 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustSpeechFlow: Learning Robust Text-to-Speech Trajectories via Augmentation-based Contrastive Flow Matching
May 21, 2026While flow-matching text-to-speech (TTS) achieves strong zero-shot speaker similarity and naturalness, it remains susceptible to content fidelity issues, particularly skip and repeat errors from imperfect alignment. We propose RobustSpeechFlow, a training strategy that improves alignment robustness by extending contrastive flow matching with length-preserving repeat and skip latent augmentations. Requiring no external aligners or preference data, our method directly penalizes realistic failure modes and readily integrates into existing pipelines. On Seed-TTS-eval, it reduces the word error rate (WER) from 1.44 to 1.38 using only 0.06B parameters. On our ZERO500 benchmark, it delivers consistent intelligibility improvements across diverse speaker and prosody conditions; at NFE=24, it reduces English character error rate (CER) from 0.48\% to 0.35\% and Korean CER from 0.81\% to 0.57\%. Audio samples: https://robustspeechflow.github.io/
Robust TTS Training via Self-Purifying Flow Matching for the WildSpoof 2026 TTS Track
Dec 19, 2025

This paper presents a lightweight text-to-speech (TTS) system developed for the WildSpoof Challenge TTS Track. Our approach fine-tunes the recently released open-weight TTS model, \textit{Supertonic}\footnote{\url{https://github.com/supertone-inc/supertonic}}, with Self-Purifying Flow Matching (SPFM) to enable robust adaptation to in-the-wild speech. SPFM mitigates label noise by comparing conditional and unconditional flow matching losses on each sample, routing suspicious text--speech pairs to unconditional training while still leveraging their acoustic information. The resulting model achieves the lowest Word Error Rate (WER) among all participating teams, while ranking second in perceptual metrics such as UTMOS and DNSMOS. These findings demonstrate that efficient, open-weight architectures like Supertonic can be effectively adapted to diverse real-world speech conditions when combined with explicit noise-handling mechanisms such as SPFM.
