the weights of the intensity estimator, or a special loss function based on the scalar product can be used to only match the intensity contour of the recorded signal's power. The intensity models are used to condition a previously introduced bottleneck auto-encoder that disentangles its input, the mel-spectrogram, from the intensity. We evaluate the intensity models by their consistency and by their fitness to provide useful information to the auto-encoder. A perceptive test is carried out that evaluates the perceived intensity change in transformed recordings and the synthesis quality. The perceptive test confirms that changing the conditional input changes the perceived intensity accordingly thus suggesting that the proposed intensity models encode information about the voice intensity.
Sequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021
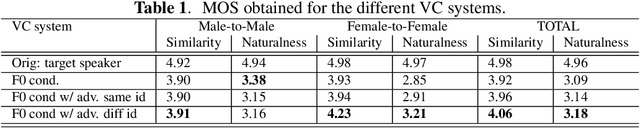
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.
Towards Universal Neural Vocoding with a Multi-band Excited WaveNet
Oct 07, 2021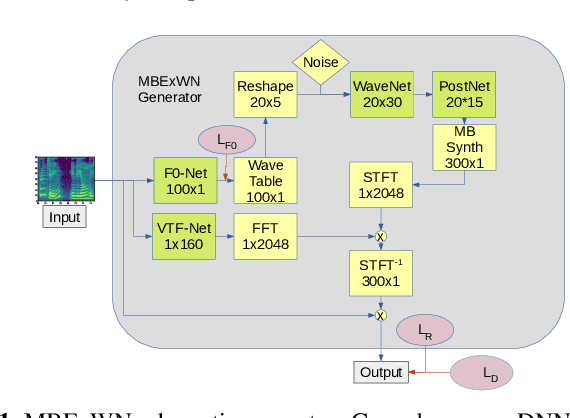
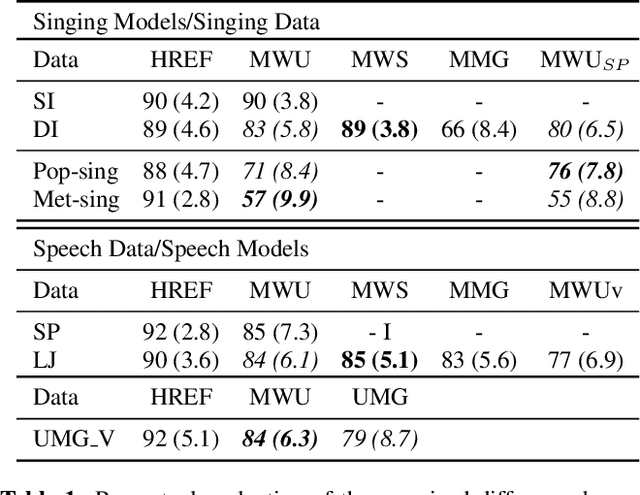
This paper introduces the Multi-Band Excited WaveNet a neural vocoder for speaking and singing voices. It aims to advance the state of the art towards an universal neural vocoder, which is a model that can generate voice signals from arbitrary mel spectrograms extracted from voice signals. Following the success of the DDSP model and following the development of the recently proposed excitation vocoders we propose a vocoder structure consisting of multiple specialized DNN that are combined with dedicated signal processing components. All components are implemented as differentiable operators and therefore allow joined optimization of the model parameters. To prove the capacity of the model to reproduce high quality voice signals we evaluate the model on single and multi speaker/singer datasets. We conduct a subjective evaluation demonstrating that the models support a wide range of domain variations (unseen voices, languages, expressivity) achieving perceptive quality that compares with a state of the art universal neural vocoder, however using significantly smaller training datasets and significantly less parameters. We also demonstrate remaining limits of the universality of neural vocoders e.g. the creation of saturated singing voices.