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025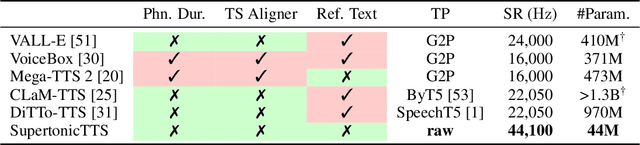
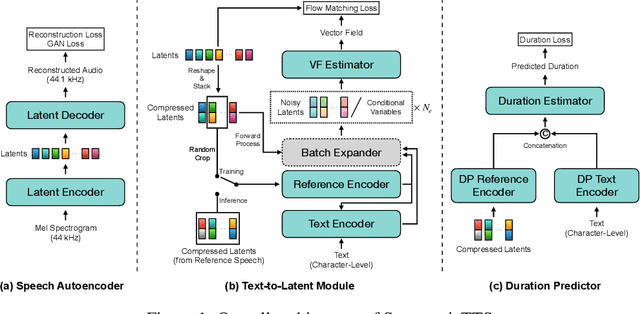

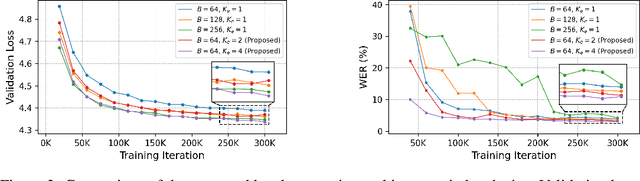
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
Super Monotonic Alignment Search
Sep 12, 2024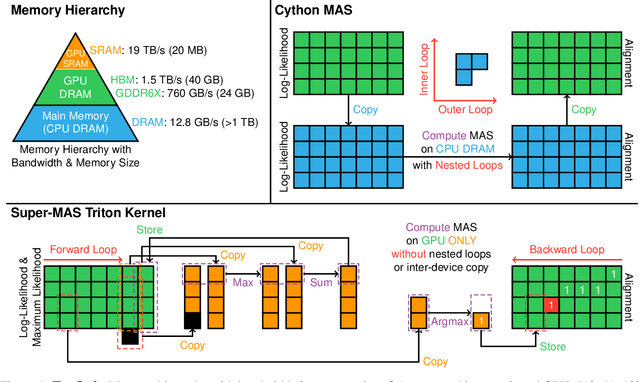
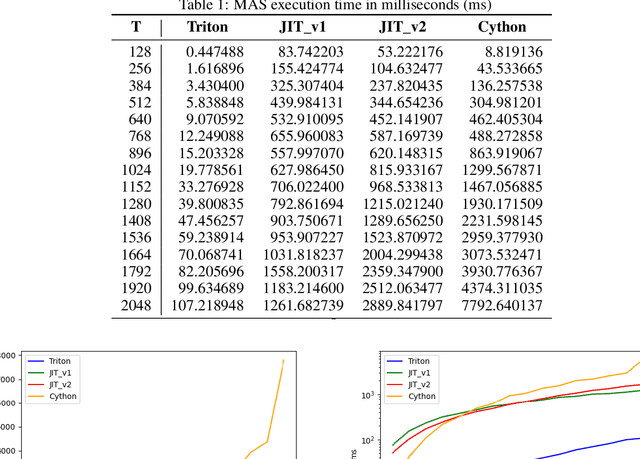
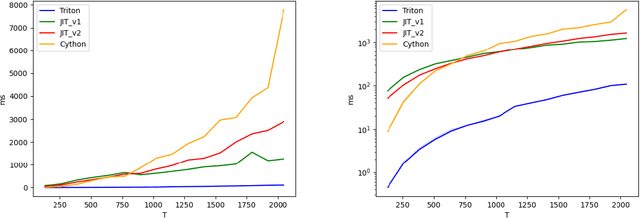
Monotonic alignment search (MAS), introduced by Glow-TTS, is one of the most popular algorithm in TTS to estimate unknown alignments between text and speech. Since this algorithm needs to search for the most probable alignment with dynamic programming by caching all paths, the time complexity of the algorithm is $O(T \times S)$. The authors of Glow-TTS run this algorithm on CPU, and while they mentioned it is difficult to parallelize, we found that MAS can be parallelized in text-length dimension and CPU execution consumes an inordinate amount of time for inter-device copy. Therefore, we implemented a Triton kernel and PyTorch JIT script to accelerate MAS on GPU without inter-device copy. As a result, Super-MAS Triton kernel is up to 72 times faster in the extreme-length case. The code is available at \url{https://github.com/supertone-inc/super-monotonic-align}.
DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
Aug 27, 2024


Text-to-Speech (TTS) models have advanced significantly, aiming to accurately replicate human speech's diversity, including unique speaker identities and linguistic nuances. Despite these advancements, achieving an optimal balance between speaker-fidelity and text-intelligibility remains a challenge, particularly when diverse control demands are considered. Addressing this, we introduce DualSpeech, a TTS model that integrates phoneme-level latent diffusion with dual classifier-free guidance. This approach enables exceptional control over speaker-fidelity and text-intelligibility. Experimental results demonstrate that by utilizing the sophisticated control, DualSpeech surpasses existing state-of-the-art TTS models in performance. Demos are available at https://bit.ly/48Ewoib.
Towards trustworthy phoneme boundary detection with autoregressive model and improved evaluation metric
Dec 13, 2022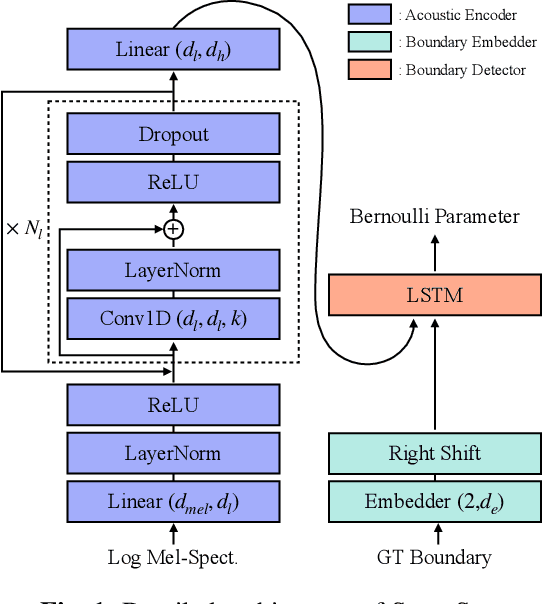



Phoneme boundary detection has been studied due to its central role in various speech applications. In this work, we point out that this task needs to be addressed not only by algorithmic way, but also by evaluation metric. To this end, we first propose a state-of-the-art phoneme boundary detector that operates in an autoregressive manner, dubbed SuperSeg. Experiments on the TIMIT and Buckeye corpora demonstrates that SuperSeg identifies phoneme boundaries with significant margin compared to existing models. Furthermore, we note that there is a limitation on the popular evaluation metric, R-value, and propose new evaluation metrics that prevent each boundary from contributing to evaluation multiple times. The proposed metrics reveal the weaknesses of non-autoregressive baselines and establishes a reliable criterion that suits for evaluating phoneme boundary detection.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Oct 06, 2021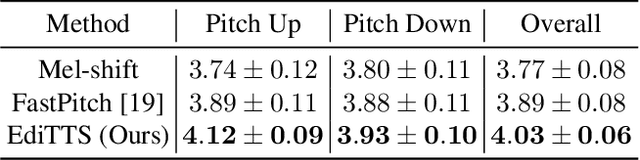
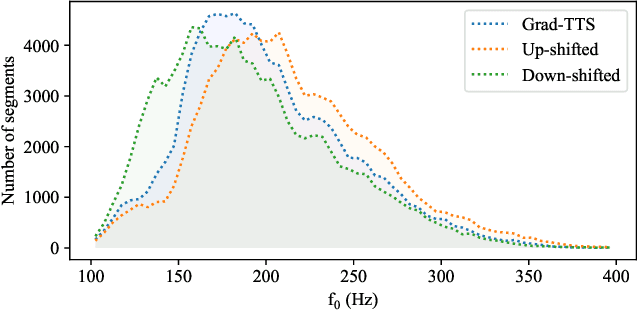
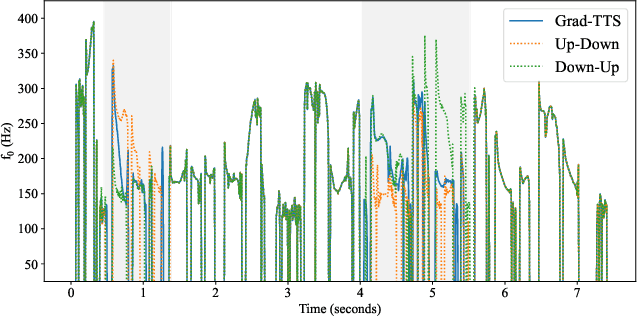
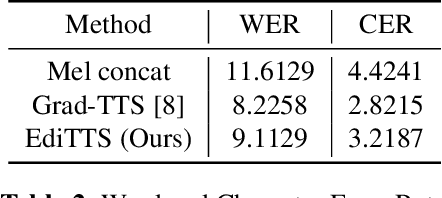
We present EdiTTS, an off-the-shelf speech editing methodology based on score-based generative modeling for text-to-speech synthesis. EdiTTS allows for targeted, granular editing of audio, both in terms of content and pitch, without the need for any additional training, task-specific optimization, or architectural modifications to the score-based model backbone. Specifically, we apply coarse yet deliberate perturbations in the Gaussian prior space to induce desired behavior from the diffusion model, while applying masks and softening kernels to ensure that iterative edits are applied only to the target region. Listening tests demonstrate that EdiTTS is capable of reliably generating natural-sounding audio that satisfies user-imposed requirements.
Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
Apr 03, 2021

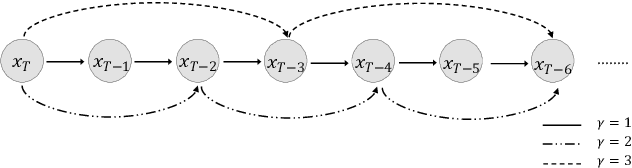
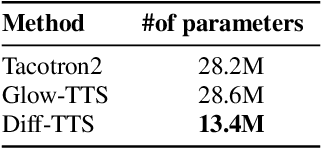
Although neural text-to-speech (TTS) models have attracted a lot of attention and succeeded in generating human-like speech, there is still room for improvements to its naturalness and architectural efficiency. In this work, we propose a novel non-autoregressive TTS model, namely Diff-TTS, which achieves highly natural and efficient speech synthesis. Given the text, Diff-TTS exploits a denoising diffusion framework to transform the noise signal into a mel-spectrogram via diffusion time steps. In order to learn the mel-spectrogram distribution conditioned on the text, we present a likelihood-based optimization method for TTS. Furthermore, to boost up the inference speed, we leverage the accelerated sampling method that allows Diff-TTS to generate raw waveforms much faster without significantly degrading perceptual quality. Through experiments, we verified that Diff-TTS generates 28 times faster than the real-time with a single NVIDIA 2080Ti GPU.
Continuous Monitoring of Blood Pressure with Evidential Regression
Feb 26, 2021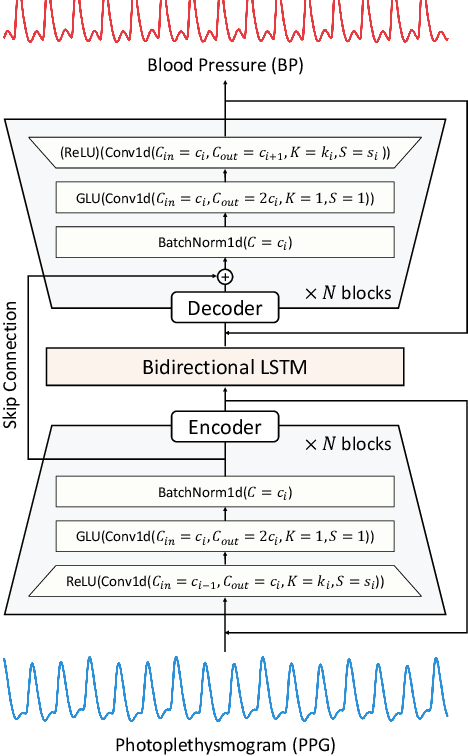
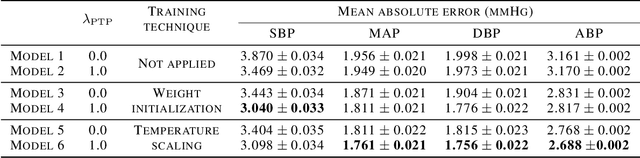
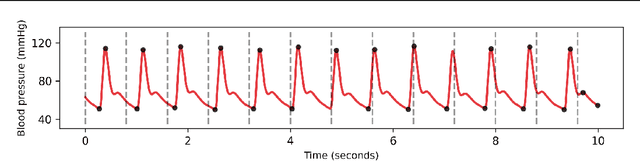
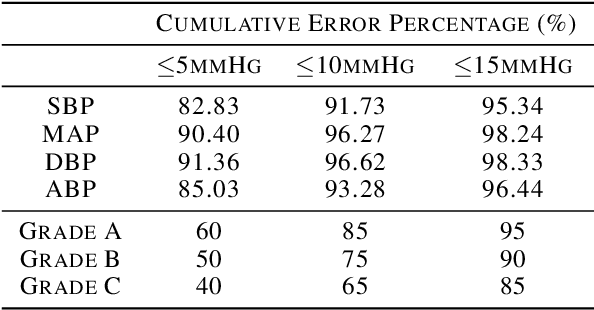
Photoplethysmogram (PPG) signal-based blood pressure (BP) estimation is a promising candidate for modern BP measurements, as PPG signals can be easily obtained from wearable devices in a non-invasive manner, allowing quick BP measurement. However, the performance of existing machine learning-based BP measuring methods still fall behind some BP measurement guidelines and most of them provide only point estimates of systolic blood pressure (SBP) and diastolic blood pressure (DBP). In this paper, we present a cutting-edge method which is capable of continuously monitoring BP from the PPG signal and satisfies healthcare criteria such as the Association for the Advancement of Medical Instrumentation (AAMI) and the British Hypertension Society (BHS) standards. Furthermore, the proposed method provides the reliability of the predicted BP by estimating its uncertainty to help diagnose medical condition based on the model prediction. Experiments on the MIMIC II database verify the state-of-the-art performance of the proposed method under several metrics and its ability to accurately represent uncertainty in prediction.